Cấu hình Healthcheck trên Kubernetes
Bài đăng này đã không được cập nhật trong 2 năm
Hello các bạn lại là mình đây 👋👋👋
Hôm nay ta tiếp tục chinh chiến series học k8s bằng việc tìm hiểu cách cấu hình healthcheck cho app chạy trên Kubernetes với Liveness, Readiness và Startup Probe nhé
Lấy hành trang và lên thuyền với mình nào 🚢🚢🚢
Mở đầu
Trong quá trình triển khai ứng dụng trên Kubernetes, ta phải luôn luôn đảm bảo làm sao cho app của chúng ta luôn up khi user truy cập và nếu có vấn đề gì xảy ra trong quá trình chạy mà xảy ra lỗi không thể khắc phục thì ta phải thực hiện một hành động nào đó cần thiết, ví dụ như restart lại app
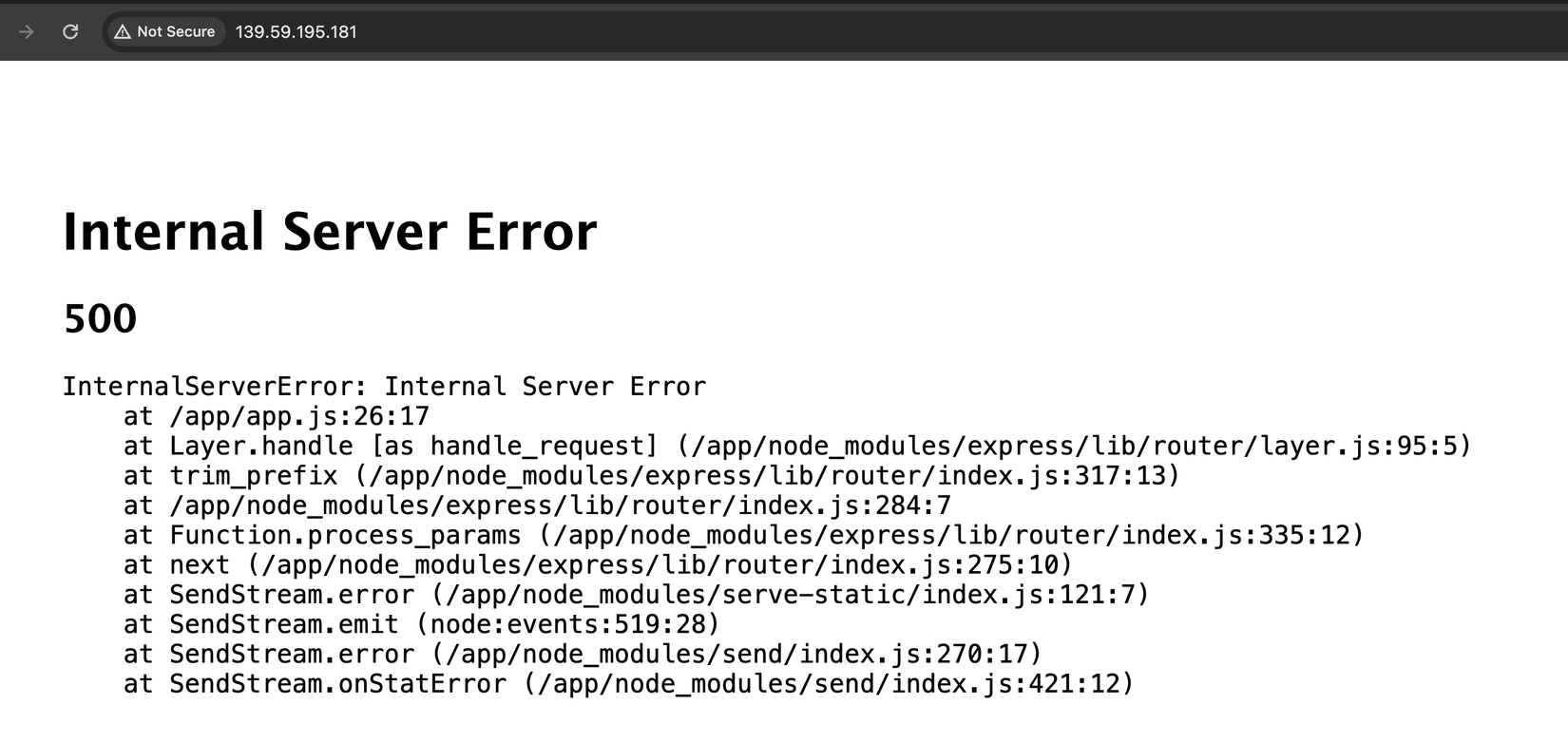
Ví dụ khi app vừa start và mất tới 3 phút để connect tới database và chạy migration script, nếu user truy cập trong khoảng thời gian này thì có thể họ sẽ thấy trang 500 đỏ lòm 🚫.
