Tự động tăng khả năng chịu tải với Horizontal Pod Autoscaling trong Kubernetes
Bài đăng này đã không được cập nhật trong 2 năm
Hello các bạn, vẫn lại là mình đây 😎😎
Hôm nay ta lại tiếp nối series k8s căng não nhé 🧠🧠. Hi vọng các bạn đã thẩm được bài trước về Nginx Ingress và Cert Manager 💪
Ở bài này chúng ta sẽ cùng nhau tìm hiểu và cấu hình Horizontal Pod Autoscaling trên K8S để có thể tự động scale app từ đó tăng độ chịu tải nhé 
Lại lên thuyền thôi ae ơiiii 🚢🚢
Tổng quan
Ở bài này ta sẽ deploy một app tính số Fibonacci như sau:

Ở bài này ta sẽ thực hiện 1 cái fake DDoS vào server để yêu cầu tính số Fibonacci, và vì quá trình tính toán này khá tốn CPU, nên sẽ làm tăng tải và làm performance của server kém đi, UI sẽ bị delay và lag, nhưng với Horizontal Pod Autoscaling thì K8S sẽ tự động scale app của chúng ta lên để có thể chịu được tải nhiều hơn (nghe có vẻ hấp dẫn rồi đấy 😎)
Let's goooooooooooooooooo 🚀🚀🚀
À từ giờ ta gọi tắt Horizontal Pod Autoscaling = HPA nhé, chứ tên kia dài quá 😂
Lấy session
Vẫn như mọi khi, các bạn nhớ lấy session truy cập cluster k8s của mình nhé: https://learnk8s.jamesisme.com/
Deploy app
Bước đầu tiên là ta sẽ deploy app lên xem như thế nào đã nha. Đầu tiên ta cần tạo folder riêng để chứa code cho bài này, các bạn tuỳ chọn nhé.
Sau đó các bạn tạo cho mình file deployment.yml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app.kubernetes.io/name: viblo-k8s-hpa
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-hpa:latest
ports:
- containerPort: 3000
name: pod-http
resources:
requests:
memory: "128Mi"
cpu: "64m"
limits:
