
Cấu hình cụm Kubernetes để sử dụng Nvidia GPU
Bài đăng này đã không được cập nhật trong 3 năm
Là một nền tảng mã nguồn mở để tự động hóa việc triển khai, scaling và quản lý các ứng dụng đã được container hóa, Kubernetes thường được lựa chọn để triển khai các web service nói chung và trong đó bao gồm cả các ứng dụng có sử dụng các mô hình ML. Trên cơ sở đó, trong bài viết này, chúng ta sẽ cùng tìm hiểu về cách các thành phần của Kubernetes tương tác với Nvidia GPU cũng như thực hành với một cụm k8s đơn giản.
Ok nẹt gâu (((o(*°▽°*)o)))
Nvidia GPU trên Kubernetes
Chi tiết về Kubernetes thì trên Viblo cũng khá nhiều bài viết về nó chẳng hạn như bài viết Kubernetes là gì? hay bài viết Tổng quan về kiến trúc của Kubernetes của mình nên nội dung bài viết này sẽ không giới thiệu lại về nó nữa. Tuy vậy ta cũng nên recap một chút là Kubernetes quản lý các đơn vị của nó được gọi là các Pod được thiết kể để mô phỏng các máy chủ logic dành riêng cho ứng dụng và có thể chứa các ứng dụng containers khác nhau được liên kết tương đối chặt chẽ. Các containers trong một Pod chia sẻ một địa chỉ IP và port space, chúng luôn được đặt cùng vị trí, cùng lên lịch trình, và chạy trong context được chia sẻ trên cùng một Node .
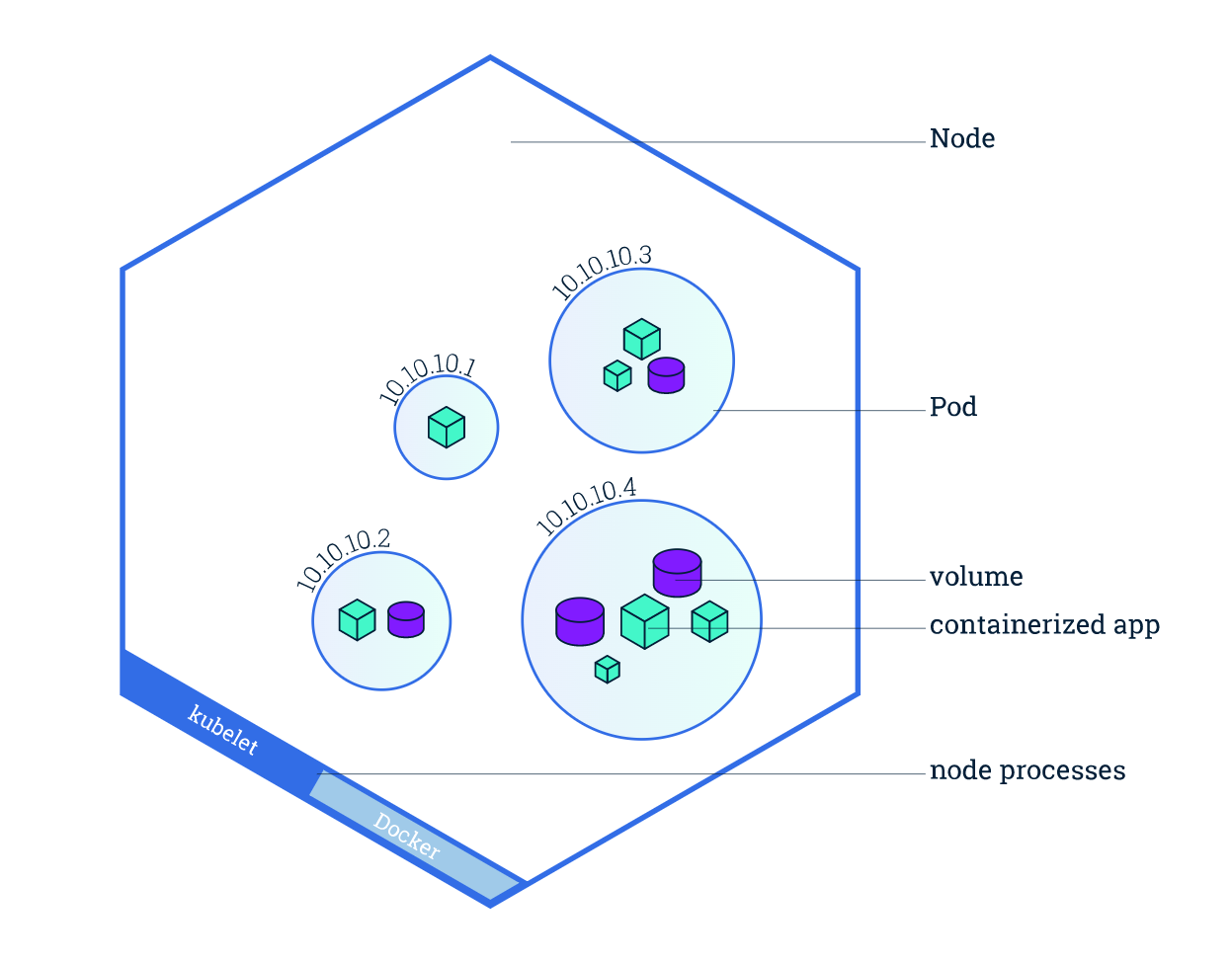
Hình ảnh được sử dụng từ https://kubernetes.io/vi/docs/tutorials/kubernetes-basics/explore/explore-intro/
Việc dựng một cụm Kubernetes để thử nghiệm khá đơn giản, khi ta có thể sử dụng cài đặt k3s thông qua một câu lệnh duy nhất như sau:
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server --no-deploy traefik" sh