Hay như app của ta có bug, đang chạy thì bỗng nhiên bị die ☠️, trong trường hợp đó ta cần phải restart ngay lập tức để có thể đưa app up trở lại. Nếu không có thể ăn ngay quả ticket P0 từ sếp 🤣🤣
Với Kubernetes thì những vấn đề bên trên ta có thể cấu hình tự động bằng việc setup healtcheck để có thể tự thực hiện một số hành động cần thiết để đảm bảo rằng app của chúng ta luôn "khoẻ" để phục vụ người dùng
Nếu các bạn đã đi qua series học Docker của mình thì ở đó có bài Docker healthcheck khá là giống với những gì ta sẽ làm trong bài này 😉
Setup
Như thường lệ để làm việc với K8S thì đầu tiên các bạn lấy cho mình 1 session để truy cập vào cluster của mình tại đây nhé: https://learnk8s.jamesisme.com/. Nếu bạn nào chưa xem cách lấy session và dùng như thế nào thì xem lại phần này của mình nhé
Ở bài này ta sẽ demo bằng một ứng dụng nho nhỏ nha. Đầu tiên các bạn tạo cho mình một folder bất kì để tí nữa ta cho hết các file manifest vào đó nhé, ví dụ ta đặt tên folder là k8s-healthcheck đi 😁.
Trong đó các bạn tạo cho mình file deployment.yml với nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-healthcheck
spec:
selector:
matchLabels:
app: demo-healthcheck
template:
metadata:
labels:
app: demo-healthcheck
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-healthcheck
imagePullPolicy: Always
ports:
- containerPort: 3000
name: myport
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
Tiếp đó ta tạo manifest cho service của app bên trên với file svc.yml
apiVersion: v1
kind: Service
metadata:
name: demo-healthcheck
spec:
selector:
app: demo-healthcheck
ports:
- name: mysvc
protocol: TCP
port: 80
targetPort: myport
type: LoadBalancer
Nội dung 2 file bên trên thì qúa là cụ thể rõ ràng rồi, nếu các bạn đi từ những bài trước của mình thì sẽ không cần giải thích gì thêm nha 😂😂 (nhưng nếu có thắc mắc thì cứ comment cho mình biết)
Âu cây roài, folder của ta giờ có những thứ sau:
Giờ ta apply từng cái một nhé:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
kubectl apply -f svc.yml --kubeconfig=./kubernetes-config
>>>>>>>>
deployment.apps/demo-healthcheck created
service/demo-healthcheck created
Sau đó ta get xem pod tạo ra và service xem như thế nào nhé:
kubectl get po --kubeconfig=./kubernetes-config
kubectl get svc --kubeconfig=./kubernetes-config
>>>
NAME READY STATUS RESTARTS AGE
demo-healthcheck-5fcf44c887-h5xp4 1/1 Running 0 2m7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo-healthcheck LoadBalancer 10.245.37.23 139.59.195.181 80:30312/TCP 7m39s
