
Phân tích phản hồi khách hàng hiệu quả với Machine learning(Vietnamese Sentiment Analysis)
Bài đăng này đã không được cập nhật trong 6 năm
Thu thập thông tin phản hồi của khách hàng là một cách tuyệt vời giúp cho các doanh nghiệp hiểu được điểm mạnh, điểm yếu trong sản phẩm, dịch vụ của mình; đồng thời nhanh chóng nắm bắt được tâm ký và nhu cầu khách hàng để mang đến cho họ sản phẩm, dịch vụ hoàn hảo nhất.
Ngày nay, với sự phát triển vượt bậc của khoa học và công nghệ, đặc biệt là sự bùng nổ của Internet với các phương tiện truyền thông xã hội, thương mại điện tử,... đã cho phép mọi người không chỉ chia sẻ thông tin trên đó mà còn thể hiện thái độ, quan điểm của mình đối với các sản phẩm, dịch vụ và các vấn đề xã hội khác. Vì vậy mà Internet đã trở lên vô cùng quan trọng và là nguồn cung cấp một lượng thông tin vô cùng lớn và quan trọng.
Thông qua những dữ liệu được cung cấp qua Internet:
- Người dùng sử dụng nó để tìm kiếm, tham khảo trước khi đưa ra quyết định về sử dụng một sản phẩm hay dịch vụ nào đó.
- Các nhà cung cấp dịch vụ cũng có thể sử dụng những nguồn thông tin này để đánh giá về sản phẩm của mình, từ đó có thể đưa ra những cải tiến phù hợp hơn với người dùng, mang lại lợi nhuận cao hơn, tránh các rủi ro đáng tiếc xảy ra. Đặc biệt, khi 1 doanh nghiệp có 1 sản phẩm mới ra mắt thị trường thì việc lấy ý kiến phản hồi là vô cùng cần thiết.
- Các cơ quan chức năng có thể sử dụng những thông tin này để tìm hiểu xem quan điểm và thái độ của cộng đồng để có thể kịp thời sửa đổi, ban hành các chính sách cho hợp lý hơn.
Nếu bạn đang sở hữu một trang thương mại điện tử hay một Blog,... thì một câu hỏi mà bạn chắc chắn đã từng nghĩ tới đó là thái độ, đánh giá và quan điểm của người dùng với sản phẩm bạn cung cấp để có thể đưa ra những chỉnh sửa, cải tiến cho hệ thống thích hợp hơn với người dùng. Tuy nhiên, để trả lời cho câu hỏi đó, cũng như giải quyết tất cả những vấn đề trên không phải là một chuyện đơn giản. Bạn có thể đi hỏi từng người sử dụng một, sử dụng phiếu đánh giá,... Nhưng thực tế cho thấy rằng những phương pháp này là không khả thi hoặc không hiệu quả cho lắm. Các công ty nghiên cứu thị trường hiện này vẫn thường sử dụng các phương pháp truyền thống này tuy nhiên độ tin cậy không cao(do nhân viên tự làm giả dữ liệu) và độ tính cập nhật khá thấp(10-20 ngày cho thu thập thông tin, 10-20 ngày cho phân tích dữ liệu).
Để trả lời câu hỏi trên một cách hiệu quả và nhanh chóng thì bạn phải tận dụng phân tích được chính những thông tin mà người dùng để lại qua internet như các bình luận, đánh giá, bài chia sẻ,...
Sau đây, chúng ta sẽ cùng giải quyết bài toán bằng 1 bài toán đơn giản là phân loại phản hồi khách hàng thành 3 loại: Tích cực(Positive), Tiêu cực(Negative) và Trung tính(Neutral). Bài viết gồm các nội dung chính sau:
- Thu thập và phân tích đặc điểm dữ liệu
- Tiền xử lý dữ liệu
- Vector hóa dữ liệu
- Xây dựng và huấn luyện mô hình
- Hướng phát triển bài toán
Thu thập và phân tích đặc điểm dữ liệu
Trong bài viết này, mình giải quyết bài toán cho một miền dữ liệu cụ thể là những phản hồi của khách hàng tại các nhà hàng, trung tâm ăn uống. Để phía nhà hàng có thể biết được những phản hồi nhanh chóng của khách hàng trên fanpage của họ.
Ở đây, mình cần phân biệt giữa 2 khái niệm là dữ liệu huấn luyện và dữ liệu sử dụng thực tế.
