Phạm Hữu Quang
@QuangPH
Báo cáo
Xử lý json trong php
Phạm Hữu Quang
Đã trả lời thg 1 30, 2019 2:34 CH
<?php
//Enter your code here, enjoy!
$data = '{
"status":true,
"message":"Successfully received info.",
"site":"Youtube",
"title":"Taylor Swift - Shake It Off",
"like_count":6290433,
"dislike_count":744939,
"view_count":2234478374,
"duration":242,
"upload_date":"20140818",
"description":"Taylor\u2019s new release 1989 is Available Now featuring the hit single \u201cShake It Off\u201d and her latest single \u201cBlank Space\u201d. ",
"tags":[
"Taylor",
"Swift",
"Shake",
"It",
"Off",
"Big",
"Machine",
"Records"],
"uploader":"TaylorSwiftVEVO",
"uploader_url":"http:\/\/www.youtube.com\/user\/TaylorSwiftVEVO",
"thumbnail":"https:\/\/i.ytimg.com\/vi\/nfWlot6h_JM\/maxresdefault.jpg",
"streams":[
{
"url":"https:\/\/r6---sn-4g57knkz.googlevideo.com\/videoplayback?id=9d[...]",
"format":"audio only (DASH audio)",
"format_note":"Audio only, no video",
"extension":"m4a",
"video_codec":"none",
"audio_codec":"mp4a.40.5",
"filesize":1438229,
"height":null,
"width":null
},
{
"url":"https:\/\/r6---sn-4g57knkz.googlevideo.com\/videoplayback?key=[...]",
"format":"1920x1080 (1080p)",
"format_note":"1080p",
"extension":"webm",
"video_codec":"vp9",
"audio_codec":"none",
"filesize":68016821,
"height":1080,
"width":1920
}
]}';
$data2 = json_decode($data, true);
foreach ($data2['streams'] as $value) {
echo $value['url'];
echo "\n";
}
Kết quả trả về:
https://r6---sn-4g57knkz.googlevideo.com/videoplayback?id=9d[...]
https://r6---sn-4g57knkz.googlevideo.com/videoplayback?key=[...]
Regex number in Javascript
Phạm Hữu Quang
Đã trả lời thg 1 30, 2019 6:19 SA
regex = /0\.\d+|[1-9]\d*(\.\d+)?/
Kết quả:
0.011 --> True
03.1231 --> False
23.283189 --> True
0242 --> False
Thư viện nào nhận diện chữ (font máy tính) tốt nhất mọi người nhỉ?
Phạm Hữu Quang
Đã trả lời thg 12 29, 2018 11:29 SA
Ngoài Tesseract thì còn khá nhiều, bạn có thể xem qua ở đây https://github.com/kba/awesome-ocr
Còn kinh nghiệm cái nào tốt thì mình không biết 
Tốt thì chỉ có xây dựng lại mạng, train lại với dữ liệu của mình. Mình nghĩ vậy
Hỏi về regex
Phạm Hữu Quang
Đã trả lời thg 12 26, 2018 6:59 SA
text = "ROUND(SUM(F9:I9)/2,0)"
elements = text.scan /\d+[,.]?\d+|\w+|\W/
Kết quả:
=> ["ROUND", "(", "SUM", "(", "F9", ":", "I9", ")", "/", "2,0", ")"]
Trong đó, mình định nghĩa text đầu vào của bạn thành 3 loại:
- Số thực: \d+[,.]?\d+ (ví dụ 2.2 hoặc 2,22)
- chữ và số liền nhau: \w+
- phần còn lại: \W
Tìm kiếm dataset về review sản phẩm bằng tiếng Việt
Phạm Hữu Quang
Đã trả lời thg 12 12, 2018 10:22 SA
Mình gửi bạn bộ SA VLSP 2016, làm trên những bộ của VLSP thì bạn có thể đánh gía được kết quả mình làm được so với các đội khác Bộ này là thuần sentiment analysis. Ngoài ra bộ SA VLSP 2018 còn có kết hợp thêm các yếu tố là Target and aspect sentiment analysis cũng rất hay. Bộ này thì bạn phải request lên xin các anh chị bên đấy vì không được public. Request tại đây hoặc vào đây hỏi xin, anh/chị quản lý sẽ trả lời.