Bởi vì service của ta Type=LoadBalancer nên sẽ mất một vài phút để Cloud provider tạo LB cho chúng ta, đoạn đầu nó sẽ có EXTERNAL-IP=Pending sau đó sẽ có IP cụ thể nhé
Sau khi app đã lên và có External IP cho LB thì ta truy cập từ trình duyệt xem như thế nào nha, ta mở trình duyệt ở địa chỉ http://<IP của LB> (thay IP LB của các bạn vào cho đúng nhé, của mình là http://139.59.195.181)
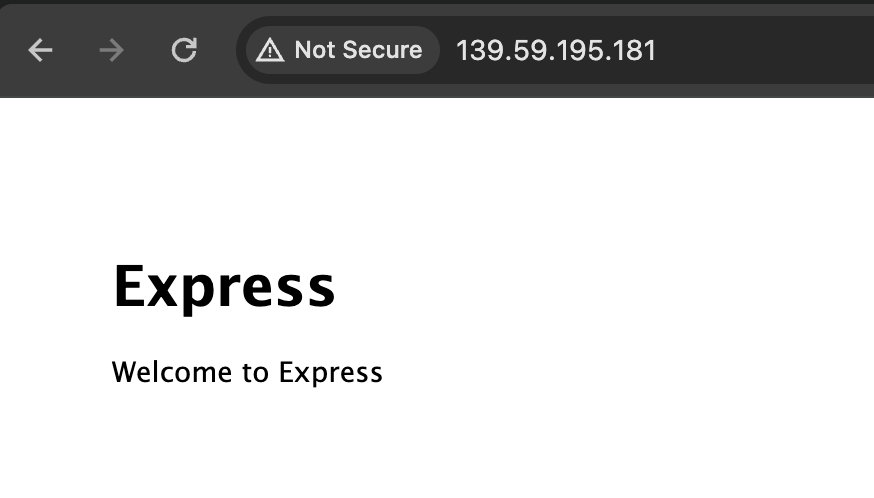
Ở đây ta có một app Nodejs Express show trang webcome khá đơn giản. App của chúng ta có một số endpoints sau:
- Trang chủ:
/ /healthz: check xem app đã lên hay chưa/readiness: check xem app đã ready chưa/liveness: check xem app còn "sống" không 😂/kill: kill app, tất cả request trả về là lỗi500
ta sẽ giải thích dần dần mục đích từng API bên dưới nhé
Đến đây là tạm oke bước đầu setup rồi này 😆
Liveness probe
Giờ ta truy cập vào đường dẫn http://139.59.195.181/kill (thay IP service của các bạn vào cho đúng nhé) và sẽ thấy như sau:
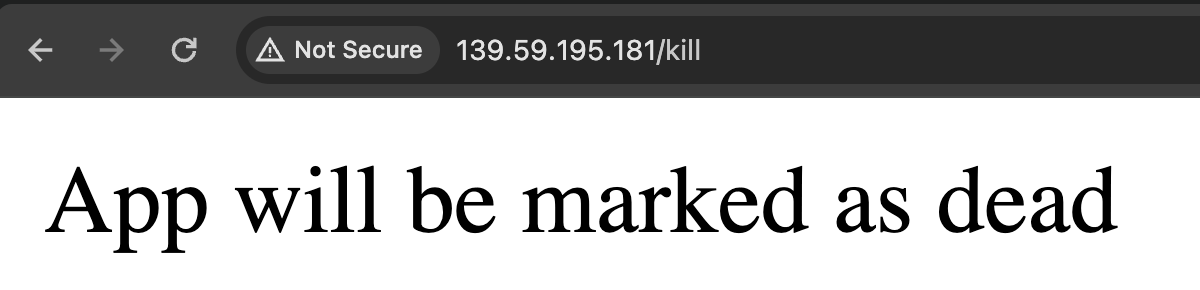
Pòm, app của ta từ đây đã ngỏm 🧨
Thử F5 các kiểu, quay lại trang chủ F5, tất cả đều ngủm củ tỏi luôn 🧄🧄🧄:
Ta restart lại deployment để fix lỗi này nhé:
kubectl rollout restart deploy demo-healthcheck --kubeconfig=./kubernetes-config
>>>
deployment.apps/demo-healthcheck restarted
Lại lên gòiiii 🥳🥳. Nhưng nếu ta lại truy cập vào /kill thì app lại die tiếp và ta cần phải restart
Với trường hợp như thế này thì một trong những cách giải quyết phổ biến đó là ta sẽ dùng tới Liveness probe (probe - thăm dò, liveness - sự sống), ý là ta sẽ liên tục check "sự sống" app của chúng ta trong quá trình nó chạy, và khi nào thấy có lỗi trả về là sẽ restart lại app tự động.
Ta sửa lại file deployment.yml như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-healthcheck
spec:
selector:
matchLabels:
app: demo-healthcheck
template:
metadata:
labels:
app: demo-healthcheck
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-healthcheck
imagePullPolicy: Always
ports:
- containerPort: 3000
name: myport
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
livenessProbe:
httpGet:
path: /liveness
port: 3000
initialDelaySeconds: 5
periodSeconds: 10
Ở trên ta vừa thêm vào livenessProbe đây là 1 cái healtcheck để check xem container của ta còn sống hay không, nếu nó fail thì sẽ tiến hành restart lại container
Ở đây ta khai báo là:
- gọi vào API
/livenessở cổng3000(cổng mà app ta đang chạy) - sau khi container start được 5 giây thì hẵng bắt đầu thực hiện check lần đầu tiên (