Cho các bạn thắc mắc một chút thì ở đây mình không triển khai traefik vì Ingress này không phổ biến cho lắm, sau test các tool khác chẳng hạn Seldon Core thì lại phải gỡ ra trước nên mình sẽ không cài luôn từ đầu ┐( ̄ヮ ̄)┌. Trong demo này thì mình sẽ có một cụm có 2 node đó là vì máy mình không có GPU còn máy khác thì mới có (¬_¬;) Việc cài đặt một node mới và thêm nó vào cụm sẽ được thực hiện dễ dàng thông qua câu lệnh curl -sfL https://get.k3s.io | K3S_URL=https://10.0.37.144:6443 K3S_TOKEN=$K3S_TOKEN sh - với giá trị của K3S_TOKEN được lấy từ /var/lib/rancher/k3s/server/node-token trên node master. Nếu bạn không quá đen thì kết quả nó sẽ trông như thế này:
% kubectl get nodes
NAME STATUS ROLES AGE VERSION
b122436-pc Ready control-plane,master 5m42s v1.24.6+k3s1
b120639-pc3 Ready <none> 2m25s v1.24.6+k3s1
Ở đây ta có node b120639-pc3 sẽ là node có GPU còn node b122436-pc là con máy ghẻ của mình (;⌣̀_⌣́) Vậy để thử với xem một cụm k8s mặc định có sử dụng được Nvidia GPU không, ta thử triển khai một pod có nội dung chuẩn chỉ như sách giáo khoa, việc phải để trường requests trong manifest do GPU luôn là resource đặc biệt nên không xin thì còn lâu mới có mà dùng:
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvcr.io/nvidia/cloud-native/gpu-operator-validator:v22.9.0"
resources:
limits:
nvidia.com/gpu: 1
Sẽ thật tốt khi nó ok luôn nhưng cuộc sống thì không dễ dàng như vậy =)))))))) (chứ nếu không tôi viết bài này làm gì) mà ta sẽ thu được kết quả như sau:
% kubectl get event --field-selector involvedObject.name=gpu-operator-test
LAST SEEN TYPE REASON OBJECT MESSAGE
9m3s Warning FailedScheduling pod/gpu-operator-test 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.
