Tìm hiểu về Capsule Network
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Geoffrey Hinton là một nhà nghiên cứu khá nổi tiếng với các công trình liên quan đến mạng neuron nhân tạo. Trong một bài AMA trên reddit, khi được hỏi về ý kiến gây tranh cãi nhất của ông về học máy, ông trả lời rằng:
Dịch sơ sơ ra là:
Phép pooling được sử dụng trong mạng neuron tích chập (CNN - Convolutional Neural Network) là một sai lầm lớn và việc nó hoạt động hiệu quả là một thảm họa.
Năm 2017, ông công bố nghiên cứu của mình về Capsule Network (CapsNet) và kết quả cho thấy rằng CapsNet đạt được kết quả state-of-the-art trên bộ MNIST và có khả năng nhận diện các số bị đè lên nhau tốt hơn mạng CNN bình thường. Vậy câu hỏi là: phép pooling có vấn đề gì và capsule đã khắc phục nó ra sao?
1. Vấn đề của hàm pooling
Trong mạng CNN, hàm pooling (nhất là hàm max pooling) thường được dùng chủ yếu để downsample (giảm kích thước) của feature map, tạo ra một feature map mới tổng quát các đặc trưng của input. Điều này khiến cho nó có thể tăng field-of-view (vùng nhìn thấy) của các neuron ở layer bậc cao hơn, giúp chúng học được các đặc trưng cấp cao hơn. Ngoài ra, việc dùng hàm pooling còn giúp mạng CNN có thể nhận diện một object ở các vị trí khác nhau bằng cách sử dụng weight tốt có được tại một vị trí với các vị trí khác trong input. Tuy nhiên, cách hàm pooling hoạt động cũng tạo nên một điểm yếu của nó: hàm pooling không giữ thông tin về vị trí tương đối giữa các vật thể với nhau.
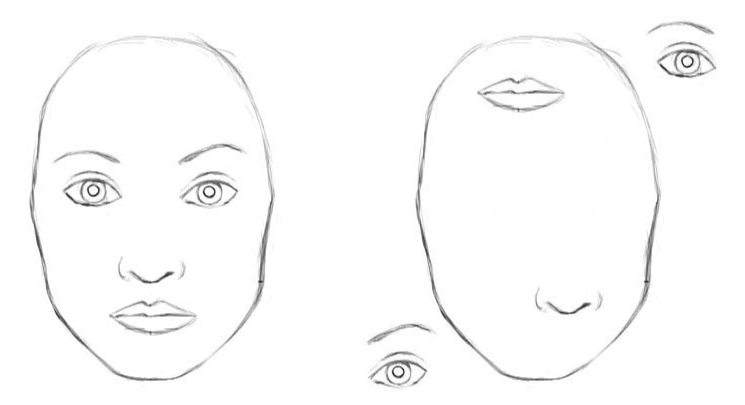
Hình trên sẽ giúp mọi người dễ hình dung hơn. Bên trái của hình là một khuôn mặt với mắt, mũi và môi ở đúng vị trí, còn bên phải là khuôn mặt với các bộ phận không ở đúng vị trí của nó. Với con người, chúng ta có thể dễ dàng nhận diện hình bên trái là một khuôn mặt người hợp lệ, còn bên phải thì không. Tuy nhiên, mạng CNN sẽ nhận diện cả 2 đều là một khuôn mặt hợp lệ bởi tất cả đều có đầy đủ mắt, mũi và môi, bất kể vị trí của chúng. Hướng của các bộ phận và vị trí tương đối trong không gian giữa các bộ phận với nhau đều bị bỏ qua. Như vậy, miễn là có đầy đủ các bộ phận, mạng CNN sẽ nhận diễn ra là khuôn mặt, cho dù các bộ phận được sắp xếp cho bất hợp lý như thế nào đi chăng nữa. Lý do là vì hàm max pooling chỉ lấy các neuron mà active nhất (hay có giá trị lớn nhất) và đưa cho layer tiếp theo. Việc này tuy làm giảm kích thước của feature map nhưng lại làm mất đi thông tin quý giá về không gian giữa các feature khi dữ liệu đi qua các layer. Gọi là quý giá là vì các thông tin này có thể giúp mạng CNN xác định được liệu các feature vừa detect được có làm nên được một feature hợp lệ không. Ví dụ, với các sắp xếp hình bên trái mới là hợp lệ bởi mắt luôn ở trên mũi và mũi ở trên mồm, không như hình bên phải.