initialDelaySeconds) - thực hiện check theo chu kì mỗi 10 giây (
periodSeconds)
oke rồi giờ ta apply lại deployment nhé:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
Sau đó ta theo dõi log của container ở Pod mới được tạo ra:
kubectl logs demo-healthcheck-5fb6584bb6-52njq -f
Thay tên pod của các bạn vào cho đúng nha
Ở trên ta check log với option
-flà check realtime luôn. Cứ để terminal nó chạy và treo ở đó nhé
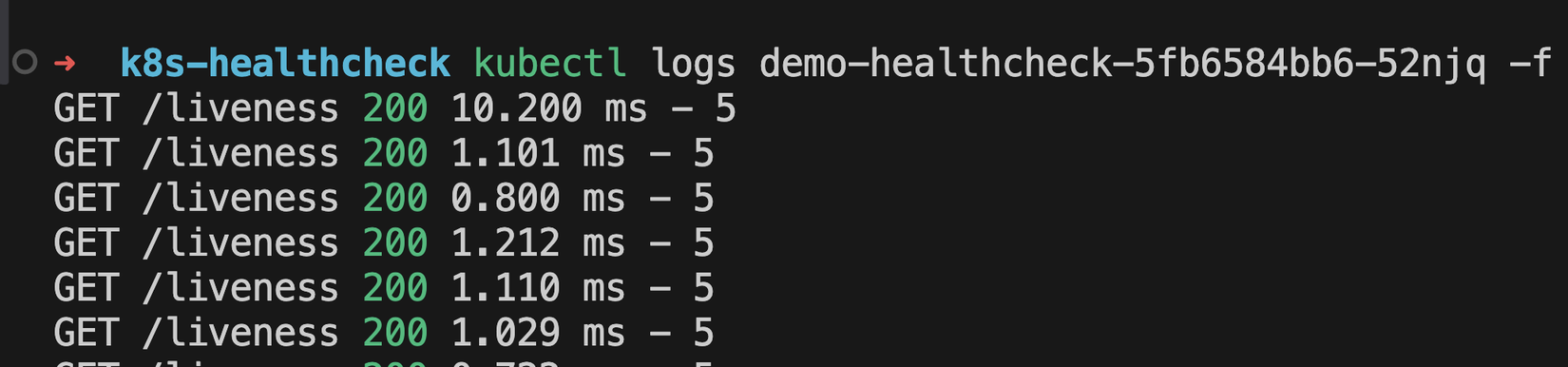
Ta sẽ thấy K8S đã thực hiện gọi vào API /liveness để check liên tục mỗi 10 giây, và hiện tại tất cả đang trả về là 200
Ta có thể trực tiếp truy cập từ trình duyệt vào /liveness từ trình duyệt để xem nó trả về như thế nào:
Alive 😎
Oke giờ ta cho nó cúp điện luôn nhé 🤣🤣. Từ trình duyệt ta lại truy cập vào đường dẫn http://139.59.195.181/kill (thay IP của các bạn vào)
Ngay sau đó ở terminal ta sẽ thấy in ra lỗi đỏ 500:
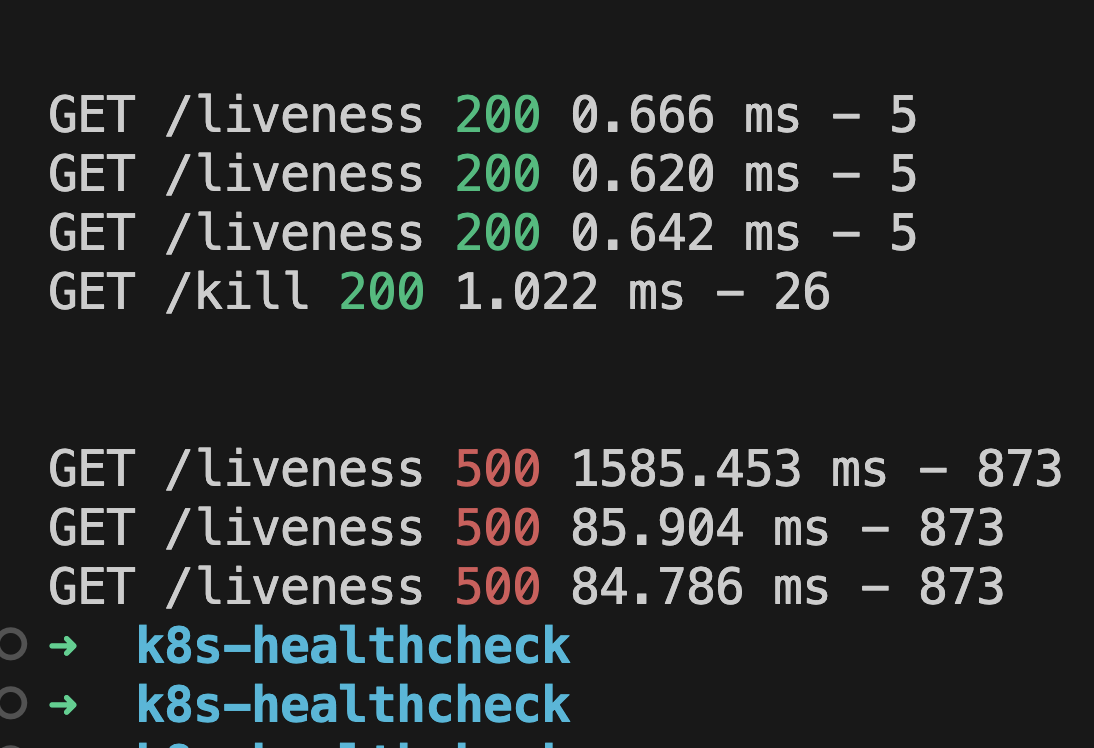
Thử describe pod thì cũng thấy báo tín hiệu là K8S đang chuẩn bị kill container:
kubectl describe pod demo-healthcheck-5fb6584bb6-52njq --kubeconfig=./kubernetes-config
Thay tên Pod của các bạn vào nhé
Ta thấy in ra như sau:
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 13m default-scheduler Successfully assigned lk8s-d707b3/demo-healthcheck-5fb6584bb6-52njq to pool-8cpu-16gbram-jyy0t
Normal Pulling 13m kubelet Pulling image "maitrungduc1410/viblo-k8s-healthcheck"
Normal Pulled 13m kubelet Successfully pulled image "maitrungduc1410/viblo-k8s-healthcheck" in 3.591734377s (3.591748467s including waiting)
Normal Created 13m kubelet Created container myapp
Normal Started 13m kubelet Started container myapp
Warning Unhealthy 27s kubelet Liveness probe failed: Get "http://10.244.0.81:3000/liveness": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Warning Unhealthy 8s (x2 over 18s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
Normal Killing 8s kubelet Container myapp failed liveness probe, will be restarted
Ở trên ta thấy rằng có dòng log Container myapp failed liveness probe, will be restarted - container myapp có liveness probe failed và sẽ được restart
Sau khi container được restart thì ta get po sẽ thấy báo:
kubectl get po --kubeconfig=./kubernetes-config
>>>
NAME READY STATUS RESTARTS AGE
demo-healthcheck-5fb6584bb6-52njq 1/1 Running 1 (8s ago) 13m
Ở trên K8S báo rằng đã có 1 lần restart 8 giây trước
Ô mà ủa, sao phần log app của ta lại có 3 dòng fail 500 ta?