Ngoài ra bạn cũng có thể tự lấy dữ liệu cho nhiều, cách đơn giản là bạn lên các trang thương mại điển tử, crawl bình luận của người dùng về sản phẩm kèm vote của người đó cho sản phẩm và đặt 1 ngưỡng để phân loại positive, negative, neutral một cách tự động(cái này cũng hơn xui, cần review lại).
Nhờ anh em chỉ cách lấy font chữ khi sử dụng google cloud vision
Phạm Hữu Quang
Đã trả lời thg 12 5, 2018 6:05 SA
Optical Character Recognition (OCR) không làm được những điều bạn cần nên bạn không lấy được từ Cloud Vision của Google.
Nhờ anh em chỉ cách truy cập/lấy thông tin thống kê/phân tích của Google về các keyword
Phạm Hữu Quang
Đã trả lời thg 12 5, 2018 4:14 SA
Mình chưa làm cái này bao giờ nhưng mình đoán họ sử dụng AdWords API.
Cụ thể là ở đây https://developers.google.com/adwords/api/docs/guides/targeting-idea-service lấy được VOLUME, CPC, Competition còn Trends thì Google cũng có Google Trends.
Có ai từng áp dụng ReInforcement Learning vào NLP chưa nhỉ?
Phạm Hữu Quang
Đã trả lời thg 11 27, 2018 3:58 SA
Bạn làm nhiều bài toán thế. 😃) Mình thì chưa làm về ReInforcement Learning, trước có nghe 1 lần nhưng bài toán khác, là tương tác với game thông qua ngôn ngữ con người nhập vào để bot tự chơi game 😦( Cũng không đọng được mấy
Nhưng bài toán của bạn thì mình nghĩ không nên và cũng không phải dùng ReInforcement Learning. ReInforcement Learning là bài toán agent thực hiện các actions trong môi trường để từ những cải thiện ở môi trường thay đổi lại state của agent(Mình đoán thế chứ mình không biết 😃) ). Nếu bạn coi đây là bài toán ReInforcement Learning vậy bạn phân tích thử agent của bạn là gì, agent thực hiện action gì để thay đổi state trong environment. Thế nên RL mới được áp dụng nhiều trong lý thuyết trờ chơi, lý thuyết điều khiển và các hệ thống tác tử,...
Quay lại với bài toán của bạn. Có 2 cách để giải quết. Cách 1: Vẫn không có gì thay đổi trừ việc khi có nhiều dữ liệu mới mà có vẻ khác với dữ liệu cũ thì bạn thực hiện train lại mô hình, cập nhật mô hình mới. Mình nghĩ hiện tại đa phần các công ty ở Việt Nam vẫn sử dụng phương pháp này. Nếu dữ liệu của bạn nhiều, mang tính tổng quát và không thay đổi theo xu hướng xã hội(mang tính tổng quát cao) thì việc phải cập nhật là rất ít. Mình khuyên bạn dùng cách này kết hợp lí thuyết về semi-supervised.
Cách 2; Đúng như mong muốn của bạn, mô hình liên tục được học từ dữ liệu mới và có thể dữ liệu của bạn quá lớn đến mức không thể huấn luyện được mô hình cùng lúc với toàn bộ dữ liệu. Nhưng không phải ReInforcement Learning mà là Online learning. Cái này mình thấy rất hay nhưng không khuyên dùng trừ khi dữ liệu stream của bạn là lớn.
Time step trong NLP hiểu như thế nào là đúng?