Dữ liệu hệ thống sử dụng thực tế trong quá trình vận hành là dữ liệu trên chính những website, fanpage của nhà hàng, nơi mà họ đang muốn phân tích đánh giá của người dùng.
Tuy nhiên, ở đây bài toán được mình giải quyết bằng mô hình học máy có giám sát nên điều bắt buộc là dữ liệu huấn luyện của mình phải là dữ liệu có đánh nhãn(-1: Negative, 0: Neutral, 1: Positive) và lượng dữ liệu cho quá trình huấn luyện không hề ít.
Do đó để tận dụng lượng dữ liệu có nhãn sẵn, mình crawl luôn dữ liệu trên foody gồm comment kèm điểm đánh giá của họ theo quy tắc:
- score < 4 hoặc NaN: Negative
- 4 < score < 7 : Neutral
- score > 7 : Positive
Phân bố dữ liệu huấn luyện thu được như sau:
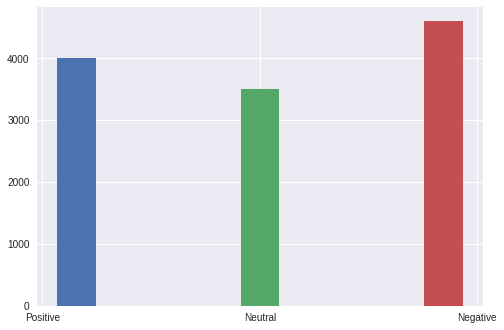
Dữ liệu thu được không có sự chênh lệch đáng kể về số lượng nên mình có thể sử dụng luôn cho quá trình huấn luyện.
Tuy nhiên, một đặc điểm quan trọng mà bạn cần lưu ý đó là độ dài ngắn của các bình luận là không cố định và có giá trị rất biệt(min=1, max > 3800 từ / 1 bình luận). Điều này nếu không được chuẩn hóa sẽ có ảnh hưởng rất nhiều tới tính đúng đắn của hệ thống.
Một vài ví dụ về dữ liệu mình thu thập được:
| Score | Review | Sentiment |
|---|---|---|
| 2.8 | Nhà hàng này sẽ làm hỏng hình ảnh của hệ thống cowboy jack. nước và đồ ăn quá chán phục vụ có vẻ toàn sinh viên làm việc chậm và thiếu chuyên nghiệp sẽ không bao giờ quay lại nữa. | Negative |
| 5.0 | Ngon nhưng đông và ồn. | Neutral |
| 6.5 | Đồ ăn bình thường | Neutral |
| 2.6 | Đồ nướng giá cả hợp lý. Nhưng có điều không hài lòng là đồ uống mang ra ăn xong rồi mới mang bia ra và nói đã order không hủy | Negative |
| 9.8 | Khu ẩm thực với đa dạng đồ lại còn bày trí đẹp nên là rất hấp dẫn đối với những đứa cuồng ăn uống như mình. Đồ ăn giá cả phải chăng không quá cao. Tuy nhiên về chất lượng thì chưa thật sự ấn tượng. Mình thấy ổn thôi chứ chưa thực sự thích. có vài món để ngoài lâu nên bị nguội ăn không ngon. Kem trà xanh dù rẻ nhưng mình ăn thấy vị cũng bình thường. bánh ngọt chỉ có nhân viên thu không có nhân viên giám sát tự mình lấy bánh xong rồi mang qua thanh Đúng kiểu đề cao sự tự giác và trung thực của người Nhật thích điểm này. | Positive |
| 5.0 | Kem Tràng Tiền thì có tiếng từ lâu trời nắng nong hay se se ăn một cây kem TT thì đó là điều tuyệt còn giá thì hơi cao một chút | Neutral |
| 10.0 | Tất cả đều tuyệt | Positive |
| 1.8 | Quán này giờ ăn cực chán. hôm trước đi gọi món ăn chán quá mà. Mình nghĩ do không biết gọi liền chạy vòng quanh chỗ nấu nướng nhưng cũng y như đầu vào thì đúng là ngon và giá cả hợp giờ tệ và thua ngay cả Món Huế mặc dù cửa hàng Quán đợi thì lâu thôi rồi lượm đáng Quán Ngon Phan Bội Châu | Negative |
| 9.8 | Ghé lần thích ơi là thích | Positive |
| 10.0 | Thèm nhất cafe sữa trứng ở ngon khỏi chê | Positive |
Dựa vào những kết quả phân tích dữ liệu thô, chúng ta tiến hành bước tiếp theo là tiền xử lý dữ liệu.