Tưởng là fail 1 lần là restart luôn rồi chứ? 🙄🙄
Về vấn đề này thì thực chất là có một option failureThreshold - số lần mà probe fail trước khi thực hiện restart, mặc định là 3 lần fail mới restart, giờ ta sửa thành 1 lần xem nhé:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-healthcheck
spec:
selector:
matchLabels:
app: demo-healthcheck
template:
metadata:
labels:
app: demo-healthcheck
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-healthcheck
imagePullPolicy: Always
ports:
- containerPort: 3000
name: myport
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
livenessProbe:
httpGet:
path: /liveness
port: 3000
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 1 #<<<<<<----- Ở đây
Sau đó ta apply deployment:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
>>>
deployment.apps/demo-healthcheck configured
Sau đó ta lại tiếp tục quay trở lại trình duyệt và truy cập vào đường dẫn /kill
Tiếp đó ta check log của pod:
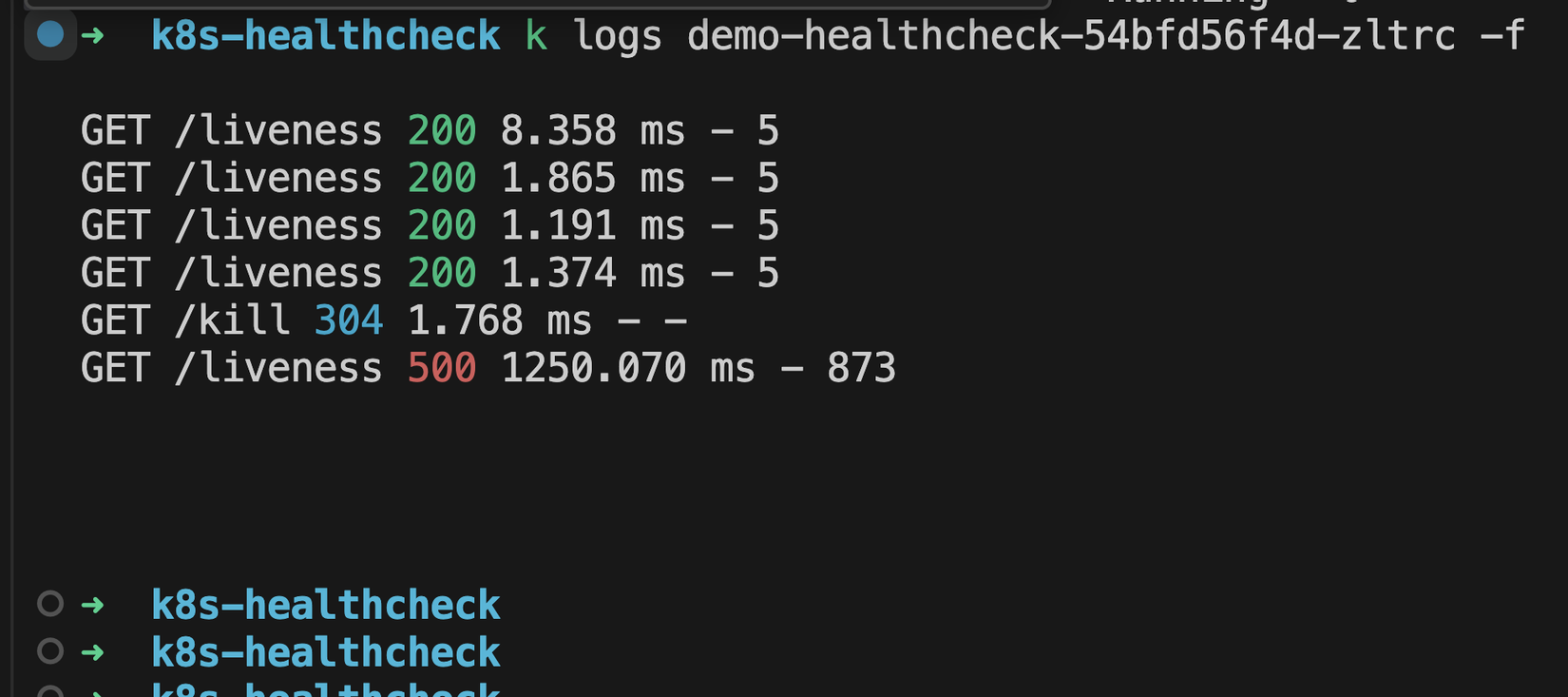
Như các bạn đã thấy giờ chỉ cần sau 1 lần liveness probe fail là container sẽ được restart 💪
Startup probe
Với nhiều app lớn, hoặc app cũ ngày xửa xưa, thì đoạn ban đầu khi start app lên sẽ mất rất nhiều thời gian: load codebase khủng, compile tại thời điểm start, load một loạt class/thư viện để có thể chạy được...