Phạm Hữu Quang
Đã trả lời thg 11 23, 2018 1:04 CH
Khi bạn sử dụng các mạng hồi quy như RNN, LSTM, GRU về cơ bản trong mạng nó sẽ như thế này
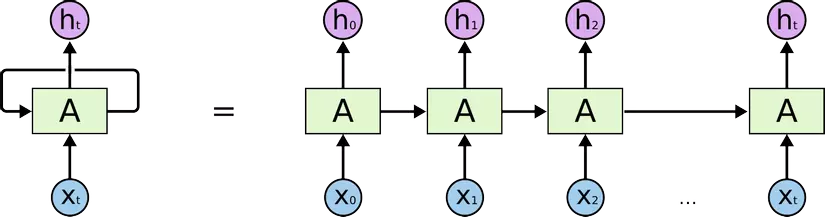 Trong đó, mỗi cái hình chữ nhật xanh kia là 1 time step, số lượng time step định nghĩa số lượng các lần lặp của mạng.
Trong đó, mỗi cái hình chữ nhật xanh kia là 1 time step, số lượng time step định nghĩa số lượng các lần lặp của mạng.
Còn trong dữ liệu, khi bạn feed dữ liệu dạng chuỗi vào mạng, bạn chia nhỏ chuỗi của bạn thành nhiều đoạn từ đầu chuỗi đến cuối chuỗi. Đấy chính là việc bạn chia dữ liệu thành các time step. Bạn muốn mỗi mẫu của bạn gồm bao nhiêu time step là do bạn định nghĩa. Ví dụ trong xử lý tín hiệu, mình có 1 đoạn tín hiệu dài 30s. Mình chia thành 10 time step tức là mỗi 1 step mình sẽ vector hóa 3s tín hiệu và mình có 10 cái step như thế.
Trong các nhiệm vụ khác của NLP, bạn có thể tùy ý định nghĩa các step này, tùy vào ý muốn của bạn. Ví dụ bạn có thể coi 1 câu gồm 1 chuỗi các ký tự, mỗi ký tự là 1 time step, hoặc bạn muốn mức cao hơn là coi 1 câu là 1 chuỗi các từ, bạn coi mỗi từ là 1 time step, hoặc có thể ở mức độ cao hơn là với câu,....
Tóm lại, mình cũng không biết cắt nghĩa từ time step thế nào cho chuẩn, mình chỉ hiểu khi xử lý dữ liệu dạng chuỗi, bạn có thể chia dữ liệu đấy thành các khoảng nhỏ để có thể sự dụng các mạng hồi quy cho chúng học sự phụ thuộc lẫn nhau theo thời gian, cái sau học từ cái trước. Ví dụ chia đoạn tín hiệu thành 1 nhóm các đoạn tín hiệu con, chia câu thành chuỗi các ký tự, chia câu thành chuỗi các từ, chia bức tranh con người vẽ thành chuỗi các nét vẽ,... tùy vào sự định nghĩa của bạn.
Cần sự góp ý về bài tập in ma trận trong C
Phạm Hữu Quang
Đã trả lời thg 11 21, 2018 2:44 SA
Mình viết tất cả trong hàm main, mong bạn hiểu code của mình 
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int size = 2*n -1;
int maxtrix[size][size];
// khoi tao gia tri goc tren trai
maxtrix[0][0] = n;
for(int i = 0; i < size; i++) {
for(int j = 0; j < size; j++) {
if(i <= j && j < size -i) {
maxtrix[i][j] = n - i;
}
else if(i < n) {
maxtrix[i][j] = maxtrix[i-1][j];
}
else {
maxtrix[i][j] = maxtrix[size - i - 1][j];
}
}
}
// In ra ma tran
for(int i = 0; i < size; i++) {
for(int j = 0; j < size; j++) {
cout << maxtrix[i][j] << ' ';
}
cout << '\n';
}
return 0;
}
Kết quả:
6
6 6 6 6 6 6 6 6 6 6 6
6 5 5 5 5 5 5 5 5 5 6
6 5 4 4 4 4 4 4 4 5 6
6 5 4 3 3 3 3 3 4 5 6
6 5 4 3 2 2 2 3 4 5 6
6 5 4 3 2 1 2 3 4 5 6
6 5 4 3 2 2 2 3 4 5 6
6 5 4 3 3 3 3 3 4 5 6
6 5 4 4 4 4 4 4 4 5 6
6 5 5 5 5 5 5 5 5 5 6
6 6 6 6 6 6 6 6 6 6 6
Xây dựng mô hình máy học sử dụng ít dữ liệu
Phạm Hữu Quang
Đã trả lời thg 11 16, 2018 9:50 SA
Mình nghĩ bạn nên code lại cho dễ nhìn hơn, hoặc thử lại với bộ dữ liệu mới vì ít dữ liệu thế kia thì mình không dám chắc bạn huấn luyện được gì.