memory: "512Mi"
cpu: "250m"
Sau đó ta tiếp tục tạo file svc.yml:
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
type: LoadBalancer
ports:
- name: svc-http
protocol: TCP
port: 80
targetPort: pod-http
selector:
app: myapp
Hi vọng là đến bài này các bạn đều thẩm được những gì mình viết ở 2 file manifest bên trên nha 😎😎 (chưa hiểu thì comment cho mình nhé)
Sau khi tạo xong thì folder của chúng ta sẽ trông như sau:
Sau đó ta apply:
kubectl apply -f . --kubeconfig=./kubernetes-config
Ở trên ta apply tất cả các file manifest ở folder hiện tại, dùng dấu chấm .
Sau đó ta get service xem EXTERNAL-IP đã lên chưa nhé:
kubectl get svc --kubeconfig=./kubernetes-config
--->>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp LoadBalancer 10.245.15.9 <pending> 80:32120/TCP 2s
Ở trên của mình vẫn <pending>, thường ta phải chờ vài phút để LB được tạo trên cloud nhé, thong thả làm cốc cà phê nha ☕️
À nhân tiện ta check xem hiện tại thì deployment của chúng ta ăn CPU/RAM như nào nào:
kubectl top po --kubeconfig=./kubernetes-config
--->>
NAME CPU(cores) MEMORY(bytes)
myapp-7c68cd8585-lpp58 1m 21Mi
Nếu các bạn gặp lỗi
error: metrics not available yetthì là do Deployment chưa READY nhé, chờ tẹo nha
Như các bạn thấy thì ta chưa có dùng gì cả nên là lượng sử dụng rất thấp CPU chỉ là 1 mili core
Chờ vài phút check lại service và ta sẽ thấy có EXTERNAL-IP nhé:
kubectl get svc --kubeconfig=./kubernetes-config
-->>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp LoadBalancer 10.245.15.9 144.126.243.237 80:32120/TCP 2m50s