Tiền xử lý dữ liệu
Trong bài viết này mình sẽ sử dụng 1 mô hình Deeplearning đơn giản để mô hình hóa bài toán.
Như chúng ta đã biết, các mô hình Deeplearning có khả năng end-to-end khá tốt(Từ dữ liệu thô tới mô hình, không cần tiền xử lý trước). Tuy nhiên, Nếu ta kết hợp vừa tiền xử lý vừa sử dụng mô hình end-to-end thì kết quả sẽ tốt hơn nhiều.
Ở đây, mình chỉ sử dụng một số tiền xử lý cơ bản như:
- Chuẩn hóa về chữ thường
- Thay thế các url trong dữ liệu bởi nhãn link_spam
- Tách từ (Sử dụng underthesea của tác giả Vũ Anh)
- Loại bỏ dấu câu và các ký tự đặc biệt
- Xử lý các trường hợp người dùng láy láy âm tiết(Ví dụ: Ngooon quááááá điiiiiiii !!!!!)
- Chuẩn hóa các từ viết tắt cơ bản(Ví dụ: k, ko, k0 --> không, bt --> bình thường,...)
- Loại bỏ số và các từ chỉ có 1 ký tự
Sau khi thực hiện tuần tự và đầy đủ theo quy trình trên, ta thu được bộ dữ liệu sạch cho pha tiếp theo của mô hình. Chia dữ liệu theo tỉ lệ 80:20 để có được dữ liệu train và validation. Tỷ lệ này đều cho mỗi nhãn.
Vector hóa dữ liệu
Kỹ thuật được mình sử dụng ở đây là word2vec sau đó thực hiện comment2matrix. Bạn có thể tìm hiểu thêm 1 số phương pháp mô hình hóa vector khác cho từ hoặc hiểu kĩ hơn về word2vec qua bài viết trước đó của mình ở đây.
Trước tiên, ta tiến hành tạo pretrained word embedding bằng thư viện gensim:
Import các thư viện cần thiết.
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
import os
import pandas as pd
Tiến hành đọc dữ liệu đã tiền xử lý ở các file. Ở đây mình lưu mỗi nhãn là 1 file csv nên mình sẽ đọc bằng pandas.
path = './data/'
def readdata(path):
list_file = os.listdir(path)
data = pd.DataFrame()
for filename in list_file:
data = pd.concat([data, pd.read_csv(os.path.join(path, filename), sep = ',')])
return data.Review, data.Label
Đưa dữ liệu về định dạng input của gensim và tiến hành train mô hình. Ở đây mình vector hóa từ thành vector 128 chiều.
reviews, labels = readdata(path)
input_gensim = []
for review in reviews:
input_gensim.append(review.split())
model = Word2Vec(input_gensim, size=128, window=5, min_count=0, workers=4, sg=1)
model.wv.save("word.model")
Sau khi có được pretrained word embedding, ta tiến hành comment2matrix. Ở đây mình sẽ giải thích tại sao lại là comment2matrix. Lý do là mình muốn sử dụng mô hình CNN cho bài toán của mình.
Tuy nhiên, chúng ta nghe tới Convolutional neural network, chúng ta thường nghĩ ngay tới Computer Vision. Ở một khía cạnh khác, khi sử dụng cho các bài toán NLP, CNN lại cho ra những kết quả hết sức thú vị.
Mô hình CNN sử dụng các bộ lọc xoắn để nắm bắt mối quan hệ địa phương. Nhờ khả năng nắm bắt các mối quan hệ địa phương, CNN có khả năng lọc được các ngữ cảnh gần giữa các từ trong câu, có thể áp dụng rất tốt trong bài toán này.
Vậy, dữ liệu text và dữ liệu ảnh có điểm gì tương đồng mà ta có thể sử dụng một mô hình xử lý ảnh cho dữ liệu text? Có cách nào để chúng ta nhìn nhận một đoạn text như một bức ảnh không?
Như một cách để giúp chúng ta dễ tưởng tượng hơn, giả sử ta đã sử dụng word embedding như đã trình bày ở trên để biến mỗi từ trong một đoạn văn bản thành các vector có số chiều là n. Từ đó ta có thể coi môt câu văn(đoạn văn) như một ma trận mxn, trong đó m là kích thước hay số từ có trong văn bản đó. Ma trận này về mặt biểu diễn trông cũng có vẻ tương đồng với ma trận biểu diễn cho một bức ảnh đa mức xám(1 channel) với kích thước mxn.