2. Capsule
Như vậy, để giải quyết vấn đề trên của mạng CNN, Geoffrey Hinton đã đề xuất sử dụng Capsule thay vì dùng max pooling. Capsule được định nghĩa là một nhóm các neuron mà vector của nó được dùng để biểu diễn các tham số của một entity (thực thể) nhất định như một object hay một phần của object đó. Nó hoạt động theo cơ chế Inverse graphics. Để hiểu rõ hơn, hãy tưởng tượng rằng bạn muốn render một vật thể nào đó nào đó trong game. Để render được object này, bạn cần phải biết các thông số của object đó như chiều dài/rộng/cao, màu sắc, dáng, vị trí,... Khi biết được các thông số đó, bạn mới có thể render được object. Ngoài ra, khi muốn render một object (gọi là Master) được tạo thành bởi nhiều object con thì việc đó cũng được thực hiện tương tự, đi từ thông số của các object con rồi mới đến object Master. Cơ chế Inverse graphics sẽ đi ngược lại, tức là từ một object, nó sẽ đoán các thông số được dùng để khởi tạo object đó (và cũng tương tự từ object Master đến object con rồi đến các thông số của object con). Để dễ hình dung hơn nữa, hãy nhớ lại cấu trúc dữ liệu dạng cây. Quá trình render thông thường sẽ đi theo kiểu bottom-up, còn inverse rendering sẽ đi theo kiểu top-down. Capsule sẽ chứa các thông số khởi tạo này trong activity vector của nó. Theo như Geoffrey Hinton:
- Độ dài của activity vector được dùng để biểu diễn xác suất một object tồn tại.
- Hướng của activity vector sẽ biểu diễn tham số khởi tạo hay pose của object.
Do độ dài của vector biểu diễn xác suất một object tồn tại, nó sẽ luôn phải ở trong đoạn từ 0 đến 1. Điều này được thực hiện bằng cách sử dụng một hàm gọi là hàm squash. Hàm này sẽ đảm bảo rằng các vector nào có độ dài ngắn thì sẽ bị rút về gần 0, còn các vector dài hơn thì sẽ cho gần về 1. Hàm này được tính như sau:
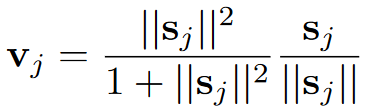
với là vector output của capsule và là tổng input của nó. Input này được tính bằng tổng các tích của các vector dự đoán của capsule layer trước với hệ số coupling coefficient . được tính bằng cách nhân output của một capsule layer trước với một ma trận trọng số .
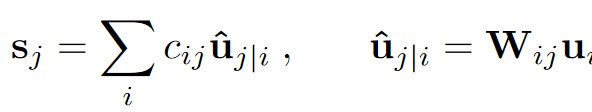
Tổng các coupling coefficient giữa một capsule và các capsule ở layer sau luôn bằng 1 nên nó sẽ được xác định bởi xác suất capsule nên được cặp với capsule gọi là . (Ban đầu, các coefficient này sẽ được cho bằng nhau và sẽ được điều chỉnh dần thông qua quá trình học)
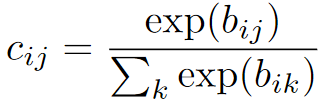
Như vậy, để xác định các feature có hợp lệ hay không, từng capsule (child) mà đang active sẽ tính toán output với tất cả các capsule ở layer cao hơn (parent). Nếu như output với parent nào mà lớn nhất thì parent đó sẽ được "kích hoạt" với child đó. Ví dụ như ta có capsule biểu diễn ngón tay cái ở layer thứ n, layer thứ n+1 có capsule biểu diễn bàn tay và bàn chân. Sau khi nhân các trọng số lại, output của ngón tay cái với bàn tay được 0.9, của ngón tay cái với bàn chân được 0.7 thì capsule bàn tay sẽ được kích hoạt. Cơ chế này được gọi là Iterative routing-by-agreement

Nếu một object thuộc class thứ xuất hiện trong ảnh, ta sẽ muốn kéo dài length của vector khởi tạo capsule thuộc lớp ở layer trên cùng. Việc này được thực hiện bằng cách sử dụng hàm margin loss:
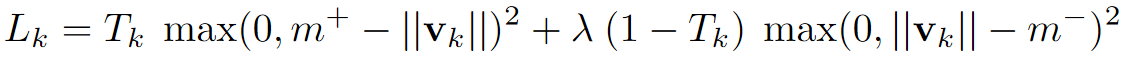
với nếu như class xuất hiện trong input và nếu như không xuất hiện, và . Ngoài ra, trong hàm loss này còn có một hệ số được dùng để tránh trường hợp độ dài của các vector bị giảm đi đáng kể trong giai đoạn đầu của quá trình training.
3. Mạng CapsNet
Để sử dụng Capsule cho việc nhận diện số trong bộ dataset MNIST, Geoffrey Hinton đã đề xuất mạng CapsNet. Nó gồm 2 phần: encoder và decoder.