Sau đó ta mở trình duyệt ở địa chỉ http://144.126.243.237 (thay IP vào cho đúng với LB của các bạn nhé):
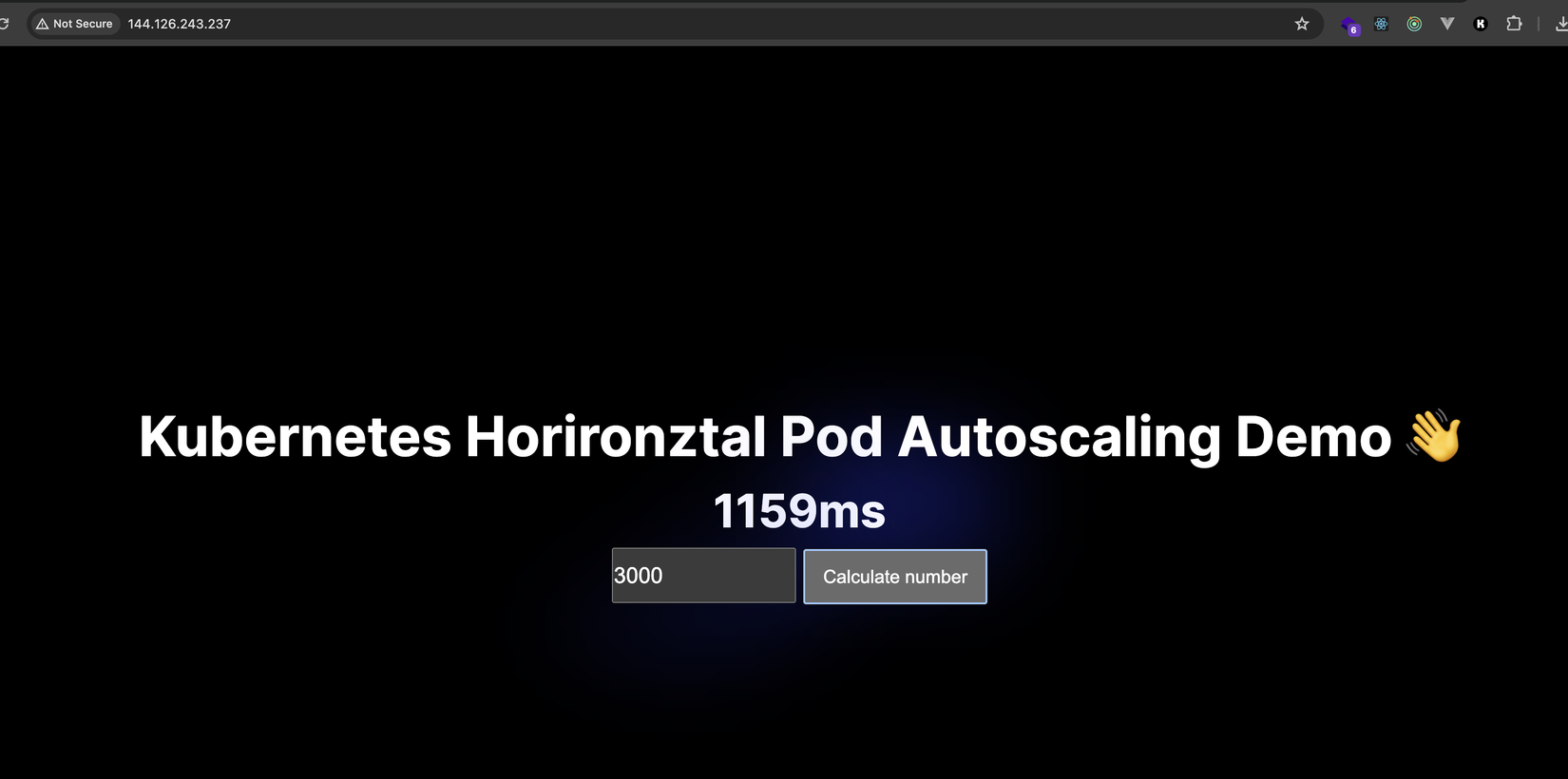
Pòm 🎇🎇, lên gòi
Thử bấm nút Calculate number với iterations=3000 xem thế nào nha (đừng để số lớn quá không nó treo mất đó các bạn à 😂😂)
Sau khi click calculate thì khi nhận được response ta in ra thời gian từ lúc bấm nút đến khi nhận được kết quả là bao lâu, như trên hình của mình là 1159ms
Các bạn bấm thêm vài lần để xem nó như nào nhé, của mình là loanh quanh <= 1200ms, kể cả thời gian F5 trang cũng rất nhanh
Fake Traffic
Oke giờ ta sẽ chạy script để tạo traffic làm quá tải phía server xem nhé. Các bạn cần cài Docker nha
Ta chạy command sau (thay EXTERNAL-IP của service của các bạn vào cho đúng nhé):
docker run -it --rm --name load-generator busybox:1.28 sh -c "while sleep 0.01; do wget -q -O- http://144.126.243.237/api/hello?iterations=3000; done"
Chờ một lúc và sau đó ta quay lại trình duyệt F5 vài lần, ta sẽ để ý thấy rằng thời gian load trang đã lâu hơn thấy rõ, bấm Calculate number sẽ thấy response chậm hơn:

Check resource mà app của chúng ta đang sử dụng cũng đã thấy chạm limit:
kubectl top po --kubeconfig=./kubernetes-config
NAME CPU(cores) MEMORY(bytes)
myapp-7c68cd8585-jbc4h 250m 39Mi
Giờ ta tắt terminal mà đang chạy traffic đi, sửa lại cho nặng đô hơn nữa, để iterations=4000 luôn 😈😈:
docker run -it --rm --name load-generator busybox:1.28 sh -c "while sleep 0.01; do wget -q -O- http://144.126.243.237/api/hello?iterations=4000; done"
Quay lại trình duyệt F5 và thấy càng rõ sự delay khi load trang, bấm button thì rất lâu mới trả về:
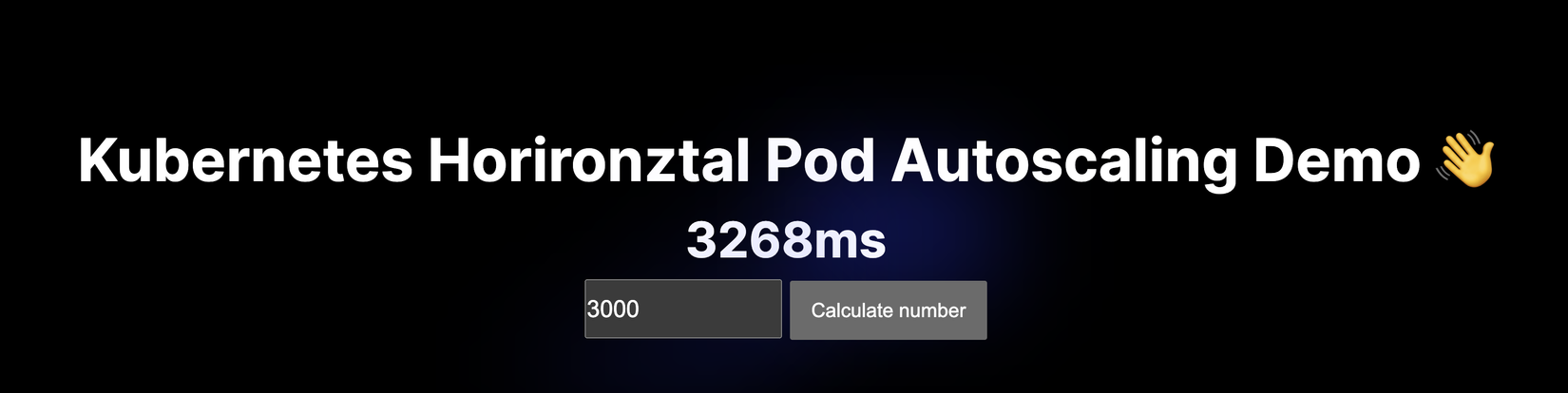
Check resource thì còn qúa cả limit 250m 1 chút:
kubectl top po --kubeconfig=./kubernetes-config
NAME CPU(cores) MEMORY(bytes)
myapp-7c68cd8585-jbc4h 252m 40Mi
Scale bằng tay 💪
Âu cây và giờ ta sẽ ra tay cứu app của chúng ta chứ không nó "khổ" quá rồi, 😂😂
Ta sẽ tăng lên làm 2 replicas nhé:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app.kubernetes.io/name: viblo-k8s-hpa
spec:
replicas: 2 # ---> sửa ở đây
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-hpa:latest
ports:
- containerPort: 3000
name: pod-http
resources:
requests:
memory: "128Mi"
cpu: "64m"
limits:
memory: "512Mi"
cpu: "250m"
Sau đó ta apply lại:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
Chờ một lúc để K8S điều phối dần traffic về Pod mới được sinh ra, và kiểm tra lại ta sẽ thấy rằng resource sử dụng đã có vẻ cân bằng và ổn định hơn:
kubectl top po --kubeconfig=./kubernetes-config
NAME CPU(cores) MEMORY(bytes)
myapp-7c68cd8585-jbc4h 158m 39Mi
myapp-7c68cd8585-t4c85 141m 30Mi
Quay lại trình duyệt F5 và bấm Calculate cũng thấy đã nhanh như thường rồi
Vậy giờ ta mở thêm 1 terminal chạy song song 1 quả tạo traffic khác nữa thì sao ta? 🙄
Thì lại đi chứ còn gì nữa các bạn 🤪
Vậy không lẽ mình lại phải ngồi trực để bao giờ nó tăng thì mình tăng replicas lên tiếp, vậy thì nhọc lắm 🥲🥲
Oke thế thì tự động thôi 🚀
Scale tự động với HPA
Đầu tiên là các bạn đóng terminal đang chạy fake traffic đi đã nha 
Vertical vs Horizontal Scale
Đầu tiên ta cần xem qua tí lý thuyết vỡ lòng nha 📖📖
Có 2 kiểu scale phổ biến đó là: Vertical scale và Horizontal scale (scale theo chiều dọc/chiều ngang).