8m45s Warning FailedScheduling pod/gpu-operator-test skip schedule deleting pod: default/gpu-operator-test
8m43s Normal Scheduled pod/gpu-operator-test Successfully assigned default/gpu-operator-test to b120639-pc3
8m36s Normal Pulling pod/gpu-operator-test Pulling image "nvcr.io/nvidia/cloud-native/gpu-operator-validator:v22.9.0"
6m41s Normal Pulled pod/gpu-operator-test Successfully pulled image "nvcr.io/nvidia/cloud-native/gpu-operator-validator:v22.9.0" in 1m55.516263773s
6m41s Normal Created pod/gpu-operator-test Created container cuda-vector-add
6m40s Normal Started pod/gpu-operator-test Started container cuda-vector-add
98s Warning FailedScheduling pod/gpu-operator-test 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.
Vậy để cứu cái ca này, ta sẽ cùng tìm hiểu một chút ở phần dưới đây.
Kubernetes Device Plugin dùng cho GPU
Hiện tại Kubernetes đang hỗ trợ việc quản lý các GPU (không chỉ Nvidia mà còn con cả AMD và Intel) thông qua các Device Plugin tuy vậy chúng sẽ không được cài đặt sẵn mà cần ta tự thực hiện thông qua việc cài đặt GPU driver và cấu hình device plugin tương ứng dựa trên hướng dẫn của bên sản xuất GPU. Khi đã cài đặt plugin thành công, cụm của ta sẽ hiển thị tài nguyên có thể lập lịch tùy chỉnh, chẳng hạn như amd.com/gpu hoặc nvidia.com/gpu. Sẽ có một chút lưu ý khi sử dụng chúng như sau:
- Ta có thể chỉ định GPU
limitsmà không cần chỉ địnhrequestsvìKubernetessẽ sử dụnglimitslàm giá trị yêu cầu theo mặc định. - Ta có thể chỉ định GPU trong cả hai
limitsvàrequestsnhưng hai giá trị này phải bằng nhau. - Ta không thể chỉ định GPU
requestsmà không chỉ địnhlimits.
Khi đó một manifest mẫu được dùng để sử dụng GPU với một pod sẽ như sau:
apiVersion: v1
kind: Pod
metadata:
name: example-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: example-vector-add
image: "registry.example/example-vector-add:v42"
resources:
limits:
gpu-vendor.example/example-gpu: 1 # requesting 1 GPU
Tiếp đó, nếu các node khác nhau trong cụm có các loại GPU khác nhau, thì ta có thể sử dụng node label và node selector để lập lịch pod trên các node thích hợp chẳng hạn như sau:
# Label your nodes with the accelerator type they have.
kubectl label nodes node1 accelerator=example-gpu-x100
kubectl label nodes node2 accelerator=other-gpu-k915
NVIDIA device plugin cho Kubernetes
Để có thể có thể hỗ trợ khách hàng trong việc sử dụng NVIDIA GPU cho cụm Kubernetes, NVIDIA đã cung cấp sẵn NVIDIA device plugin tại https://github.com/NVIDIA/k8s-device-plugin. Về cơ bản thì NVIDIA device plugin được xây dựng cho Kubernetes là một Daemonset cho phép ta tự động:
- Hiển thị số lượng GPU trên mỗi
nodetrong cụm - Theo dõi tình trạng của GPU
- Chạy các
containercó sử dụng GPU trên cụm
Việc cài đặt có thể được thực hiện một cơ số bước được liệt kê trong https://github.com/NVIDIA/k8s-device-plugin#quick-start, tuy vậy ta sẽ không phải tự thực hiện chúng mà các bước này sẽ được thực hiện thông qua NVIDIA GPU Operator
NVIDIA GPU Operator trên cụm Kubernetes

Như trình bày ở phần trước, Kubernetes cung cấp quyền truy cập vào các tài nguyên phần cứng đặc biệt như GPU NVIDIA, NIC, Infiniband adapters và các thiết bị khác thông qua device plugin framework. Tuy nhiên, việc cấu hình và quản lý các node bằng các tài nguyên phần cứng này yêu cầu cấu hình nhiều thành phần phần mềm như drivers, container runtime hoặc các thư viện khác, rất khó và dễ xảy ra lỗi.