Với những trường hợp như vậy thì container của ta cần thêm thời gian, nếu ta thực hiện liveness probe check ngay thì có thể dẫn tới container bị kill bởi k8s dẫn tới vòng lặp vô hạn. Để xử lý những tình huống cụ thể như thế này thì k8s cho ta thêm một probe nữa là startupProbe
Probe này sẽ chạy vào thời điểm container được khởi tạo (không như liveness chạy liên tục suốt vòng đời của container)
Ta sửa lại deployment.yml như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-healthcheck
spec:
selector:
matchLabels:
app: demo-healthcheck
template:
metadata:
labels:
app: demo-healthcheck
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-healthcheck
imagePullPolicy: Always
ports:
- containerPort: 3000
name: myport
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
livenessProbe:
httpGet:
path: /liveness
port: myport
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 1
startupProbe:
httpGet:
path: /healthz
port: myport
failureThreshold: 30
periodSeconds: 10
Ở trên ta đã đổi
port=myportcho tiện, sau sửa containerPort thì không cần sửa ở nhiều chỗ
Ở trên các bạn thấy cách dùng của startupProbe thì giống y như livenessProbe thôi. Ta cấu hình cho startup probe chạy tối đa trong 30 x 10 = 300 giây. Nếu sau 300 giây mà không khởi động xong thì tiến hành restart, còn nếu thành công thì việc của startupProbe xong và tiến vào giai đoạn livenessProbe
Giờ ta apply lại:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
Sau đó ta thực hiện check log sẽ thấy rằng ngay đầu tiên K8S đã chạy startupProbe và thấy thành công, sau đó chạy livenessProbe như bình thường:

Phần này thì cũng không có gì lắm, chỉ cần ta biết áp dụng cho đúng hoàn cảnh là được
Nếu bạn nào có thắc mắc vì sao api mình lấy tên là
healthz, thì nó chỉ là cái convention mọi người hay dùng thôi 😂😂, xem thêm ở đây nhé
Hmmmmmmmmmmmm, xem qua cái startupProbe, nom chả khác quái gì livenessProbe, vậy giờ thay vì dùng startupProbe thì ta dùng livenessProbe với initialDelaySeconds dài hơn là được chứ gì??? 🤔🤔
Cũng......... đúng, về mặt kĩ thuật 😂, tí nữa cuối bài ta sẽ tổng hợp lại những điều khác nhau của chúng và khi nào dùng cái nào nhé
Readiness probe
Trong quá trình triển khai ứng dụng ta khá là hay gặp phải trường hợp, khi app khởi động lên rồi, nhưng đang chờ kết nối tới database, hoặc cần phải chạy migration/seeding để đảm bảo các table cần thiết phải có sẵn, hay gọi tới một service nào đó để lấy một số thông tin trước khi app của ta có thể hoàn toàn chạy và phục vụ người dùng.
Bản chất thì app của ta đã lên rồi nhưng nó "chưa sẵn sàng" để cho user sử dụng, và trong những trường hợp như vậy thì K8S cho ta thêm một loại probe nữa đó là readinessProbe.
