Cracking A Captcha For Fun (The Dumb Way)
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Captcha là gì ?
Khi sử dụng internet thì chắc hẳn ai cũng đã từng 1 lần phải điền Captcha. Theo Wikipedia:
A CAPTCHA (an acronym for "Completely Automated Public Turing test to tell Computers and Humans Apart") is a type of challenge-response test used incomputing to determine whether or not the user is human.
Được sử dụng để kiểm tra thử xem người đang sử dụng web là người hay là máy (crawler, spider, bot,...). Bạn thường sẽ được nhìn 1 bức ảnh đã được làm méo và nhiễu để đảm bảo là con người sẽ ngay lập tức nhận ra, còn nếu là máy móc, dù có xử lý hình ảnh cũng mất thời gian hoặc không thể đưa ra được nhận diện chính xác. Nhưng nhiều khi, chính captcha này cũng làm khó cả con người (yaoming). Ví dụ như captcha dưới đây, liệu bạn có thể nhận ra được là những chữ cái nào ?

Nội dung
Việc tự động nhận diện captcha sẽ thường liên quan đến kĩ thuật xử lý hình ảnh (Image Processing), OCR (Optical Character Recognition) và đôi khi là cả machine learning. Một số công cụ OCR khá nổi tiếng có thể kể đến là Tesseract. Tuy nhiên trong bài này chúng ta sẽ thử tìm cách break một captcha đơn giản như sau theo cách "thủ công"  (vì ta không biết cách trainning cho tesseract, hoặc cũng có thể là do ta đang...vội (haha) )
(vì ta không biết cách trainning cho tesseract, hoặc cũng có thể là do ta đang...vội (haha) )

Phân tích
Refine Captcha
Với captcha như trên và captcha ở cuối bài ta có nhận xét như sau:
- Kích thước font là cố định
- Captcha luôn là một chuỗi 4 kí tự gồm hoặc chữ hoa, chữ thường, số
- Vị trí bắt đầu captcha trong ảnh luôn cố định
- Có các vạch sọc kích thước chiều rộng 1-2 px với màu khác màu nền và màu captcha dọc theo ảnh để gây nhiễu quá trình phân tích.
Để nhận diện được captcha này, điều đầu tiên cần làm đó là loại bỏ nhiễu dựa trên màu nền và màu chữ captcha.
Ta có nhận xét sau: Màu nhiều nhất trong ảnh chính là màu nền, màu nhiều thứ 2 là màu captcha. Còn lại các màu khác sẽ là nhiễu. Và để kết quả nhận diện tốt nhất, ta đưa ảnh về thành ảnh đen, trắng.
Tiếp theo là loại bỏ nhiễu. Vì kích thước mỗi sọc nhiễu nhỏ, ta so sánh với mỗi điểm ảnh không phải là màu nền hoặc màu captcha để xem xét xem nên đổi màu điểm ảnh đó thành màu nền hay là màu captcha.
Tổng hợp lại, hàm process sẽ xử lý và lưu lại ảnh mới ở tên tmp.png cho chúng ta:
def process(file_name):
im = Image.open(file_name,"r")
# Get the size of the picture
width, height = im.size
#convert to RGB
pixels = im.load()
d = {}
for x in range(width):
for y in range(height):
if pixels[x,y] not in d:
d[pixels[x,y]]=1
else:
d[pixels[x,y]]+=1
print d
sorted_d = sorted(d.items(), key=operator.itemgetter(0))
background = sorted_d[0][0]
captcha = sorted_d[1][0]
print background, captcha
for x in range(width):
for y in range(height):
if pixels[x,y] != captcha:
pixels[x,y]=0
else:
pixels[x,y]=1
im.putpalette([0, 0, 0,255,255,255])
#pattern fix
for x in range(1,width-1,1):
for y in range(1,height-1,1):
if (pixels[x,y] != pixels[x-1,y-1]) and (pixels[x,y] != pixels[x+1,y-1]) and (pixels[x,y] != pixels[x-1,y+1]) and (pixels[x,y] != pixels[x+1,y+1]):
pixels[x,y]=1
im.save("tmp.png")
Và ta được kết quả như sau:
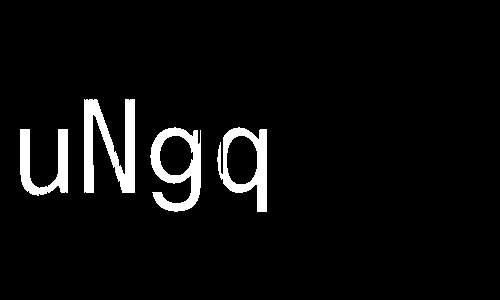
Sampling
Bước tiếp theo là lấy mẫu (sampling). Vì cỡ font là cố định, ta sẽ chia các chữ thành từng phần theo chiều dọc giống như trong hình dưới.