Còn vấn đề là code của bạn sai ở đâu và làm thế nào để cho nó chạy.
Bạn có 40 ảnh trong thư mục train, 10 trong valid, bạn sử dụng ImageDataGenerator để cố gắng tạo được nhiều dữ liệu hơn. Và kết quả là bạn có 536 train và 100 valid.
Nhưng, label bạn lại vẫn lấy từ đống dữ liệu ban đầu với kích thước là nb_train_samples = 40, nb_validation_samples = 10 nên nó lỗi thôi. Khi bạn làm thêm dữ liệu thì bạn cũng phải thêm nhãn chứ.
Để code của bạn chạy được. Bạn sửa lại chỗ sinh label này.
Từ:
# Load data from saved bottleneck features
train_data = np.load(bottleneck_features_train_file)
train_labels = np.array([0] * (nb_train_samples // 2) + [1] * (nb_train_samples // 2))
validation_data = np.load(bottleneck_features_validation_file)
validation_labels = np.array([0] * (nb_validation_samples // 2) + [1] * (nb_validation_samples // 2))
Sửa thành:
# Load data from saved bottleneck features
train_data = np.load(bottleneck_features_train_file)
train_labels = np.array([0] * (train_data.shape[0] // 2) + [1] * (train_data.shape[0] // 2))
validation_data = np.load(bottleneck_features_validation_file)
validation_labels = np.array([0] * (validation_data.shape[0] // 2) + [1] * (validation_data.shape[0] // 2))
Kết quả sau 30 epoch :
Epoch 27/30
536/536 [==============================] - 0s 486us/step - loss: 0.6932 - acc: 0.4813 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 28/30
536/536 [==============================] - 0s 516us/step - loss: 0.6932 - acc: 0.4701 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 29/30
536/536 [==============================] - 0s 487us/step - loss: 0.6932 - acc: 0.4888 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 30/30
536/536 [==============================] - 0s 520us/step - loss: 0.6932 - acc: 0.5000 - val_loss: 0.6932 - val_acc: 0.5000
Bạn đang dùng OS/distro nào? Cảm thấy ra sao?
Phạm Hữu Quang
Đã trả lời thg 11 9, 2018 1:27 SA
Có một kỉ niệm rất vui của mình với Windows là khoảng 2 năm trước mình lên gặp thầy để báo cáo tiện độ project, do không lường trước để chuẩn bị, khi bật máy lên máy báo update, đợi khoảng 1.5h sau thì xong . Từ hôm đấy mình bỏ windowns đến tận bây giờ. Có thử qua Red Hat, CentOS và giờ mình dừng lại ở Ubuntu.
Trước đây thì điểm ngại của Ubuntu là không có SQL server, giờ cũng có rồi cũng bớt ngại(mà giờ mình cũng chẳng dùng ). Office thì mình dùng Office 365 online. Còn mỗi cái mấy phần mềm như photoshop, CAD thì nghe vẻ không được quan tâm (
Tóm lại mình ghét windows, mặc dù mình ngu Linux nhưng trải nghiệm trên Linux vẫn tốt hơn.
Chatbot : Dialogflow, Mongodb
Phạm Hữu Quang
Đã trả lời thg 10 31, 2018 3:26 CH
Mình đoán bạn đang tích hợp chatbot với facebook dựa vào hỗ trợ sẵn có của thằng dialogflow. Không biết bạn đã thử dựng 1 server sử dụng api của dialogflow rồi tích hợp server đấy với facebook chưa?
Khi mà mình dựng được server riêng biệt thì mình nghĩ việc lấy dữ liệu phản hồi từ bao nhiêu nguồn không thành vấn đề.
Nói vậy thôi chứ mình cũng chưa thử dùng phản hồi từ nhiều nguồn.