Ta xem hình dưới:
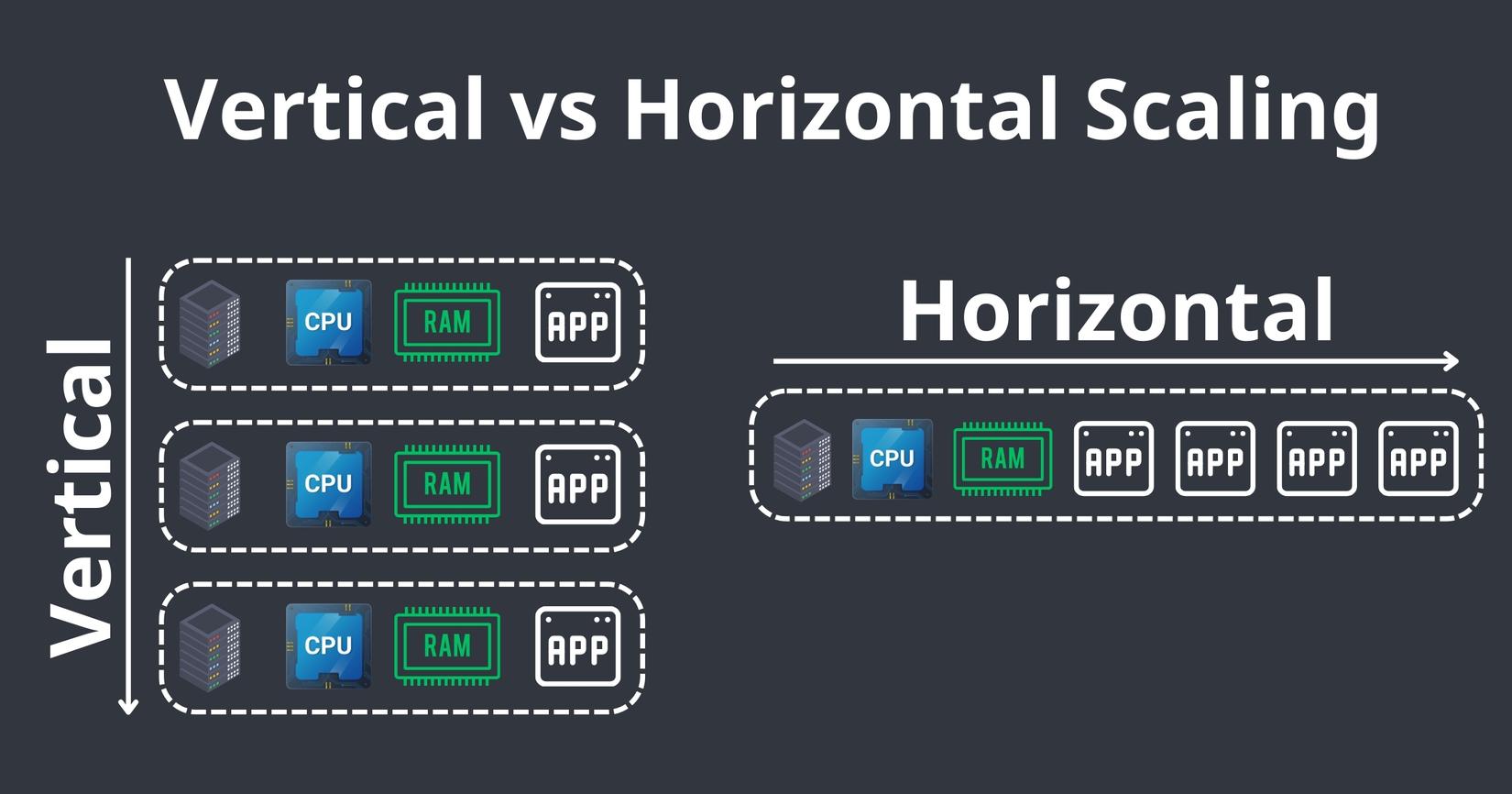
Ở trên ta có thể thấy rõ là scale theo chiều dọc là ta sẽ tăng thêm phần cứng như RAM/CPU hoặc thêm nhiều node server. Còn scale theo chiều ngang là ta sẽ tăng lên nhiều instance app của chúng ta, với mục đích là tận dụng hết tài nguyên có ở trên 1 node/server
Lấy ví dụ như app NodeJS chẳng hạn, chúng ta đều biết NodeJS là single-threaded, tức là 1 app nó chỉ chạy trên 1 thread, vậy thì bằng việc scale theo chiều ngang ta có thể có nhiều instance chạy trên nhiều thread khác nhau
Tất nhiên là scale theo chiều ngang thì nó cũng sẽ tới hạn khi ta dùng hết resource trên node hiện tại, và khi đó ta cần tới vertical scale
Bởi vì việc scale theo chiều dọc (vertical scale) là ta sẽ mua thêm (hoặc gán thêm) resouce, việc này nằm ngoài phạm vi của K8S nên ta nếu xem docs ta chỉ thấy nói về horizontal scale, nhưng thực tế là k8s có module cho vertical scale, và ta cần tự cài đặt nó vào cluster.
Vậy nhưng như mình nói từ đầu series, thông thường ta sẽ không tự vận hành 1 K8S cluster vì sẽ có rất nhiều vấn đề ta phải xử lý, mà ta sẽ dùng luôn managed k8s của cloud provider, như ở series này mình dùng của Digital Ocean, thì họ sẽ có tính năng cấu hình vertical scale trực tiếp trên website của họ luôn:
Trong series này dùng cluster cùi cùi của mình nên ta mặc định sẽ không nói tới vertical scale nhé, bao giờ mình giàu và thích làm từ thiện thì tính sau 🤣🤣
Horizontal Pod Autoscaler (HPA)
HPA là 1 loại resource trên K8S, nó sẽ tự động update workload (ví dụ: Deployment) sao cho phù hợp.