Để giải quyết vấn đề này, NVIDIA GPU Operator được xây dựng thông qua operator framework trong Kubernetes để tự động hóa việc quản lý tất cả các thành phần phần mềm NVIDIA cần thiết để cung cấp GPU. Các thành phần này bao gồm:
- NVIDIA drivers (để có thể sử dụng CUDA)
- Kubernetes device plugin cho GPU
- NVIDIA Container Toolkit
- Trình gán nhãn nút tự động bằng NVIDIA GPU feature discovery
- Bộ giám sát dựa trên NVIDIA Data Center GPU Manager (DCGM)
- Và các thành phần khác.
Việc triển khai NVIDIA GPU Operator thông qua Helm Chart, và ta có thể cài đặt nó dễ dàng theo các bước như sau:
Đầu tiên, ta cần cài helm nếu chưa có sẵn thông qua câu lệnh:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
Và tiếp đó là thêm NVIDIA Helm repository như sau:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
Chart của GPU Operator sẽ được sử dụng để tự động cài đặt các thành phần cần thiết nhưng trước khi sử dụng, ta cần xem quá chúng tại https://github.com/NVIDIA/gpu-operator/tree/master/deployments/gpu-operator. Nếu như không có gì cần thay đổi thì ta tạo bản release từ chart đó qua câu lệnh sau:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator
Đối với các máy có sẵn NVIDIA driver thì ta có thể bỏ qua việc cấu hình driver để tránh các vấn đề phát sinh thông việc đặt driver.enabled có giá trị là false như sau:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set driver.enabled=false
Tương tự như vậy nếu môi trường runtime đã được cấu hình sẵn để sử dụng NVIDIA Container Toolkit thì ta có thể tùy chỉnh giá trị của bản chart release như sau:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set driver.enabled=false \
--set toolkit.enabled=false
Cuối cùng, sau một tỉ năm chờ đợi thì ta sẽ có namespace mới có tên gpu-operator được tạo và một tỉ thứ khác trong đó như sau:
NAME READY STATUS RESTARTS AGE
gpu-operator-59b9d49c6f-xrz9q 1/1 Running 0 15m
gpu-operator-1665737174-node-feature-discovery-worker-2ltj5 1/1 Running 0 15m
gpu-operator-1665737174-node-feature-discovery-master-7fd6fw7ww 1/1 Running 0 15m
nvidia-dcgm-exporter-sjjjr 0/1 PodInitializing 0 4m10s
nvidia-cuda-validator-8kbh2 0/1 Completed 0 3m22s
nvidia-device-plugin-daemonset-zmqrs 1/1 Running 0 4m10s
nvidia-device-plugin-validator-lmrfp 0/1 Completed 0 2m39s
nvidia-operator-validator-zk77v 1/1 Running 0 4m11s
gpu-operator-1665737174-node-feature-discovery-worker-sjzdz 1/1 Running 6 (5m8s ago) 15m
gpu-feature-discovery-kvsc7 1/1 Running 0 4m10s
nvidia-container-toolkit-daemonset-cpjxx 1/1 Running 0 4m11s
Để kiểm tra xem gpu-operator có đang hoạt động hay không, ta có thể sử dụng manifest để tạo một Deployment như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nvidia-plugin-test
labels:
app: nvidia-plugin-test
spec:
replicas: 1
selector:
matchLabels:
app: nvidia-plugin-test
template:
metadata:
labels:
app: nvidia-plugin-test
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
resources:
limits:
nvidia.com/gpu: 1
securityContext:
capabilities:
add: ["SYS_ADMIN"]
Kết quả thu được sẽ như sau:
% kubectl get pod nvidia-plugin-test-6d64ffd55f-l46r9
NAME READY STATUS RESTARTS AGE
nvidia-plugin-test-6d64ffd55f-l46r9 1/1 Running 0 17m
Điều này có nghĩa là các pod có yêu cầu sử dụng Nvidia GPU đã được lập lịch và phần cài đặt trước của ta đã may mắn không có lỗi gì cả.