Bạn có thể xem cách dựng server bằng flask(python) rồi tích hợp với facebook tại đây: https://www.twilio.com/blog/2017/12/facebook-messenger-bot-python.html
Và cách sử dụng api của dialogflow trong python tại đây: https://www.pusher.com/tutorials/chatbot-flask-dialogflow/
Xin lỗi vì mình chỉ góp ý được với bạn đến vậy, mình không thể làm nên cũng k biết còn có khó khăn gì không và tính khả thi của nó.
Có khó khăn gì mong bạn tiếp tục trao đổi để những người khác vào góp ý thêm.
Lỗi Python Tool bị crash
Phạm Hữu Quang
Đã trả lời thg 10 12, 2018 12:33 CH
Mình có đọc issues này https://github.com/Microsoft/vscode-python/issues/2256 khá giống với lỗi bạn gặp phải.
Theo hướng dẫn thì bạn thử đi vào thư mục extension và xóa languageServer để kích hoạt 1 tải xuống mới. Bạn đã thử theo cách này chưa.
Deep Learning
Phạm Hữu Quang
Đã trả lời thg 10 4, 2018 10:43 SA
Mình sửa 1 số chỗ trong phần đầu code của bạn, bạn chạy lại thứ nhá.
import IPython.display as ipd
from scipy.io import wavfile
import os
import pandas as pd
import matplotlib.pyplot as plt
import random
import numpy as np
import time
import ast
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder
from keras.utils import np_utils
import re
#doc du lieu
temp1 = pd.read_csv('test.csv')
y1 = np.array(temp1.label.tolist())
X1 = np.array([ast.literal_eval(re.sub('\s+', ',', x)) for x in temp1.feature.tolist()])
lb = LabelEncoder()
y1 = np_utils.to_categorical(lb.fit_transform(y1))
#huan luyen mo hinh
num_labels = y1.shape[1]
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
model.fit(X1, y1, batch_size=32, epochs=200, validation_split=0.1, shuffle=True)
Những điều cơ bản về Hệ thống thông tin ?
Phạm Hữu Quang
Đã trả lời thg 10 3, 2018 12:46 SA
Mình không biết background của bạn là gì nhưng mình sẽ trả lời bạn theo đúng chương trình đào tạo chuyên ngành HTTT của trường mình, bạn có thể tìm hiểu theo. Theo mình thì các công việc của HTTT bao gồm thu thập thông tin, xử lý và lưu trữ, truy xuất thông tin, bạn có thể tìm hiểu 1 trong các phần đó cũng được.
- Kiến thức cơ bản: Kỹ thuật lập trình, cấu trúc dữ liệu và giải thuật, làm quen với hệ thống Linux.
- Các mô hình phân tích và thiết kế HTTT
- Kiến thức về CSDL, CSDL nâng cao: Tìm hiểu về các hệ quản trị CSDL quan hệ cơ bản(postgresql, mySQL, SQL server,...), cách thiết kế và quản trị CSDL(tối ưu hóa lưu trữ, tối ưu hóa truy vấn, tối ưu hóa index,...), các hệ quản trị CSDL noSQL(mongodb,...), CSDL đa phương tiện,...
- Các hệ phân tán, tính toán phân tán, xử lý dữ liệu phân tán, cân bằng tải(load balancing),...
- Tìm kiếm và trình diễn thông tin, tìm hiểu về các máy tìm kiếm như Elastic search, Solr,...
- Trí tuệ nhân tạo, hệ cơ sở tri thức, hệ trợ giúp quyết định, Machine learning, Data mining, Natural language processing
Về cơ bản chương trình đào tạo là vậy, còn mình thì bị trôi gần hết nên không dám nói thêm (
Làm sao để machine learning phân loại được văn bản
Phạm Hữu Quang
Đã trả lời thg 10 2, 2018 9:37 SA
Thực ra đây là 1 bài toán con trong bài toán Sentiment analysis nên mình muốn hỏi là bài toán của bạn là phát hiện những câu nói kháy, nói móc hoặc không hay là phân loại positive, negative và trong nhãn negative có 1 ít câu nói như thế này?