HPA sẽ tự động scale up số Pod để tăng thêm tải hoặc scale down để giảm số Pod không cần thiết, dựa vào các chỉ số như CPU/RAM hoặc bất kì loại metrics nào mà ta cấu hình
Cách HPA hoạt động thì ta xem ở hình dưới nhé:
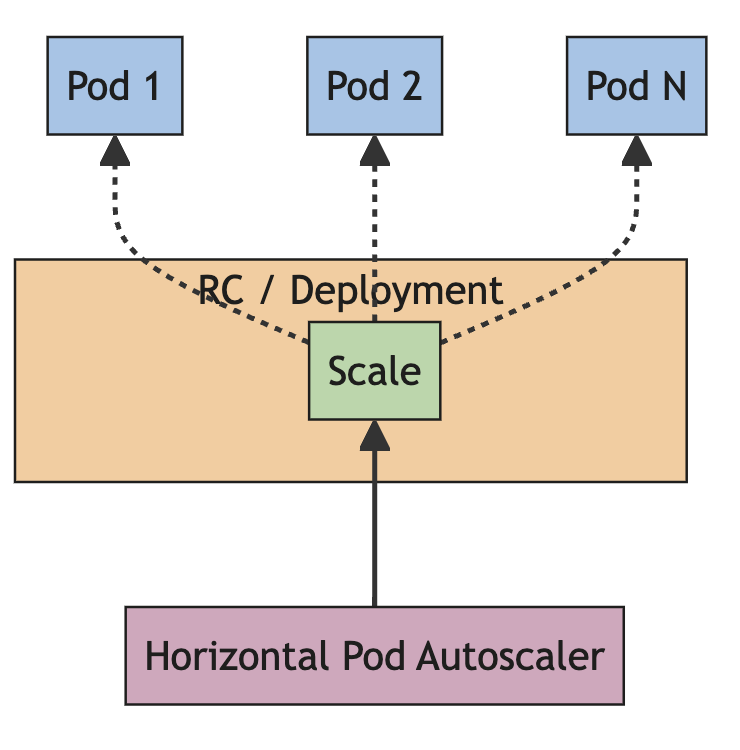
Về cơ bản thì HPA nó chạy như 1 cái control loop, liên tục fetch metrics từ các Pod, và dựa vào cấu hình của ta cho HPA, nó sẽ từ đó tính toán và ra quyết định rằng có nên scale up/down để phù hợp với nhu cầu hay không. Nếu bạn muốn hiểu sâu hơn về HPA thì xem thêm ở đây nhé
Lý thuyết nhẹ nhàng vậy, zô thực hành để xem đầu đuôi nó như nào nào ...💪
Cấu hình HPA
Trong bài ngày hôm nay ta sẽ scale dựa trên 2 thông số cơ bản nhất là CPU và RAM nhé.
Trước khi ta cấu hình HPA thì ta sẽ check resourcequota cho namespace mà ta có là bao nhiêu đã nha:
kubectl get resourcequota --kubeconfig=./kubernetes-config
-->>
NAME AGE REQUEST LIMIT
lk8s-709059 118m configmaps: 1/5, cpu: 128m/1500m, ephemeral-storage: 0/5Gi, memory: 256Mi/2Gi, persistentvolumeclaims: 0/5, pods: 2/5, replicationcontrollers: 0/5, secrets: 12/20, services: 1/5, services.loadbalancers: 1/1, services.nodeports: 1/1
Ở trên các bạn thấy là ta có tối đa 1500m CPU và 2Gi RAM. Vậy thì lát nữa ta sẽ cấu hình mỗi Pod có limit là 250m CPU / 300 Mi RAM nhé (trong thực tế thì tuỳ ta chọn 1 con số cho phù hợp)
Với con số đã chọn ở trên thì ta có thể có tối đa là 6 Pods
Đầu tiên các bạn sửa lại file deployment.yml như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app.kubernetes.io/name: viblo-k8s-hpa
spec:
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-hpa:latest
ports:
- containerPort: 3000
name: pod-http
resources:
requests:
memory: "128Mi"
cpu: "128m"
limits:
memory: "300Mi"
cpu: "250m"
Tiếp đó, tạo cho mình file hpa.yml như sau:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 6
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Ở trên ta cấu hình HPA với target là deployment myapp, số pod tối thiểu là 1 và max là 6 (Ta có thể để max cao hơn cũng được nhưng sẽ không đủ resource)
HPA sẽ scale dựa vào metrics, nó là 1 array, tức là ta có thể khai báo nhiều metrics để HPA nó tham chiếu, ở đây hiện tại ta dùng CPU thôi, và mức mà ta mong muốn là độ tiêu thụ CPU ở mức 70%.