Ta sửa lại file deployment.yml như sau nha:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-healthcheck
spec:
selector:
matchLabels:
app: demo-healthcheck
template:
metadata:
labels:
app: demo-healthcheck
spec:
containers:
- name: myapp
image: maitrungduc1410/viblo-k8s-healthcheck
imagePullPolicy: Always
ports:
- containerPort: 3000
name: myport
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
livenessProbe:
httpGet:
path: /liveness
port: myport
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 1
startupProbe:
httpGet:
path: /healthz
port: myport
failureThreshold: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /readiness
port: myport
initialDelaySeconds: 5
periodSeconds: 10
failureThreshold: 1
successThreshold: 3
Ở trên ta khai báo thêm readinessProbe, các option thì vẫn giống như là 2 probe ở trên, có 2 option mình cần lưu ý cho các bạn:
- Giống như
livenessProbe,readinessProbechạy liên tục trong suốt vòng đời của container failureThreshold: probe fail đủ số lần này thì K8S sẽ đánh dấu Pod là "Not ready" và xoá khỏi Service endpoint, không nhận traffic vào nữasuccessThreshold: probe thành công liên tục đủ số lần này thì mới đánh dấu Pod là Ready và nhận traffic. Trường này vớilivenessProbehaystartupProbethì phải là1do vậy nãy giờ ta không nói tới nó
Ủa Service endpoint là cái gì ta??? chờ tẹo mình giải thích sau nha 😉
Giờ ta apply lại deployment nhé:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
Ngay sau khi apply ta get pod sẽ thấy pod Running nhưng trạng thái ready vẫn là 0/1 mất một lúc:
kubectl get po --kubeconfig=./kubernetes-config
>>>
NAME READY STATUS RESTARTS AGE
demo-healthcheck-59bffb8c54-fk5hv 0/1 Running 0 25s
describe pod xem có gì nha (thay tên pod của các bạn vào cho đúng):
kubectl describe demo-healthcheck-59bffb8c54-fk5hv --kubeconfig=./kubernetes-config
>>>
Warning Unhealthy 3s kubelet Readiness probe failed: HTTP probe failed with statuscode: 503
Ố ồ, báo /readiness fail 🤔🤔
Thử check log (thay tên pod của các bạn vào cho đúng):
kubectl logs demo-healthcheck-59bffb8c54-fk5hv --kubeconfig=./kubernetes-config
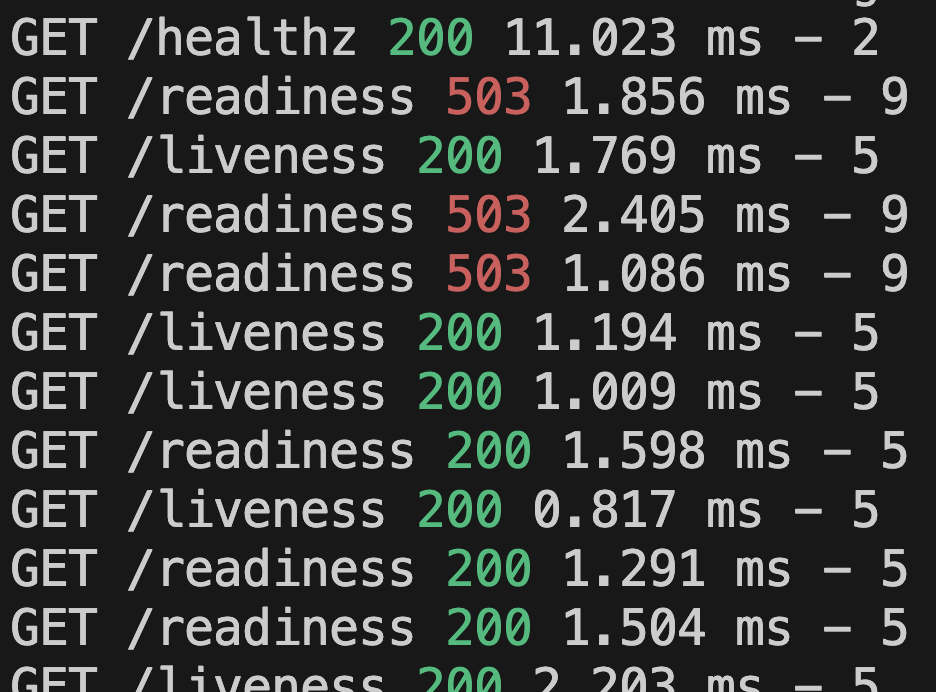
Ở trên ta thấy rằng ban đầu khi mới chạy app thì /readiness bị fail liên tục, sau đó mới success đủ 3 lần liên tiếp (mỗi lần cách nhau periodSeconds = 10 giây), giờ nếu ta quay lại get po thì sẽ thấy trạng thái Ready:
NAME READY STATUS RESTARTS AGE
demo-healthcheck-59bffb8c54-fk5hv 1/1 Running 0 1m19s
Vậy là giờ pod của ta đã sẵn sàng nhận traffic rồi đó 🚀🚀
Ở trong source code mình có để 1 cái timeout, sau 30 giây thì app mới ready, đó là lí do vì sao ta thấy 3 dòng log đỏ của readiness 😂
Giờ quay lại câu hỏi Service endpoint là gì?
Thì Service endpoint về cơ bản là một cặp địa chỉ IP và Port đại diện cho một Pod. Các endpoints này được Kubernetes quản lý linh hoạt để đảm bảo lưu lượng truy cập chỉ được chuyển đến các Pod "healthy" và "ready".
Ta thử get endpoints xem nó là gì nhé:
kubectl get endpoints --kubeconfig=./kubernetes-config
>>>
NAME ENDPOINTS AGE
demo-healthcheck 10.244.0.54:3000 2m51s
Như các bạn thấy ở trên thì pod của ta có 1 endpoint dạng IP:port, nếu Pod Ready thì endpoint kia sẽ được thêm vào list endpoints của Service, và Service sẽ đẩy traffic vào đó.
