Machine Learning thật thú vị (3): Tìm kiếm ảnh chứa chim với CNN
Bài đăng này đã không được cập nhật trong 4 năm
Liệu bạn đã chán ngấy đọc những câu chuyện về deep learning (học sâu) và không rõ chính xác nó là gì? Hãy cùng nhau làm rõ trong bài này.
Chúng ta cùng nhau viết chương trình có thể nhận diện vật thể từ những bức ảnh sử dụng deep learning và giải thích bí mật mà Google Photos tìm kiếm ảnh dựa trên nội dung.

Nhận diện vật thể cùng Deep Learning

Dịch: "Khi người sử dụng chụp ảnh, ứng dụng của chúng ta cần biết được liệu chúng ta đang ở trong công viên quốc gia không" "Đơn giản thôi, để tôi xác định GIS. Đợi tôi vài tiếng" "Và kiểm tra xem bức ảnh có phải là ảnh của một con chim" "Tôi cần một đôi nghiên cứu và 5 năm"
Bạn có thể đã từng nhìn thấy đoạn hoạt hình nổi tiếng này trước đây. Bức tranh mô tả ý tưởng: bất kỳ một đứa trẻ 3 tuổi nào cũng có thể nhận ra bức tranh của một chú chim, nhưng để nhận dạng vật thể với máy tính là một câu đố cho những nhà khoa học máy tính giỏi nhất trong vòng 50 năm vừa qua.
Trong khoảng vài năm gần đây, cuối cùng, chúng ta cũng đã tìm được một phương pháp thích hợp để nhận dạng vật thể sử dụng Deep Convolutional Neural Networks - mạng nơron tích chập đa lớp. Để hiểu hơn về thuật toán này, hãy cùng nhau viết chương trình nhận dạng chim từ ảnh.
Bắt đầu từ đơn giản
Trước khi chúng ta học cách nhận diện chim, hãy cùng nhau nhận diện số 8 trong chữ số viết tay - một chương trình đơn giản hơn.
Trong phần 2, chúng ta đã biết mạng nơron giải quyết các vấn đề phức tạp bằng cách kết nối nhiều nơron đơn giản. Chúng ta có thể tạo ra mạng nơron nhỏ, để dự đoán giá nhà dựa trên số phòng ngủ nó có, độ rộng ngôi nhà, hay hàng xóm của ngôi nhà
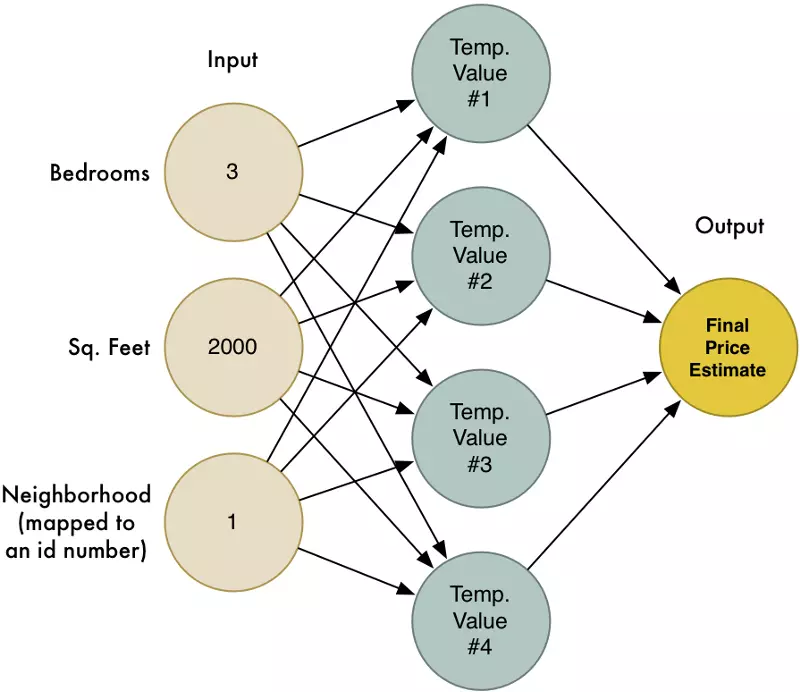
Chúng ta cũng biết ý tưởng của học máy là tái sử dụng các thuật toán với dữ liệu khác nhau để giải quyết các vấn đề khác nhau. Vì thế, hãy thay đổi mạng nơron này để nhận diện ký tự viết tay, và một trường hợp đơn giản là nhận diện số 8.
Học máy chỉ chạy khi bạn có dữ liệu, càng nhiều càng tốt. Vì thế, chúng ta cần rất nhiều số 8 viết tay để bắt đầu. May mắn là những nhà nghiên cứu đã tạo ra tập chữ viết tay MNIST cho mục đích này. MNIST cung cấp 60,000 ảnh với mỗi ảnh 18x18 pixel. Dưới đây là tập số 8 từ dữ liệu:

Mọi đặc trưng đều là số
Mạng nơron chúng ta tạo ở phần 2 chỉ lấy 3 giá trị đầu vào như ("3" phòng ngủ, "2000" diện tích ...). Nhưng nếu chúng ta muốn xử lý dữ liệu bằng mạng nơron, làm cách nào chúng ta có thể truyền hình ảnh vào mạng?
Câu trả lời hóa ra cực kỳ đơn giản. Dữ liệu đầu vào mà mạng nơron cần là số. Đối với máy tính, tấm ảnh thực sự chỉ là mạng lưới với mỗi số sẽ đại diện cho vùng tối của mỗi pixel:

Để truyền ảnh vào mạng nơron, chúng ta chỉ cần coi 18x18 pixel ảnh là một mảng gồm 324 số:

Để xử lý 324 điểm ảnh, chúng ta cần mở rộng mô hình mạng nơron với 324 nơron đầu vào
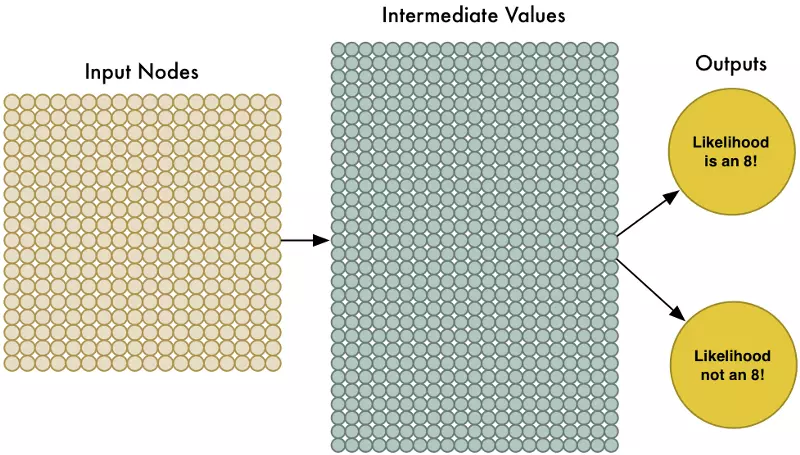
Chú ý rằng mạng nơron của chúng ta cũng có 2 giá trị đầu ra (thay vì chỉ một). Đầu ra thứ nhất sẽ sự đoán khả năng một ảnh là số 8 và đầu ra thứ 2 sẽ dự đoán một ảnh không phải số 8. Bằng việc phân tách đầu ra cho từng vật thể ta muốn nhận dạng, chúng ta có thể sử dụng mạng nơron để phân nhóm vật thể.
Mạng nơron hiện giờ đã lớn hơn rất nhiều so với lần trước đây (324 giá trị đầu vào thay vì chỉ 3). Nhưng bất kể máy tính hiện đại nào cũng có thể xử lý mạng nơron cùng với hàng trăm nơron một cách liên tục.
Đây là tập dữ liệu đào tạo:

Quá trình đào tạo có thể kéo dài vài phút trên laptop. Khi quá trình kết thúc, mạng nơron có thể nhận ra số 8 với độ chính xác khá cao.
Nhận diện hình ảnh
Thật hay là chỉ cần truyền giá trị pixel vào trong mạng nơron để có thể nhận diện hình ảnh! Machine Learning thật là thần kỳ phải không mọi người...
Nhưng mọi chuyện không đơn giản như vậy.
Đầu tiên, tin tốt là nhận diện số 8 thực sự hoạt động rất tốt trong những bức ảnh đơn giản, khi mà ký tự nằm ở chính giữa:
 Nhưng tin xấu là: việc nhận diện số 8 thất bại hoàn toàn khi mà ảnh bị lệch sang một phía. Chỉ cần lệch 1 chút thôi cũng đủ để phá vỡ hệ thống:
Nhưng tin xấu là: việc nhận diện số 8 thất bại hoàn toàn khi mà ảnh bị lệch sang một phía. Chỉ cần lệch 1 chút thôi cũng đủ để phá vỡ hệ thống:
 Điều này bởi vì, dữ liệu đào tạo có tất cả các số 8 đều nằm chính giữa, và mạng nơron không có bất kỳ ý tưởng nào về việc số 8 bị lệch. Mạng nơron biết một và chỉ một cấu trúc đó mà thôi.
Điều này bởi vì, dữ liệu đào tạo có tất cả các số 8 đều nằm chính giữa, và mạng nơron không có bất kỳ ý tưởng nào về việc số 8 bị lệch. Mạng nơron biết một và chỉ một cấu trúc đó mà thôi.
Việc nhận diện một cấu trúc thực sự không hữu hiệu trong thực tế. Vấn đề thực tế không bao giờ đơn giản và tinh gọn, vì thế chúng ta cần tìm ra cách để khiến mạng nơron nhận diện bất cứ số 8 không hoàn hảo nào.
Ý tưởng khiên cưỡng 1: Tìm kiếm với cửa sổ trượt (Sliding Window)
Chúng ta tạo ra một chương trình tìm kiếm số 8 nằm chính giữa. Liệu chúng ta có thể quét tất cả các ảnh số 8 có thể ở những vùng nhỏ hơn, từng vùng một, cho tới khi chúng ta tìm ra?
 Phương pháp này được gọi là tìm kiếm với cửa số trượt. Đây là một giải pháp khiên cưỡng. Nó chỉ đúng trong một số trường hợp giới hạn nhất định, nhưng không thực sự hiệu quả. Bạn phải kiểm tra cùng một bước ảnh lặp đi lặp lại với các kích thước khác nhau. Và chắc chắn, chúng ta có thể làm tốt hơn điều đó.
Phương pháp này được gọi là tìm kiếm với cửa số trượt. Đây là một giải pháp khiên cưỡng. Nó chỉ đúng trong một số trường hợp giới hạn nhất định, nhưng không thực sự hiệu quả. Bạn phải kiểm tra cùng một bước ảnh lặp đi lặp lại với các kích thước khác nhau. Và chắc chắn, chúng ta có thể làm tốt hơn điều đó.
Ý tưởng khiên cưỡng 2: Nhiều dữ liệu hơn với một mạng lưới nhiều lớp
Khi chúng ta đào tạo mạng, dữ liệu hiển thị số 8 nằm ở vị trí chính giữa. Liệu chúng ta có thể đào tạo với nhiều dữ liệu hơn, bao gồm số 8 ở tất cả các vị trí và các kích thước khác nhau.
Chúng ta thậm chí không cần thu thập thêm dữ liệu mới, ta chỉ cần viết một đoạn mã để tạo ra những hình ảnh mới từ ảnh số 8 ban đầu với đầy đủ các vị trí và kích thước khác nhau.