☆*:.。.o(≧▽≦)o.。.:*☆ ☆*:.。.o(≧▽≦)o.。.:*☆ ☆*:.。.o(≧▽≦)o.。.:*☆
MIG Support trên Kubernetes
Vậy như ở trên ta đã có thể config cho các thành phần trên Kubernetes để có thể sử dụng GPU. Tuy vậy thì tài nguyên nvidia.com/gpu theo mặc định chỉ được đếm theo số GPU được đăng ký nên việc để hai pod sử dụng chung một GPU là không thể khi ta không được phép config dưới dạng nvidia.com/gpu: 0.5. Điều đó dẫn đến việc lãng phí tài nguyên trong quá trình sử dụng GPU khi các loại GPU hiện đại thường có VRAM lớn (ví dụ 12GB với con 2080Ti) và không phải mô hình học máy nào cũng dùng hết lượng VRAM lớn như vậy.
Để hình dung rõ hơn thì thì khi tăng replicas thành 2 ở manifest trên, ta sẽ gặp ngay lỗi 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod. khiến cho pod mới không được lập lịch. Để giải quyết vấn đề này, Yến Vi đã giới thiệu giải pháp Multi-Instance GPU bằng cách phân chia GPU thành bảy phiên bản, mỗi phiên bản được cách ly hoàn toàn với bộ nhớ băng thông cao, bộ nhớ đệm và lõi tính toán của riêng nó. Điều này mang lại cho ta khả năng hỗ trợ mọi khối lượng công việc, từ nhỏ nhất đến lớn nhất, với chất lượng dịch vụ được đảm bảo (QoS) và mở rộng phạm vi tiếp cận của các tài nguyên máy tính được tăng tốc cho mọi người dùng.
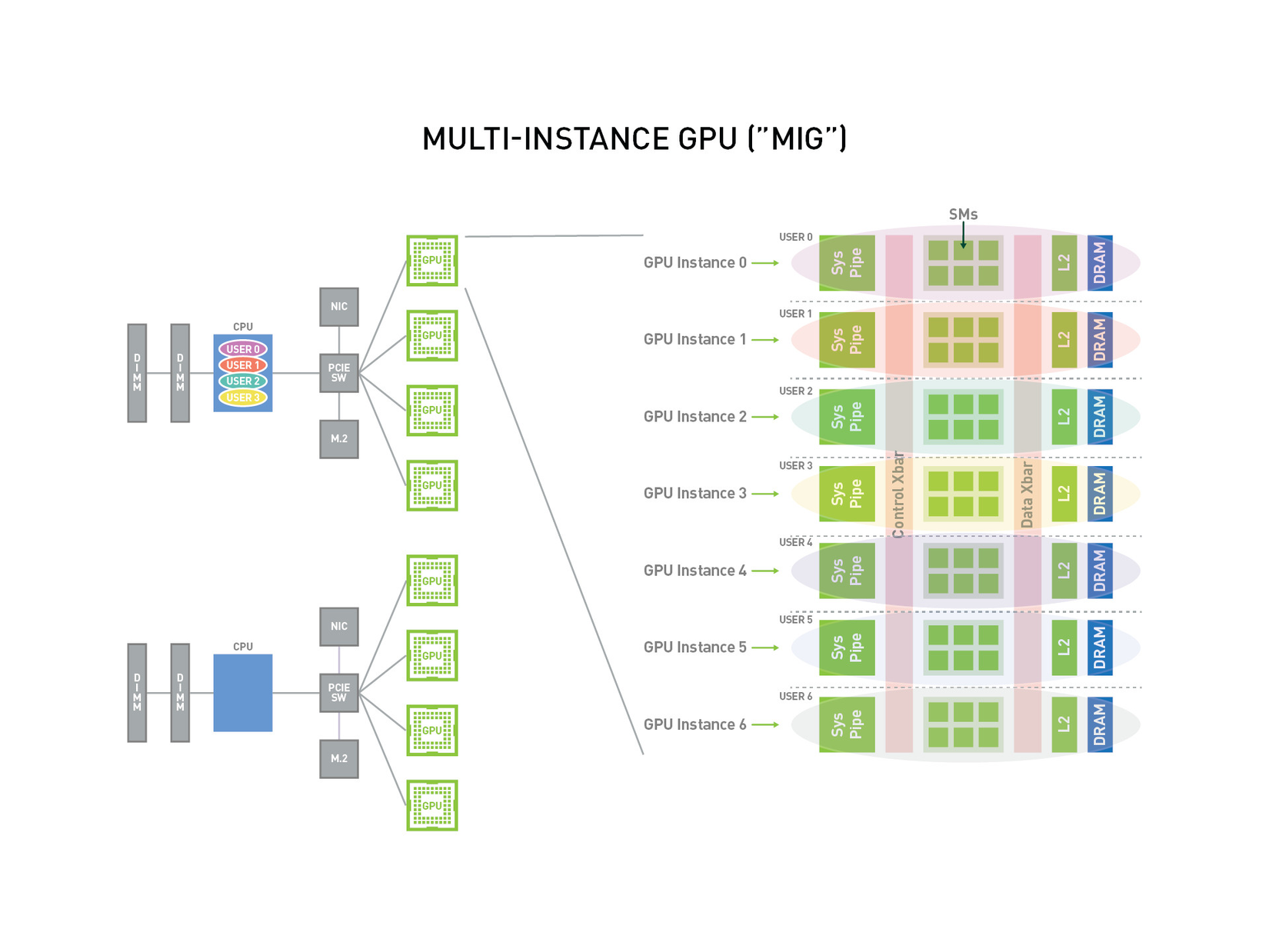
Tuy vậy cuộc sống lại không dễ dàng như thế khi Multi-Instance GPU chỉ hỗ trợ các GPU dựa trên kiến trúc Ampere như NVIDIA A100 hay cụ thể hơn là H100, A100, A30 nên ta cần có giải pháp khác khi ta không có tiền (눈_눈)(눈_눈)(눈_눈)