Vậy, về mặt hình thức, ta có thể dễ dàng thấy được việc sử dụng CNN cho bài toán NLP là hoàn toàn có thể. Ta tiến hành chuyển mỗi comment của người dùng thành 1 matrix ngay thôi.
import gensim.models.keyedvectors as word2vec
model_embedding = word2vec.KeyedVectors.load('./word.model')
word_labels = []
max_seq = 200
embedding_size = 128
for word in model_embedding.vocab.keys():
word_labels.append(word)
def comment_embedding(comment):
matrix = np.zeros((max_seq, embedding_size))
words = comment.split()
lencmt = len(words)
for i in range(max_seq):
indexword = i % lencmt
if (max_seq - i < lencmt):
break
if(words[indexword] in words_label):
matrix[i] = model_embedding[words[indexword]]
matrix = np.array(matrix)
return matrix
Ở đây mình xử lý vấn đề các câu dài ngắn khác nhau bằng cách đệ quy các câu ngắn sao cho độ dài các câu là gần như tương đồng và có độ dài tối đa là 200 chiều. Để chọn được con số 200, chúng ta cùng nhìn lại dữ liệu của chúng ta một chút.
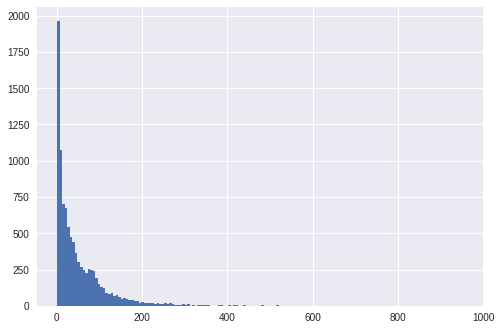
Như nhìn thấy ở trên, độ dài của các câu bình luận tập trung nhiều ở ngưỡng dưới 200, trên 200 từ không đáng kể. Với những bình luận trên 200 từ thì ta chỉ tiến hành phân tích trên 200 từ đầu tiên.
Xây dựng và huấn luyện mô hình
Về chi tiết mô hình CNN mình sẽ không đề cập tới chi tiết ở đây. Chỉ có một vài lưu ý nhỏ khi áp dụng mô hình CNN cho bài toán NLP.
- Thay vì đầu vào là pixels của hình ảnh, ta có một ma trận mxn là biểu diễn cho một câu hay một đoạn văn bản. Mỗi hàng của ma trận là vector đại diện cho một từ.
- Đối với bài toán ứng dụng CNN cho lĩnh vực NLP, bộ lọc này có một điều đặc biệt. Đó là kích thước theo chiều ngang của bộ lọc thường chính bằng số cột của ma trận biểu diễn cho văn bản. Để khi trượt, ta có thể trượt được trên toàn bộ từ, hay nói cách khác là ta có thể nắm bắt được ngữ nghĩa của toàn bộ từ. Khái niệm "trượt" ở đây sẽ được hiểu đơn giản chỉ là trượt từ trên xuống dưới, cho tới khi hết văn bản.
- Chúng ta lại thường bỏ qua khái niệm cửa sổ trong pooling và thực hiện pooling trên toàn bộ ma trận để lấy được một đặc trưng nổi trội duy nhất.
Tiến hành cài đặt một mô hình đơn giản bằng Keras(Đây là mô hình cực kì đơn giản, chỉ nhằm mục đích giới thiệu).
Trước tiên, tiến hành số hóa tất cả dữ liệu đầu vào, các câu comment được chuyển về ma trận số, các label được chuyển về dạng one-hot.
[1, 0, 0] : neutral
[0, 1, 0] : positive
[0, 0, 1] : negative
train_data = []
label_data = []
for x in tqdm(pre_reviews):
train_data.append(comment_embedding(x))
train_data = np.array(train_data)
for y in tqdm(labels):
label_ = np.zeros(3)
try:
label_[int(y)] = 1
except:
label_[0] = 1
label_data.append(label_)
Import các thư viện cần thiết và định nghĩa các tham số cho mô hình:
import numpy as np
from tensorflow.keras import layers
from tensorflow import keras
import tensorflow as tf
from keras.preprocessing import sequence
sequence_length = 200
embedding_size = 128
num_classes = 3
filter_sizes = 3
num_filters = 150
epochs = 50
batch_size = 30
learning_rate = 0.01
dropout_rate = 0.5
Định nghĩa kiến trúc mô hình:
x_train = train_data.reshape(train_data.shape[0], sequence_length, embedding_size, 1).astype('float32')
y_train = np.array(label_data)
# Define model
model = keras.Sequential()
model.add(layers.Convolution2D(num_filters, (filter_sizes, embedding_size),
padding='valid',
input_shape=(sequence_length, embedding_size, 1), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(198, 1)))
model.add(layers.Dropout(dropout_rate))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(3, activation='softmax'))
# Train model
adam = tf.train.AdamOptimizer()
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
print(model.summary())
Tiến hành train mô hình, sử dụng 7000 sample đầu để train, còn lại cho validaion.