Sử dụng kĩ thuật này, chúng ta có thể dễ dàng tạo ra nguồn dữ liệu vô tận.
Nhiều dữ liệu khiến vấn đề khó hơn cho mạng nơron để giải quyết, nhưng chúng ta có thể mở rộng mạng luới bằng cách thêm nhiều lớp nơron, giúp mạng học được những cấu trúc phức tạp hơn.
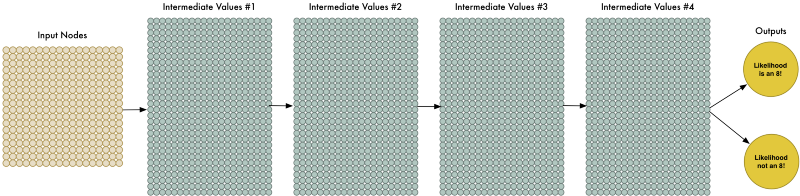 Chúng ta gọi đây là deep neural network (mạng nơron đa lớp), bởi vì nó chứa nhiều lớp nơron hơn mạng truyền thống.
Chúng ta gọi đây là deep neural network (mạng nơron đa lớp), bởi vì nó chứa nhiều lớp nơron hơn mạng truyền thống.
Ý tưởng này bắt đầu từ cuối nắm 1960s. Nhưng đến gầy đây, việc đào tạo mạng lưới lớn và phức tạp vẫn quá chậm để hữu ích do tính toán quá chậm. Khi chúng ta tìm ra thẻ đồ hoạ 3D (cho phép tính toán ma trận phức tạp cực nhanh), ứng dụng mạng nơron đa lớp trở lên thiết thực hơn.
Việc sử dụng nhiều dữ liệu hơn với mạng nơron lớn hơn có thể tạo ra mạng nơron tốt hơn, nhưng đó vẫn không phải là giải pháp bền vững. Chúng ta không thể coi số 8 ở góc trên và số 8 ở góc dưới là 2 nhóm dữ liệu hoàn toàn độc lập và đều cần bộ đào tạo tương tự nhau.
Mạng Convolutional Neural Network - (CNN - mạng nơron tích chập), giải pháp cho tìm kiếm ảnh
Con người có cảm quan để biết rằng bức ảnh có tầng lớp hoặc cấu trúc từng vật thể. Hãy nghĩ về bức ảnh sau:
 Bạn có thể ngay lập tức nhận ra cấu trúc bức ảnh:
Bạn có thể ngay lập tức nhận ra cấu trúc bức ảnh:
- Có một đứa trẻ
- Đứa trẻ ngồi trên con ngựa nẩy
- Con ngựa nẩy nằm trên mặt cỏ
- Mặt cỏ phủ trên mặt sân
Và quan trọng nhất là, chúng ta nhận diện được đứa trẻ ở bất cứ địa điểm nào, dù chúng ta không được đào tạo cách nhận diện đứa trẻ ở mọi địa điểm tồn tại trên trái đất.
Nhưng mạng nơron hiện tại của chúng ta lại không thể làm điều đó. Nó nghĩ số 8 ở vị trí khác nhau là hoàn toàn khác biệt. Nó không hiểu rằng việc di chuyển vật thể xung quanh bức ảnh không tạo ra sự sai khác. Chúng ta cần tạo ra một mạng nơron có thể hiểu được biến thể của số 8, dù số 8 xuất hiện ở vị trí nào đi chăng nữa.
Ý tưởng mạng nơron tích chập ra đời, nhờ công nghiên cứu của cả các nhà khoa học máy tính và những nhà di truyền học. Thực tế, một số nhà khoa học đã truyền dung dịch vào não bộ của mèo để xem mèo nhận diện hình ảnh như thế nào.
