0
Làm sao để machine learning phân loại được văn bản
Mình đang gặp khó khăn trong bài toán phân loại văn bản.
Đó là vấn đề phân loại theo nghữ nghĩa.
Rất mong các anh/chị/bạn có kinh nghiệm có thể chia sẻ hướng giải quyết giúp mình ạ.
Một số ví dụ(Dấu + là tích cực, - là tiêu cực):
- (+) Các anh cs dũng cảm quá
- (-) Các anh cs dũng cảm quá cơ
- (-) GƯƠNG SÁNG PHỐ PHƯỜNG (biển) mà mấy ai dám noi.
Mình cảm ơn ạ.
Thêm một bình luận
1 CÂU TRẢ LỜI
+2
Thực ra đây là 1 bài toán con trong bài toán Sentiment analysis nên mình muốn hỏi là bài toán của bạn là phát hiện những câu nói kháy, nói móc hoặc không hay là phân loại positive, negative và trong nhãn negative có 1 ít câu nói như thế này?
Về hướng giải quyết bài toán này thì bạn có thể thử theo 2 hướng:
- Classification theo các phương pháp học máy truyền thống như SVM, logistics regression, neural network,... Vấn đề quan trọng và cốt lõi ở đây là cách mà bạn feature extraction. Vì như bạn thấy, các bài toán như phân loại cảm xúc, phân loại tin tức,.. đều đưa về bài toán chung là phân loại vẳn bản. Điểm khác biệt và ảnh hưởng lớn tới model của bạn có tốt hay không là cách bạn lấy các feature. Ví dụ như bài toán phân loại cảm xúc thì mình có thể quan tâm nhiều tới tính từ, động từ hơn,..(Bạn sẽ phải quan tâm tới bài toán Part-of-speech tags) và trong các ví dụ của bạn, nếu feature trọng tâm được vào mấy từ như quá cơ, ai dám thì coi như bài toán này lại dễ. Quan trọng là việc feature extraction như vậy khá là khó và đòi hỏi nhiều kiến thức về NLP.
- Bạn có thể tham khảo bài báo này để xem cách các tác giả lấy các feature. https://arxiv.org/pdf/1804.00520.pdf. Ở đây tác giả có sử dụng các feature kết hợp như: Lexical features, POS tags, pre-trained model GloVe, Brown clustering,... Khá phức tạp nhưng thấy kết quả khá tốt, mình cũng chưa thử
 (.
(.
- Với những bài toán feature extraction phức tạp và khó thì mình nghĩ hướng giải quyết tốt hơn và đơn giản hơn vẫn là sử dụng các mô hình Deep learning nhờ khả năng end-to-end và tự động trích chọn đặc trưng tốt phù hợp với bài toán, chỉ cần bạn có đủ dữ liệu thôi. Bạn có thể thử qua các kiến trúc phổ biến như CNN, LSTM hoặc cũng có thể kết hợp cả hai. Mình đã có 1 thí nghiệm với bài toán Sentiment analysis thì được kết quả kết hợp tốt hơn khi sử dụng 2 mô hình trên độc lập. Bạn có thể tham khảo kiến trúc này của mình
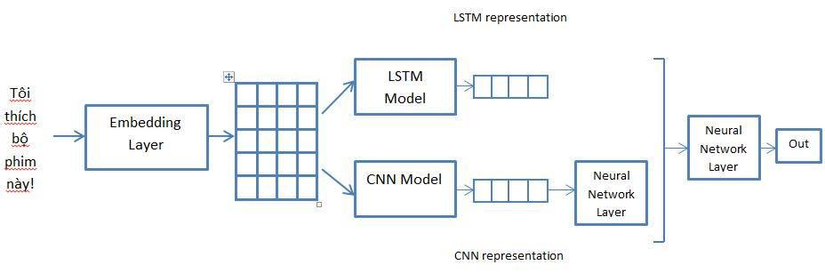
Hy vọng sẽ có những trao đổi thêm của bạn về bài toán này.
Hiện tại, dữ liệu của mình có khá nhiều dạng irony, sarcasm và đa số là tiêu cực. Mình đang mong muốn phát hiện chúng trước khi đưa vào mô hình sentiments phân loại tích cực/ tiêu cực.
Về gợi ý của bạn:
Mình cũng đọc và tìm hiểu cách lấy đặc trưng theo bài báo của nhóm anh Xuan-Son Vu. Về cơ bản cũng đã hiểu cách làm.
Mình thấy kết quả của bài báo đạt được ~ 70%, không biết đã đạt ngưỡng state-of-the-art hay chưa?
(Mình thấy hơi thấp, deploy e là chưa ổn)
Tuy nhiên, hiện tại do vẫn đang thiếu dữ liệu nên chưa thử được.
Do vậy, mình vẫn muốn đăng câu hỏi nên để trao đổi thêm coi có cách nào khác không.
Với cách thứ 2, có lẽ sẽ là hướng mới để tiếp cận, mình sẽ tìm hiểu tiếp. Do bản thân mới chỉ bắt đầu nên cũng chưa có nhiều kiến thức về DL.
Rất cảm ơn chia sẻ bổ ích của bạn.
Nhóm anh Sơn làm trên dataset tiếng Anh nên mình chưa rõ nhưng nếu làm trên tiếng Việt thì trên 70% là khá ổn vì tiếng Việt mình nhiều điểm dị hơn và các bài toán core NLP kết quả vẫn chưa tốt bằng.
Nếu chuẩn bị dữ liệu tốt rồi bạn nên thử Deep learning, có lẽ sẽ tốt hơn.