Bởi vì mỗi Pod ta đang khai báo ở file deployment.yml mỗi Pod đang request là 128m CPU. Do vậy mức trung bình CPU mà ta target tới là 70% của 128m = 89.6m CPU, và HPA sẽ scale up/down số Pod sao cho thoả mãn điều kiện của chúng ta <= 89.6m CPU (các bạn có thể xem thêm chi tiết về công thức HPA tính toán ở đây)
Mình tăng request lên chút chứ
64mban đầu thì target là44.8mnó hơi khó demo

Oke rồi giờ ta apply deployment và HPA nhé:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
kubectl apply -f hpa.yml --kubeconfig=./kubernetes-config
Sau đó ta get xem HPA như nào nha:
kubectl get hpa --kubeconfig=./kubernetes-config
--->>
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-hpa Deployment/myapp 0%/70% 1 6 1 15s
Vì hiện tại đang không có tí traffic nào nên HPA báo là trung bình ta dùng 0%, thử xem resource mà pod đang sử dụng thì cũng thấy rất ít:
kubectl top po --kubeconfig=./kubernetes-config
------>>
NAME CPU(cores) MEMORY(bytes)
myapp-5b8bd895bf-pbj8m 2m 26Mi
Giờ ta lại chạy script để fake traffic tiếp và theo dõi nhé, nhưng lần này ta dùng iterations=4000 cho nặng đô tí nha:
docker run -it --rm --name load-generator busybox:1.28 sh -c "while sleep 0.01; do wget -q -O- http://144.126.243.237/api/hello?iterations=4000; done"
Sau đó ta set get HPA và watch xem nó thay đổi như thế nào nha:
kubectl get hpa --kubeconfig=./kubernetes-config --watch
----->>>
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-hpa Deployment/myapp 0%/70% 1 6 1 5h9m
myapp-hpa Deployment/myapp 115%/70% 1 6 1 5h9m
myapp-hpa Deployment/myapp 195%/70% 1 6 2 5h9m
myapp-hpa Deployment/myapp 130%/70% 1 6 3 5h10m
myapp-hpa Deployment/myapp 175%/70% 1 6 4 5h10m
myapp-hpa Deployment/myapp 53%/70% 1 6 5 5h10m
myapp-hpa Deployment/myapp 75%/70% 1 6 5 5h10m
myapp-hpa Deployment/myapp 46%/70% 1 6 5 5h11m
myapp-hpa Deployment/myapp 30%/70% 1 6 5 5h11m
Như các bạn thấy ở trên thì khi traffic tăng cao thì số pod tăng từ 1->5, để đảm bảo rằng lượng CPU tiêu tốn nhỏ hơn 70% như ta đã cấu hình.
Trong quãng thời gian này ta lại check trên trình duyệt F5 + bấm Calculate, sẽ thấy đoạn đầu khi quá tải thì khá là lag, nhưng 1 lúc khi HPA scale số pod lên thì trang web dần dần nhanh trở lại
Bây giờ các bạn đóng terminal nơi đang chạy fake traffic đi nhé, để xem HPA sẽ như nào nha:
kubectl get hpa --kubeconfig=./kubernetes-config --watch
--->>>
myapp-hpa Deployment/myapp 46%/70% 1 6 5 5h11m
myapp-hpa Deployment/myapp 30%/70% 1 6 5 5h11m
myapp-hpa Deployment/myapp 32%/70% 1 6 5 5h11m
myapp-hpa Deployment/myapp 50%/70% 1 6 5 5h11m
myapp-hpa Deployment/myapp 44%/70% 1 6 5 5h12m
myapp-hpa Deployment/myapp 11%/70% 1 6 5 5h12m
myapp-hpa Deployment/myapp 1%/70% 1 6 5 5h12m
myapp-hpa Deployment/myapp 1%/70% 1 6 5 5h12m
myapp-hpa Deployment/myapp 0%/70% 1 6 5 5h13m
myapp-hpa Deployment/myapp 5%/70% 1 6 5 5h13m
myapp-hpa Deployment/myapp 1%/70% 1 6 5 5h13m
myapp-hpa Deployment/myapp 0%/70% 1 6 5 5h14m
myapp-hpa Deployment/myapp 0%/70% 1 6 5 5h14m