Nếu 1 deployment ta có nhiều replicas thì cứ một pod ta có 1 endpoint, nom như sau:
demo-healthcheck 10.244.0.167:3000,10.244.0.179:3000,10.244.0.200:3000 + 7 more... 2m55s
Giờ ta xoá deployment đi và vọc lại từ đầu nhé:
kubectl delete -f deployment.yml --kubeconfig=./kubernetes-config
Ngay sau bước này, nếu ta quay lại trình duyệt F5 thì sẽ thấy quay đều quay đều và không trả về gì cả
Tiếp theo ta get endpoints:
kubectl get endpoints --kubeconfig=./kubernetes-config
>>>
NAME ENDPOINTS AGE
demo-healthcheck <none> 13m
Ở đây ta có tàn dư endpoint tên là demo-healthcheck vừa nãy được tạo từ deployment, nhưng không còn IP/port gì nữa cả.
Giờ ta lại apply lại deployment:
kubectl apply -f deployment.yml --kubeconfig=./kubernetes-config
Sau đó ta watch get endpoint:
kubectl get endpoints --kubeconfig=./kubernetes-config -w
>>>
NAME ENDPOINTS AGE
demo-healthcheck <none> 15m
demo-healthcheck 15m
demo-healthcheck 10.244.0.21:3000 16m
Ở trên ta thấy rằng đầu tiên ENDPOINTS là none ngay sau đó nó về empty, vì trong thời gian này Pod chưa Ready, ngay sau khi khi readinessProbe success đủ 3 lần thì endpoint đã lên
Ta vẫn giữ terminal watch kia ở đó nhé, giờ ta quay lại trình duyệt, truy cập vào địa chỉ http://146.190.195.145/kill để kill app đi (thay IP service của các bạn vào), ngay sau đó ở lần readinessProbe check tiếp theo thì sẽ fail, và nếu ta F5 trình duyệt sẽ không còn truy cập được nữa:
Lúc này nếu ta get pod sẽ thấy báo Ready=0/1
Terminal endpoints sẽ báo như sau:
NAME ENDPOINTS AGE
demo-healthcheck <none> 15m
demo-healthcheck 15m
demo-healthcheck 10.244.0.21:3000 16m
demo-healthcheck 19m
Và bởi vì ta cũng đang set failureThreshold của livenessProbe là 1, tức là fail 1 lần là nó sẽ lên lịch restart lại pod liền, do vậy một lúc sau thì terminal của get endpoints sẽ hiện thêm:
NAME ENDPOINTS AGE
demo-healthcheck <none> 15m
demo-healthcheck 15m
demo-healthcheck 10.244.0.21:3000 16m
demo-healthcheck 19m
demo-healthcheck 10.244.0.21:3000 21m
Endpoint lại lên sóng và ta lại có thể truy cập được từ trình duyệt như bình thường
So sánh
Ta cùng tổng hợp lại kiến thức học được trong bài hôm nay vào 1 bảng để tiện so sánh kĩ hơn sự khác nhau giữa các Probe trên K8S nhé:
| Khía cạnh so sánh | Liveness Probe | Startup Probe | Readiness Probe |
|---|---|---|---|
| Mục đích | Đảm bảo container luôn chạy | Đảm bảo container đã khởi động thành công | Đảm bảo container sẵn sàng tiếp nhận lưu lượng truy cập |
| Khi check failed | Khởi động lại container | Không trực tiếp thực hiện bất kỳ hành động nào; livenessProbe bắt đầu sau khi startupProbe thành công |
Xóa Pod khỏi Service Endpoint |
| Trường hợp sử dụng | Phát hiện và phục hồi từ các lỗi ứng dụng | Thích hợp cho các ứng dụng có thời gian khởi tạo lâu | Được sử dụng cho Load Balancer để chỉ định tuyến lưu lượng truy cập đến các Pod đã Ready |
| Giai đoạn thực hiện | Suốt vòng đời của container | Chỉ chạy khi khởi động | Suốt vòng đời của container |
| Ảnh hưởng tới traffic | Không có tác động trực tiếp đến traffic routing | Không có tác động trực tiếp đến traffic routing | Tác động trực tiếp đến việc định tuyến lưu lượng |
| Ví dụ sử dụng | Khởi động lại một ứng dụng không phản hồi (treo) | Chờ cho ứng dụng load xong toàn bộ dependencies (lib, classes,...) và start trước khi thực hiện liveness/readiness probe |
Chờ cho kết nối tới database thành công thì bắt đầu phục vụ người dùng |
Qua đây chúng ta cần cân nhắc sử dụng loại Probe hợp lý nhất cho từng trường hợp nhé
Kết bài
Hi vọng là qua bài này ta đã biết cách để tự cấu hình healthcheck trên K8S như thế nào rồi nhé, từ đó áp dụng vào thực tế một cách hợp lý nhất.
Chúc các bạn buổi tối vui vẻ và hẹn gặp lại các bạn vào những bài sau 👋👋
All rights reserved