Phần code duyệt qua các điểm ảnh, kiểm tra xem điểm ảnh đó thuộc chữ cái trước hay sau như dưới đây. Thuật toán khá đơn giản thôi
captcha_filtered = Image.open('tmp.png')
captcha_filtered = captcha_filtered.convert("P")
inletter = False
foundletter = False
start = 0
end = 0
letters = []
for y in range(captcha_filtered.size[0]): # slice across
for x in range(captcha_filtered.size[1]): # slice down
pix = captcha_filtered.getpixel((y,x))
if pix != 0:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
print "[+] Horizontal positions:", letters
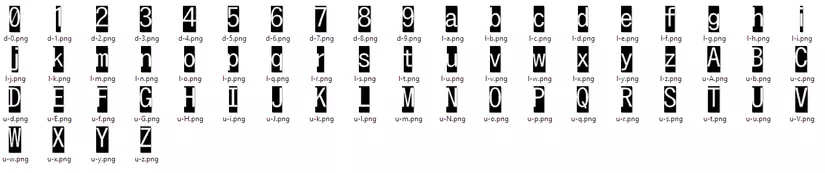
Tiến hành giảm kích thước của từng chữ (crop) ta sẽ được file ảnh mẫu như bên dưới (giảm xuống kích cỡ 51 x128 px)

Ta sẽ dùng ảnh này để làm mẫu so sánh cho các ảnh sau. Do đó, ta cần có đầy đủ tất cả các chữ cái và số (charset) được dùng cho captcha.
Đến đây với mẫu trên ta có thể hoàn toàn dùng để train cho Tesseract nhận diện. Tuy nhiên, do thiết kế của font, kết quả thường bị nhầm lẫn giữa 0 và O và Q, hay là 1 và I. Ta có thể dùng cách khác.
Matching
Với việc kích cỡ của chữ mẫu và chữ trong captcha giống nhau, bài toán quy về việc tính toán sự khác nhau giữa 2 ảnh. Hai ảnh ít khác nhau nhất sẽ có khả năng cao là của cùng 1 chữ cái. Để tính toán sự khác nhau này thì có nhiều cách:
ta sẽ sử dụng cách thứ 3. Trong Python đã có sẵn hàm ImageChops.difference trả về diff của 2 ảnh. Ta sẽ tính tổng diff của từng pixel và lấy ra mẫu có diff nhỏ nhất. Đó chính là chữ cái tương ứng của captcha ta cần tìm. Dưới đây là code của toàn bộ chương trình:
import shutil
import operator
import os
from PIL import Image, ImageChops
from operator import itemgetter
def process(file_name):
im = Image.open(file_name,"r")
# Get the size of the picture
width, height = im.size
#convert to RGB
pixels = im.load()
d = {}
for x in range(width):
for y in range(height):
if pixels[x,y] not in d:
d[pixels[x,y]]=1
else:
d[pixels[x,y]]+=1
print d
sorted_d = sorted(d.items(), key=operator.itemgetter(0))
background = sorted_d[0][0]
captcha = sorted_d[1][0]
print background, captcha
for x in range(width):
for y in range(height):
if pixels[x,y] != captcha:
pixels[x,y]=0
else:
pixels[x,y]=1
im.putpalette([0, 0, 0,255,255,255])
#pattern fix
for x in range(1,width-1,1):
for y in range(1,height-1,1):
if (pixels[x,y] != pixels[x-1,y-1]) and (pixels[x,y] != pixels[x+1,y-1]) and (pixels[x,y] != pixels[x-1,y+1]) and (pixels[x,y] != pixels[x+1,y+1]):
pixels[x,y]=1
im.save("tmp.png")
def main(file_name):
print "[?] Input file:", file_name
process(file_name)
captcha_filtered = Image.open('tmp.png')
captcha_filtered = captcha_filtered.convert("P")
inletter = False
foundletter = False
start = 0
end = 0
letters = []
for y in range(captcha_filtered.size[0]): # slice across
for x in range(captcha_filtered.size[1]): # slice down
pix = captcha_filtered.getpixel((y,x))
if pix != 0:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
print "[+] Horizontal positions:", letters
captcha = ""
if len(letters) == 4:
file_names = ["d-0.png", "d-3.png", "d-6.png", "d-9.png", "l-c.png", "l-f.png", "l-i.png", "l-m.png", "l-p.png", "l-s.png", "l-v.png", "l-y.png", "u-b.png", "u-E.png", "u-H.png", "u-k.png", "u-N.png", "u-q.png", "u-t.png", "u-w.png", "u-z.png", "d-1.png", "d-4.png", "d-7.png", "l-a.png", "l-d.png", "l-g.png", "l-j.png", "l-n.png", "l-q.png", "l-t.png", "l-w.png", "l-z.png", "u-c.png", "u-f.png", "u-i.png", "u-l.png", "u-o.png", "u-r.png", "u-u.png", "u-x.png", "d-2.png", "d-5.png", "d-8.png", "l-b.png", "l-e.png", "l-h.png", "l-k.png", "l-o.png", "l-r.png", "l-u.png", "l-x.png", "u-A.png", "u-d.png", "u-G.png", "u-J.png", "u-m.png", "u-p.png", "u-s.png", "u-V.png", "u-y.png"]
for letter in letters:
im3 = captcha_filtered.crop(( letter[0], 0, letter[1],captcha_filtered.size[1] ))
im3 = im3.crop((0, 92, im3.size[0], 220))
base = im3.convert('L')
class Fit:
letter = None
difference = 0
best = Fit()
for letter in file_names:
#print letter
current = Fit()
current.letter = letter
sample_path = "samples/" + letter
#print sample_path
sample = Image.open(sample_path).convert('L').resize(base.size)
difference = ImageChops.difference(base, sample)
for x in range(difference.size[0]):
for y in range(difference.size[1]):
current.difference += difference.getpixel((x, y))
if not best.letter or best.difference > current.difference:
best = current
#final captcha decoded
tmp = ''
tp, letter = best.letter.split('-')
letter = letter.split('.')[0]
if tp == 'u':
tmp = letter.upper()
else:
tmp = letter
print "[+] New leter:", tmp
captcha = captcha + tmp
print "[+] Correct captcha:", captcha
else:
print "[!] Missing characters in captcha !"
if __name__ == '__main__':
main("captcha.png")
Check It Out !
[?] Input file: captcha.png
{0: 137771, 1: 7261, 2: 375, 3: 109, 4: 97, 5: 114, 6: 131, 7: 119, 8: 78, 9: 164, 10: 35, 11: 142, 12: 93, 13: 135, 14: 193, 15: 183, 16: 132, 17: 8, 18: 100, 19: 92, 20: 17, 21: 77, 22: 51, 23: 16, 24: 112, 25: 123, 26: 51, 27: 122, 28: 103, 29: 99, 30: 148, 31: 103, 32: 73, 33: 76, 34: 51, 35: 111, 36: 74, 37: 5, 38: 87, 39: 168, 40: 66, 41: 5, 42: 121, 43: 226, 44: 112, 45: 63, 46: 114, 47: 111, 48: 183}
0 1
[+] Horizontal positions: [(20, 68), (84, 135), (150, 201), (217, 267)]
[+] New leter: u
[+] New leter: N
[+] New leter: g
[+] New leter: q
[+] Correct captcha: uNgq
[Finished in 13.1s]
Thử với 1 captcha khác
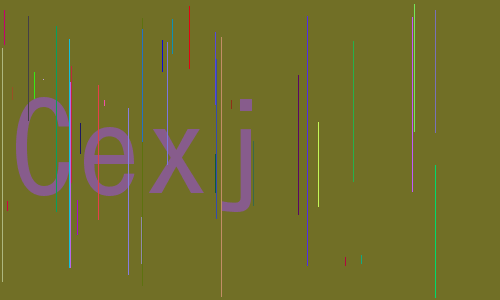
[?] Input file: another_captcha.png
{0: 139612, 1: 5586, 2: 131, 3: 188, 4: 107, 5: 105, 6: 179, 7: 113, 8: 95, 9: 135, 10: 31, 11: 10, 12: 234, 13: 141, 14: 32, 15: 39, 16: 6, 17: 63, 18: 250, 19: 27, 20: 160, 21: 9, 22: 229, 23: 155, 24: 73, 25: 260, 26: 35, 27: 133, 28: 175, 29: 85, 30: 117, 31: 105, 32: 186, 33: 9, 34: 1, 35: 35, 36: 65, 37: 9, 38: 140, 39: 123, 40: 13, 41: 35, 42: 186, 43: 123, 45: 113, 46: 47, 47: 128, 48: 167}
0 1
[+] Horizontal positions: [(16, 69), (84, 134), (150, 203), (222, 252)]
[+] New leter: C
[+] New leter: e
[+] New leter: x
[+] New leter: j
[+] Correct captcha: Cexj
[Finished in 12.5s]
Chạy thử với nhiều captcha mẫu khác ra kết quả khá chính xác, tất nhiên cũng có những trường hợp sai. Nhưng như vậy là khá ổn cho 1 cách làm "dumb" rồi
Kết luận
Hãy học xử lý hình ảnh và OCR để có thể làm tốt hơn nữa
Tham khảo
All rights reserved