myapp-hpa Deployment/myapp 0%/70% 1 6 5 5h14m
myapp-hpa Deployment/myapp 1%/70% 1 6 5 5h15m
myapp-hpa Deployment/myapp 0%/70% 1 6 5 5h15m
myapp-hpa Deployment/myapp 0%/70% 1 6 4 5h16m
myapp-hpa Deployment/myapp 0%/70% 1 6 4 5h17m
myapp-hpa Deployment/myapp 0%/70% 1 6 1 5h17m
myapp-hpa Deployment/myapp 1%/70% 1 6 1 5h17m
myapp-hpa Deployment/myapp 0%/70% 1 6 1 5h18m
Ở trên các bạn thấy là sau chừng hơn 5 phút khi HPA thấy rằng có "ổn" thì nó mới bắt đầu scale số Pod xuống từ 5 xuống còn 1, chứ nó không làm ngay lập tức, vì nhỡ traffic xuống và lại lên ngay thì sao, cũng "khôn" đó nhỉ 👏
Vọc vạch
Tăng tốc độ scale down
Như các bạn thấy ở trên, đoạn scale down trong trường hợp demo này khá dài, thì ta có thể sửa nó nhanh hơn chút với những cấu hình như sau:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 6
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
scaleDown:
policies:
- periodSeconds: 60
type: Pods
value: 3
- type: Percent
value: 50
periodSeconds: 60
stabilizationWindowSeconds: 200
Ở trên ta có stabilizationWindowSeconds nó là khoảng thời gian "bình ổn", tức là sau khi HPA thấy lượng tiêu thụ CPU đã ổn trong 1 khoảng thời gian thì nó sẽ tiến hành scale xuống
Còn đoạn policies như ở trên là cho phép scale xuống tối đa 3 pods trong 60 giây (1 phút) và tối đa 50% số Pods trong 60 giây
Thực tế thì ta cần phải cân nhắc và đưa ra 1 con số phù hợp nhất cho những thông số trên, vì nếu dài quá thì tốn resource, mà ngắn quá thì vừa scale down traffic lại tăng vọt 😂
Traffic quá tải vượt giới hạn
Như các bạn thấy trong bài mình để maxReplicas=6, khi ta demo fake traffic thì đã phải dùng tới 5 replicas rồi, vậy nếu giờ ta mở tiếp 1 terminal nữa, tức là 2 terminals fake traffic liên tục vào server thì sao? 🙄🙄
Các bạn thử xem . Để ý tốc độ F5 trên trình duyệt + bấm Calculate xem có lag không nhé, đồng thời cũng check top po và watch hpa xem là nó như nào rồi có gì comment cho mình biết với nha😎
Tính toán dựa vào custom metrics
HPA mặc định support các thông số khá cơ bản như CPU với RAM, vậy giờ ta muốn tính toán scale dựa vào những metrics khá là custom, ví dụ:
- mỗi pod chỉ xử lý được 1 video tại 1 thời điểm, không cần biết CPU hay RAM như thế nào, vậy giờ user cứ submit 1 video lên thì cần thêm 1 Pod
- khi service xử lý đơn nhận 1000 đơn thì phải scale service giao hàng lên trước để chuẩn bị nhận 1000 đơn kia,...
K8S có support, nhưng ta cần phải implement chút mới dùng được, cái này ta check thêm ở đây nhé
Thân ái
Hi vọng bài này đủ ngắn để các bạn có thể thong thả thẩm nó từ từ 🤣🤣
Như ta thấy thì k8s có nhiều thứ hay ho v~ chưởng, toàn tự động hết, mong là các bạn đã hiểu sơ bộ cách HPA hoạt động và cấu hình để HPA scale up/down khi có biến động traffic đi vào app của chúng ta.
Về HPA thìcos rất nhiều cách cấu hình, triển khai, các bạn tha hồ vọc vạch, có gì thì comment cho mình biết nhé.
Cám ơn các bạn đã theo dõi, hẹn gặp lại các bạn vào những bài sau 👋
All rights reserved