Mạng CNN hoạt động như thế nào?
Thay vì truyền vào toàn bộ bức ảnh (vật thể bị dính chặt với khung nền), chúng ta bắt đầu với ý tưởng: một vật thể là giống nhau dù nó ở vị trí nào trong bức ảnh, và chia bức ảnh thành một mạng lưới
Bước 1: Tách bức ảnh thành các mảnh chồng chéo
Giống như cửa sổ trượt phía trên, hãy quét cửa sổ trượt trên toàn bộ bức ảnh gốc và lưu giữ kết quả theo từng mảnh ảnh.
 Bằng cách làm này, chúng ta đã chuyển bức ảnh ban đầu thành 77 mảnh ảnh nhỏ cùng kích cỡ
Bằng cách làm này, chúng ta đã chuyển bức ảnh ban đầu thành 77 mảnh ảnh nhỏ cùng kích cỡ
Bước 2: Truyền mỗi mảnh ảnh vào mạng nơron nhỏ
Trước đây, chúng ta truyền 1 ảnh duy nhất vào mạng nơron để tìm kiếm số 8. Chúng ta lặp lại quá trình đó, nhưng cho mỗi mảnh ảnh
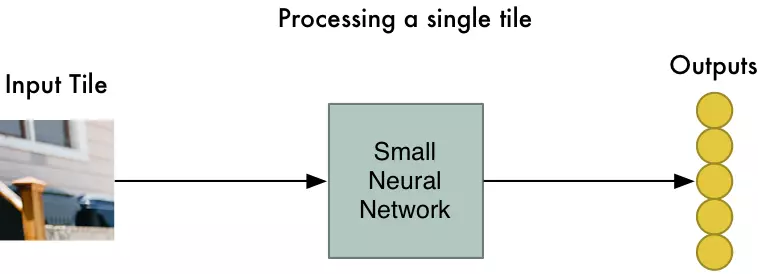 Chúng ta sử dụng cùng trọng số mạng nơron cho tất cả các mảnh ảnh để lấy dữ liệu đầu ra.
Chúng ta sử dụng cùng trọng số mạng nơron cho tất cả các mảnh ảnh để lấy dữ liệu đầu ra.
Vì có cùng trọng số, mà đầu vào khác nhau nên đầu ra khác nhau. Mục đích của phần này là tìm kiếm những phần nhỏ đặc biệt của bức ảnh.
Trong một bức ảnh lớn, ta không thể tìm ra đứa trẻ. Ta tách ảnh ra để tìm đầu, chân, tay bởi vì một cánh tay giơ cao hay hạ xuống vẫn là cánh tay đó. Đứa trẻ ở góc hay ở giữa ảnh, vẫn có đầy đủ bộ phận cơ thể như thế.
Bước 3: Lưu giữ kết quả từ từng mảnh ảnh vào mảng
Chúng ta không muốn làm mất sự sắp xếp của những mảnh gốc. Vì thế chúng ta lưu trữ kết quả xử lý mỗi mảnh vào mạng lưới sắp xếp giống như ảnh ban đầu, như hình sau:
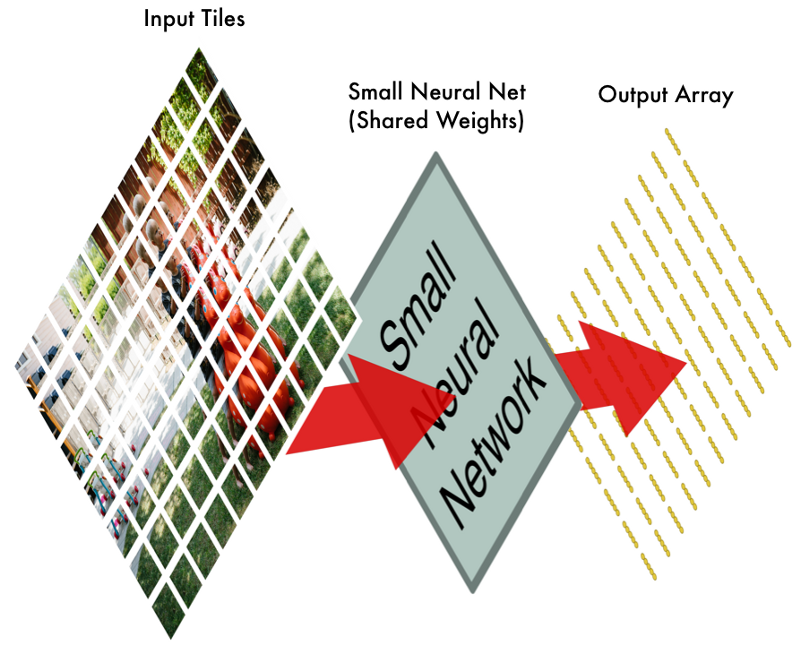 Chúng ta bắt đầu với ảnh lớn, và chúng ta kết thúc với nhiều mảng nhỏ hơn. Những mảng này lưu trữ những phần đáng chú ý từ ảnh ban đầu.
Chúng ta bắt đầu với ảnh lớn, và chúng ta kết thúc với nhiều mảng nhỏ hơn. Những mảng này lưu trữ những phần đáng chú ý từ ảnh ban đầu.
Từ bước 1 đến bước 3 được gọi là quá trình tích chập (Convolutional) - lấy giá trị đầu ra với từng mảnh ảnh, thông qua trọng số cố định
Bước 4: Giảm mẫu
Ở bước 3, ta đã có một chuỗi mảng chứa đặc trưng ảnh. Tuy thế, chuỗi mảng này vẫn rất lớn, khiến việc tính toán của máy tính trở nên khó khăn. Hơn nữa, ngoài đặc trưng, mảng cũng chứa cả nhiễu.