Time-Slicing GPUs in Kubernetes
Như được giới thiệu ở trên, các thế hệ GPU NVIDIA mới nhất cung cấp một chế độ hoạt động được gọi là Multi-Instance GPU hay MIG. MIG cho phép ta phân vùng GPU thành nhiều phiên bản nhỏ hơn, được xác định trước, mỗi phiên bản trông giống như một GPU mini cung cấp bộ nhớ và cách ly lỗi ở lớp phần cứng. Với việc phân chia như vậy, ta có thể chia sẻ quyền truy cập vào GPU bằng cách chạy khối lượng công việc trên một trong các phiên bản được xác định trước này thay vì GPU gốc đầy đủ.
Tuy vậy nếu như:
- Bạn không thích dùng
MIGvì nó viết tắt giống tên người yêu cũ - Bạn sẵn sàng đánh đổi sự cô lập do MIG cung cấp để có được khả năng chia sẻ GPU bởi một số lượng lớn người dùng hơn
- Bạn không có tiền để mua GPU mới
Để giải quyết vấn đề này, NVIDIA GPU Operator cho phép đăng ký quá mức GPU thông qua một tập hợp các tùy chọn mở rộng cho NVIDIA Kubernetes Device Plugin để cho phép các khối lượng công việc đặt trên các GPU được đăng ký xen kẽ với nhau. Cơ chế cho phép “chia sẻ thời gian” GPU trong Kubernetes này cho phép ta hệ thống xác định một tập hợp các “bản sao” cho GPU, mỗi bản sao có thể được phân phối độc lập cho một nhóm để chạy khối lượng công việc. Không giống như MIG, không có bộ nhớ hoặc cách ly lỗi giữa các bản sao, nhưng đối với một số đôi khi sẽ chẳng ai quan tâm đến việc đó cả và cơ chế Time-Slicing của GPU được sử dụng để ghép các khối lượng công việc từ các bản sao của cùng một GPU cơ bản.