Về hướng giải quyết bài toán này thì bạn có thể thử theo 2 hướng:
- Classification theo các phương pháp học máy truyền thống như SVM, logistics regression, neural network,... Vấn đề quan trọng và cốt lõi ở đây là cách mà bạn feature extraction. Vì như bạn thấy, các bài toán như phân loại cảm xúc, phân loại tin tức,.. đều đưa về bài toán chung là phân loại vẳn bản. Điểm khác biệt và ảnh hưởng lớn tới model của bạn có tốt hay không là cách bạn lấy các feature. Ví dụ như bài toán phân loại cảm xúc thì mình có thể quan tâm nhiều tới tính từ, động từ hơn,..(Bạn sẽ phải quan tâm tới bài toán Part-of-speech tags) và trong các ví dụ của bạn, nếu feature trọng tâm được vào mấy từ như quá cơ, ai dám thì coi như bài toán này lại dễ. Quan trọng là việc feature extraction như vậy khá là khó và đòi hỏi nhiều kiến thức về NLP.
- Bạn có thể tham khảo bài báo này để xem cách các tác giả lấy các feature. https://arxiv.org/pdf/1804.00520.pdf. Ở đây tác giả có sử dụng các feature kết hợp như: Lexical features, POS tags, pre-trained model GloVe, Brown clustering,... Khá phức tạp nhưng thấy kết quả khá tốt, mình cũng chưa thử (.
- Với những bài toán feature extraction phức tạp và khó thì mình nghĩ hướng giải quyết tốt hơn và đơn giản hơn vẫn là sử dụng các mô hình Deep learning nhờ khả năng end-to-end và tự động trích chọn đặc trưng tốt phù hợp với bài toán, chỉ cần bạn có đủ dữ liệu thôi. Bạn có thể thử qua các kiến trúc phổ biến như CNN, LSTM hoặc cũng có thể kết hợp cả hai. Mình đã có 1 thí nghiệm với bài toán Sentiment analysis thì được kết quả kết hợp tốt hơn khi sử dụng 2 mô hình trên độc lập. Bạn có thể tham khảo kiến trúc này của mình
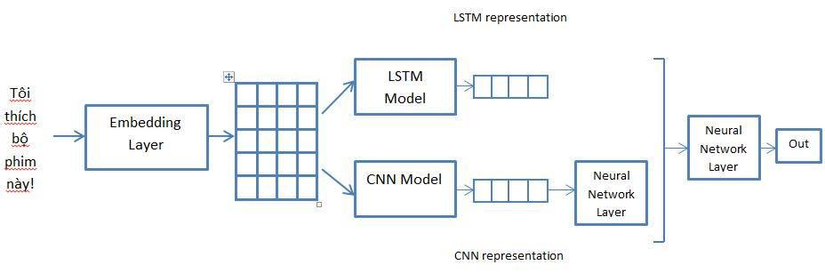
Hy vọng sẽ có những trao đổi thêm của bạn về bài toán này.
Công cụ để quét lỗ hổng bảo mật cho website tự động?
Phạm Hữu Quang
Đã trả lời thg 9 30, 2018 3:08 CH
bạn thử đọc qua bài này xem https://geekflare.com/online-scan-website-security-vulnerabilities/
Hỏi cách tạo folder tree structure
Phạm Hữu Quang
Đã trả lời thg 9 25, 2018 3:32 SA
Nếu bạn muốn sử dụng phần mềm kéo thả để tạo 1 hình ảnh đẹp(cho vào trong báo cáo), thì sao không thử Microsoft Visio trong bộ Office nhỉ. Trước mình cũng vẽ cái này bằng Visio để cho vào trong báo cáo )
ko hiểu cách Biểu diễn giá trị Trong ngôn ngữ C
Phạm Hữu Quang
Đã trả lời thg 9 15, 2018 3:14 CH
Nó định nghĩa 1 hằng số có tên là P_TOA, có giá trị bằng 128. 0x ở đây là biểu diễn của hệ cơ số 16, hệ thập lục phân.
$ 0x80 = 816^1 + 016^0 = 128 $