Để giảm chiều của mảng, ta dùng thuật toán max pooling - tách lọc lớn nhất.
Với mỗi ô trống 2x2 của mảng giá trị, ta chỉ lưu lại giá trị lớn nhất - đặc trưng rõ ràng và thú vị nhất của ảnh.
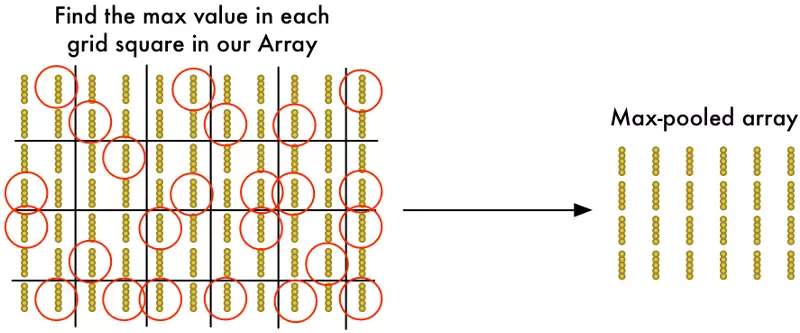
Bước 5: Truyền đặc trưng vào mạng nơron khác và dự đoán
Chúng ta đã chuyển bức ảnh lớn ban đầu thành tập hợp của những đặc trưng nổi bật nhất.
Giờ đây, chúng ta kết nối tất cả đặc trưng đó lại tạo thành Fully-connected Neural Network - mạng nơron kết nối hoàn chỉnh. Gía trị của mạng mới sẽ dùng làm đầu vào cho mạng nơron phân nhóm để tìm ra kết quả cuối cùng.
Kết nối mạng giống như khi tìm được tay, chân, đầu, ta cần lắp ghép lại thành 1 người hoàn chỉnh. Vì phương pháp này không phụ thuộc vào vị trí của người trong ảnh, mà phụ thuộc vị trí tương đối của các đặc trưng: tay, chân, đầu... với nhau, nên dù ảnh ở vị trí nào cũng sẽ nhận biết được.
Từ đầu đến cuối, toàn bộ quá trình của chúng ta như sau:
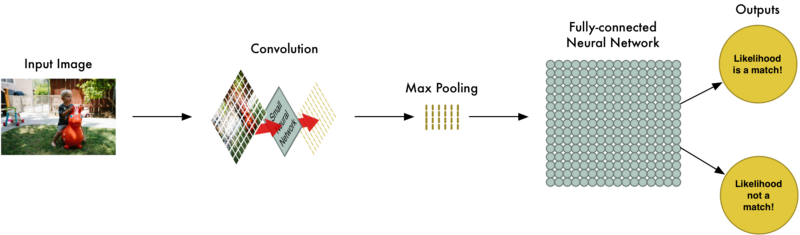
Chèn thêm nhiều bước nữa:
Quá trình nhận diện ảnh là một chuỗi các bước: tích chập, giảm mẫu và kết nối mạng hoàn chỉnh.
Khi giải quyết vấn đề thực tế, những bước này có thể được kết nối rất nhiều lần. Bạn có thể có 2, 3 thậm chí 10 lớp tích chập. Bạn có thể chèn giảm mẫu vào bất cứ vị trí nào bạn muốn.
Ý tưởng là bắt đầu từ ảnh lớn, từng bước một chúng ta trích xuất đặc trưng, giảm chiều để có kết quả cuối cùng. Càng nhiều bước tích chập, mô hình càng có thể nhận diện đặc trưng phức tạp.
Việc có nhiều lớp tích chập giúp ta tìm được các đặc trưng nhỏ hơn của cơ thể người: Thay vì nhận diện tay chân đầu, giờ chúng ta nhận diện bàn tay, cánh tay, khửu tay... Nhiều lớp tích chập hơn nữa giúp ta nhận diện đốt tay, móng tay, vân tay... Cứ tiếp tục như thế, ta có thể tìm người bằng cách tìm đặc trưng ở cấp độ phân tử (just kidding
) )
Cũng giống như nhận diện người qua phân tử (tưởng tượng như vậy), hầu hết các con số trích xuất từ học máy là những đặc trưng mà có thể con người không hình dung được, nhưng máy tính lại biết được. Người ta thường coi đó là hộp đên thần kì của học máy. Hiện nay, cũng đã tồn tại một số hệ thống nhận diện ảnh tốt hơn con người.
Vì nhận dạng ở cấp độ nhỏ hay rất nhỏ, nhận diện giữa gà hay chó, giữa ô tô hay xe máy đều sẽ có một số quá trình tách lọc đặc trưng giống nhau. Nên mạng nơron dùng để phân biệt động vật có thể được tái sử dụng (transfer learning) để phân biệt xe cộ, các loại hoa, đồ vật... và chỉ cần tinh chỉnh trọng số của mạng ở những lớp cuối cùng.
Đây là một mạng lưới CNN thực tế trong các bài nghiên cứu khoa học:
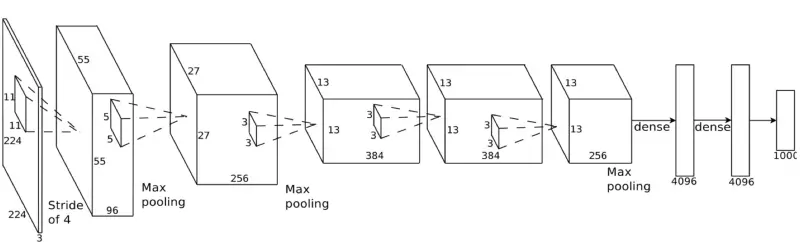
Trong trường hợp này, họ bắt đầu với ảnh 224x224 pixel, áp dụng 2 lần tích chập và giảm mẫu, 3 lần tích chập tiếp, rồi 1 giảm mẫu và thêm 2 lần mạng kết nối. Kết quả cuối cùng có thể giúp ta nhận dạng 1000 nhóm khác nhau.
Xây dựng mạng lưới tốt
Vậy làm thế nào bạn biết được những bước nào bạn cần làm để nhận diện ảnh hoạt động tốt
Sự thật thì, bạn phải làm nhiều thử nghiệm và kiểm chứng. Bạn có thể đào tạo 100 mạng trước khi bạn tìm ra cấu trúc và tham số tối ưu. Học máy bao gồm rất nhiều thử nghiệm và loại lỗi.
Nhận diện chim trong ảnh
Ta đã biết đủ nhiều để viết chương trình xác định nếu ảnh có chứa chim hay không.
Như thường lệ, ta cần có dữ liệu đầu tiên. Tập dữ liệu CIFAR10 chứa 6000 ảnh chim và 52,000 bức ảnh không chứa chim. Nhưng để có nhiều dữ liệu hơn, chúng ta cung cấp thêm tập dữ liệu Caltech-UCSDBirds bao gồm 12,000 ảnh chim.
Để viết ngắn gọn mình tạm gọi bức ảnh chứa chim là ảnh chim, ảnh không chứa chim là ảnh không chim.
Dưới đây là tập hợp chim từ tổ hợp dữ liệu:
 Và 52,000 ảnh không chim:
Và 52,000 ảnh không chim:

Tập dữ liệu này hoạt động tốt cho nhu cầu thử nghiệm, nhưng 72,000 bức ảnh chất lượng kém vẫn khá bé so với ứng dụng thực tế. Nếu bạn muốn đạt được chất lượng như Google, bạn cần hàng triệu tấm ảnh cỡ lớn. Trong học máy, có nhiều dữ liệu hơn hầu như lúc nào cũng quan trọng hơn có thuật toán tốt hơn. Bạn đã hiểu tại sao Google sẵn lòng cho bạn lưu trữ ảnh không giới hạn. Họ muốn nguồn dữ liệu dồi dào từ bạn đó  )
)
Để xây dựng phân nhóm, chúng ta sử dụng TFLearn. TFLearn được xây dựng trên TensorFlow và cho phép sử dụng hàm có sẵn để xây dựng mạng nơron tích chập.
Đây là đoạn mã xây dựng và đào tạo mạng nơron:
Nếu như bạn đào tạo mạng với thẻ đồ họa màn hình tốt và đủ bộ nhớ RAM (như Nvidia GTX980 Ti hoặc tốt hơn), mạng có thể hình thành sau khoảng 1h, nhưng nếu bạn đào tạo với CPU thông thường, thời gian sẽ lâu hơn rất nhiều.
Trong quá trình đào tạo, độ chính xác tăng lên. Sau vài lần chạy, độ chính xác khoảng 75,4%. Sau 10 lần, 91,7%. Sau 50 lần, giao động khoảng 95,5% và những lần chạy tiếp theo không làm tăng độ chính xác nên tôi đã dừng lại quá trình đào tạo.
Xin chúc mừng! Chương trình của chúng ta đã có thể nhận diện chim.
Kiểm nghiệm mạng nơron
Giờ chúng ta đã có thể dự đoán ảnh chim hay không, và đây là đoạn mã đơn giản để dự đoán ảnh chim.
Nhưng để thực sự biết sự hiệu quả của mạng, ta cần kiểm nghiệm với rất rất nhiều ảnh. Dữ liệu tôi tạo ra có 15.000 ảnh kiểm chứng, và kết quả cho độ chính xác 95%.
95% có thực sự tốt?
95% có ý nghĩa rất khác nhau, điều đó phụ thuộc vào chi tiết của cả quá trình đào tạo
Ví dụ, nếu 5% tập đào tạo gồm ảnh chim, và 95% ảnh không chim. Và chương trình đoán không chim cho tất cả các lần đoán, tỉ lệ chính xác sẽ là 95%! Nhưng điều đó hoàn toàn vô nghĩa.
Chúng ta cần nhìn kĩ vào những giá trị hơn là độ chính xác tổng thể. Để đánh giá một hệ thống có thực sự tốt, chúng ta cần biết mạng lỗi như thế nào, chứ không chỉ % dự đoán sai là bao nhiêu.
Thay vì nghĩ về dự đoán đúng hay sai, hãy chia nhỏ ra thành 4 tập phân biệt.
Các tập có công thức A + B, với A là True hoặc False (dự đoán đúng hay sai) và B là Positives hay Negatives (dự đoán chứa chim hay không chứa chim). Ví dụ: True Positives: dự đoán chứa chim, và dự đoán đúng.
-
Ảnh chim được dự đoán chính xác là có chim, được gọi là tập True Positives:

-
Ảnh không chứa chim và dự đoán chính xác, gọi là True Negatives

-
Ảnh không chứa chim nhưng đoán là có chim, gọi là False Positives

-
Ảnh chứa chim nhưng dự đoán là không chim, gọi là False Negatives

Kiểm nghiệm với 15.000 ảnh, dưới đây là bảng tổng kết:

Tại sao chúng ta lại phân chia kết quả như thế này? Bởi vì không phải mọi sai lầm đều bình đẳng.
Tưởng tượng chúng ta viết chương trình phát hiện ưng thư từ hình ảnh MRI - cộng hưởng từ. Trong trường hợp phát hiện ung thư, chúng ta thà giết nhầm (đoán có nhưng không phải) còn hơn bỏ sót (đoán không có nhưng lại có). Bỏ sót là trường hợp tồi tệ nhất, có thể giết chết sinh mạng của một con người.
Chúng ta có thể nhìn độ chính xác tổng thể thông qua giá trị Precision and Recall.

Precision = True Positives / Total Positives: Trong tất cả dự đoán là có (Positives), bạn đoán đúng bao nhiêu %.
Recall = True Positives / Total True: Trong tất cả các tồn tại (True), bạn đoán đúng bao nhiêu %.
Trong những lần dự đoán, chúng ta đúng 97.1%, và trong các ảnh chim, ta đoán đúng 91%. Mạng nơron dự đoán khá ổn đúng không nào!!!
Tìm hiểu thêm:
Thử nghiệm ví dụ với tflearn, làm quen với nhiều cáu trúc mạng nơron khác nhau.
Hoặc tìm hiểu thuật toán khác giúp máy tính chơi game Atari
Nguồn:
Nếu các bạn thấy hứng thú với series này, các bạn có thể follow mình hoặc clip series để nhận được thông báo khi có bản dịch mới nhất. Series hiện có 8 bài, những bản dịch tiếp theo sẽ được cập nhật dần dần
All rights reserved