model.fit(x = x_train[:7000], y = y_train[:7000], batch_size = batch_size, verbose=1, epochs=epochs, validation_data=(x_train[:3000], y_train[:3000]))
model.save('models.h5')
Kêt quả thu được sau vào epoch đầu:
Epoch 1/50
7000/7000 [==============================] - 4s 549us/step - loss: 0.4499 - acc: 0.8257 - val_loss: 0.6694 - val_acc: 0.6894
Epoch 2/50
7000/7000 [==============================] - 4s 521us/step - loss: 0.4048 - acc: 0.8413 - val_loss: 0.5958 - val_acc: 0.7220
Epoch 3/50
7000/7000 [==============================] - 4s 508us/step - loss: 0.3789 - acc: 0.8496 - val_loss: 0.6041 - val_acc: 0.7118
Mô hình dự đoán
Đến thời điểm hiện tại, chúng ta đã có mô hình đã được huấn luyện cho bài toán dưới dạng h5 file. Giờ đây, để test lại độ chính xác của mô hình với các dữ liệu thực tế(dữ liệu thực tế chưa có nhãn, ta dùng model này để gán nhãn cho nó), ta tiến hành load lại model:
from keras.models import load_model
model_sentiment = load_model("models.h5")
Quá trình tiền xử lý dữ liệu test phải giống hệt với quá trình tiền xử lý với dữ liệu train, do đó, ta tái sử dụng lại các hàm này. Các hàm này là hàm pre_process trong phần tiền xử lý dữ liệu(hàm này mình chỉ nó những yêu cầu cần xử lý ở trên chứ chưa có code vì cái này cho bạn tự xử lí phù hợp với dữ liệu của bạn) và hàm comment_embedding trong phần vector hóa dữ liệu.
def pre_process(text):
# các bạn tự thêm các tiền xử lý của mình vào đây nhá
return text
text = "đồ ăn ở đây vừa nhiều vừa ngon"
text = pre_process(text)
maxtrix_embedding = np.expand_dims(comment_embedding(text), axis=0)
maxtrix_embedding = np.expand_dims(maxtrix_embedding, axis=3)
result = model.predict(maxtrix_embedding)
result = np.argmax(result)
print("Label predict: ", result)
Kết quả label mà model dự đoán được lưu trong biến result, đấy sẽ là một trong các giá trị 0, 1 hoặc 2. Như trong định nghĩa ngay từ đầu của mình (-1: Negative, 0: Neutral, 1: Positive) thì label chuẩn của câu đồ ăn ở đây vừa nhiều vừa ngon là nhãn Positive(lưu ý: nhãn -1 trong python là index của vị trí cuối cùng trong mảng, tức là ứng với giá trị là 2).
LƯU Ý: Một lưu ý nhỏ nữa là bài viết này chỉ là một cách sử dụng kiến trúc Conv2D áp dụng vào bài toán phân loại quan điểm người dùng(sentiment analysis), còn rất nhiều cách xây dựng, sử dụng các mô hình khác hiệu quả có thể hơn hoặc không hơn, mình sẽ không nói ở đây. Cảm ơn các bạn vì đã đọc bài.
Hướng phát triển bài toán
Thực ra bài toán trên là một bài toán cực kì đơn giản và nó có chút khác biệt so với những yêu cầu thực tế của doanh nghiệp. Ví dụ, khi Bphone 3 vừa được ra mắt, BKAV rất mong muốn lấy được sự phản hồi của khác hàng, xem trên mạng xã hội, các bình luận trên báo nói gì về sản phẩm của mình, tuy nhiên không chỉ nằm ở khía cạnh tích cực và tiêu cực mà họ còn muốn lấy được phản hồi 1 cách cụ thể như đánh giá về pin, chất lượng hình ảnh, khung viền, camera,... Và sự đánh giá về các sản phẩm khác cùng phân khúc với Bphone. Các bạn có thể tìm hiểu thêm về bài toán đó tại đây Target and aspect sentiment analysis.
All rights reserved