Để cấu hình cho quyền truy cập được chia sẻ vào GPU với GPU Time-Slicing, ta cần cung cấp cấu hình time-slicing cho NVIDIA Kubernetes Device Plugin như ConfigMap sau:
version: v1
sharing:
timeSlicing:
renameByDefault: <bool>
failRequestsGreaterThanOne: <bool>
resources:
- name: <resource-name>
replicas: <num-replicas>
...
Một ConfigMap mẫu được cung cấp bởi sách giáo khoa như sau:
apiVersion: v1
kind: ConfigMap
data:
tesla-t4: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4
Với config như trên, ta có thể cho phép 4 pod cùng sử dụng một con T4. Tương tự như vậy config cho một con a100 sẽ như sau:
a100-40gb: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 8
- name: nvidia.com/mig-1g.5gb
replicas: 2
- name: nvidia.com/mig-2g.10gb
replicas: 2
- name: nvidia.com/mig-3g.20gb
replicas: 3
- name: nvidia.com/mig-7g.40gb
replicas: 7
Tôi thì không giàu như vậy nên config được tôi sử dụng để thí nghiệm với con 2080Ti sẽ như sau:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
namespace: gpu-operator
data:
2080ti-12gb: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 6
Để kích hoạt tính năng time-slicing với NVIDIA GPU Operator bằng cách chuyển devicePlugin.config.name thành tên của tham số ConfigMap được tạo ở trên như sau:
kubectl patch clusterpolicy/cluster-policy \
-n gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config"}}}}'
Cấu hình time-slicing có thể được áp dụng ở cấp độ cụm hoặc trên mỗi node. Theo mặc định, GPU Operator sẽ không áp dụng cấu hình time-slicingcho bất kỳ nút GPU nào trong cụm và ta sẽ phải chỉ định rõ ràng nó với devicePlugin.config.default và ta có thể cập nhật nó bằng câu lệnh như sau:
kubectl patch clusterpolicy/cluster-policy \
-n gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config", "default": "2080ti-12gb"}}}}'
Để kiểm tra xem việc cấu hình có ok không, ta có thể kiểm tra thông tin các node như sau:
% kubectl describe node b120639-pc3 | grep nvidia.com/gpu:
nvidia.com/gpu: 6
nvidia.com/gpu: 6
Kết quả như trên cho thấy việc cấu hình của ta đã diễn ra thành công và hậu tố SHARED đã được thêm vào tên của gpu.product
% kubectl describe node b120639-pc3 | grep nvidia.com/gpu.product
nvidia.com/gpu.product=NVIDIA-GeForce-RTX-2080-Ti-SHARED
Và bây giờ đơn vị cơ bản được sử dụng trong việc quản lý tài nguyên trên node này sẽ là 1/6 của GPU nên ta có thể cấu hình Deployment ở trên dưới dạng như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nvidia-plugin-test-2
labels:
app: nvidia-plugin-test-2
spec:
replicas: 2
selector:
matchLabels:
app: nvidia-plugin-test-2
template:
metadata:
labels:
app: nvidia-plugin-test-2
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
resources:
limits:
nvidia.com/gpu: 2
securityContext:
capabilities:
add: ["SYS_ADMIN"]
Kết quả thu được sẽ là :
% kubectl describe nodes b120639-pc3
Name: b120639-pc3
...
Capacity:
nvidia.com/gpu: 6
Allocated resources:
...
Resource Requests Limits
...
nvidia.com/gpu 4 4
Tổng kết
Bài viết này trình bày về cách các thành phần của Kubernetes tương tác với Nvidia GPU cũng như nói về các giải pháp để sử dụng GPU trên cụm Kubernetes một cách hiệu quả hơn thông qua tính năng Time-Slicing. Việc cấu hình cụm Kubernetes để sử dụng Nvidia GPU là bước nền tảng để triển khai các dịch vụ có sử dụng Nvidia GPU chẳng hạn như Triton Inference Server và trong bài viết tới (nếu tôi có viết), ta sẽ cùng nhau tìm hiểu về giải pháp serving mô hình này. Bài viết đến đây là hết, cảm ơn mọi người đã dành thời gian đọc.
Tài liệu tham khảo
All rights reserved