3.1. Encoder
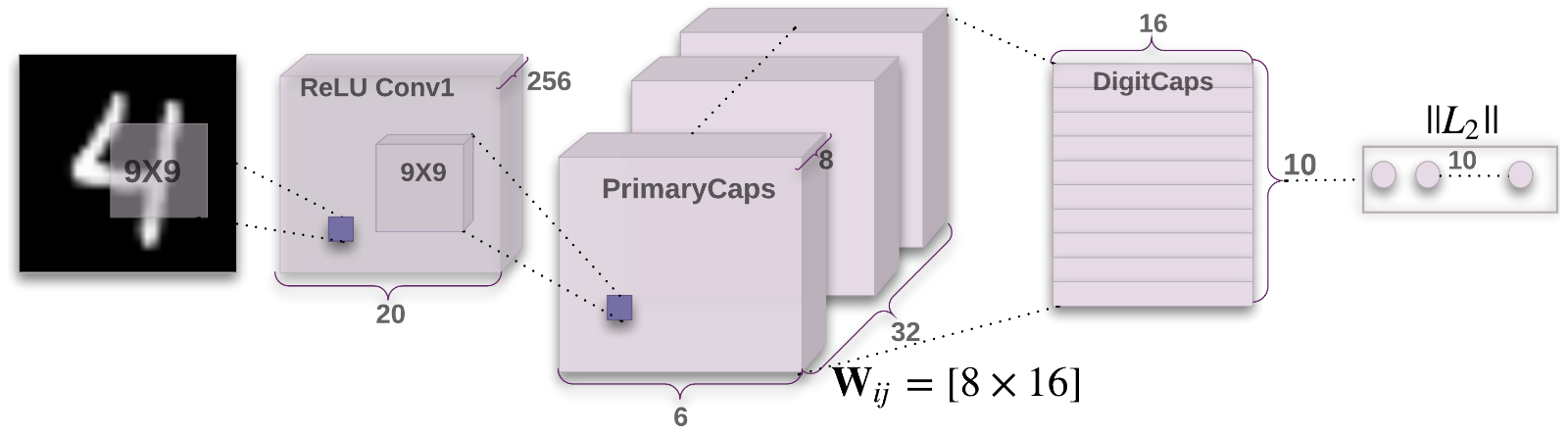
Phần encoder chỉ gồm có 3 layer chính:
- ReLU Conv1: gồm 256 kernel 9x9 với stride 1 và một layer activation ReLU để detect các feature cơ bản trong ảnh đầu vào (có kích thước 28x28). Output có kích thước 20x20x256.
- PrimaryCaps: gồm 32 capsule. Mỗi capsule sẽ tính toán 8 kernel 9x9x256 (stride 2) với output của layer trước và tạo ra output có kích thước là 6x6x8. Output của PrimaryCaps có size là 32x6x6x8.
- DigitCaps: gồm 10 capsule 16 chiều (do có 10 class) và chúng sẽ nhận input từ các capsule của PrimaryCaps. Output là ma trận 10x16.
3.2. Decoder
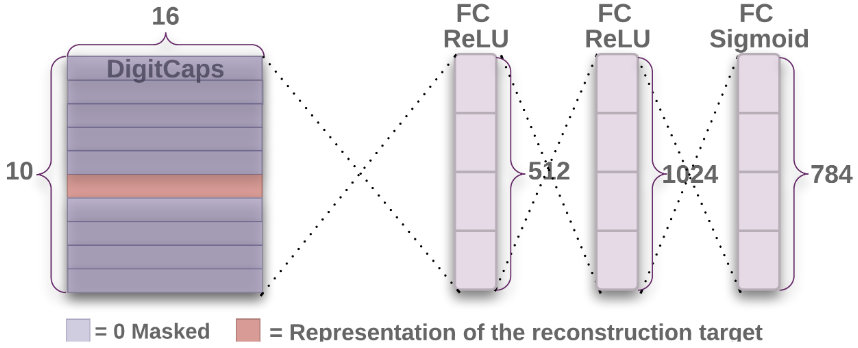
Phần decoder được thêm vào để có thể tái tạo lại được hình ảnh của số từ thông tin được lấy từ DigitCaps. Do đó, việc training decoder cũng sẽ bắt các capsule phải lấy được thông tin khởi tạo từ ảnh đầu vào. Nó gồm 3 layer fully connected, trong đó 2 layer đầu dùng hàm ReLU, layer cuối dùng hàm sigmoid. Trong lúc training, các activity vector của capsule thuộc về các số không ở trong ảnh đầu vào sẽ được zero-mask, để decoder chỉ tái tạo lại hình ảnh của số trong input. Việc training này giúp cho capsule network có thể tái tạo lại được hình ảnh mới gần giống với hình ảnh gốc như hình dưới. Chỉ có 2 case khó ở bên phải là CapsNet đoán sai.

Nếu muốn tìm hiểu cách cài đặt CapsNet để dùng trên bộ dataset MNIST, bạn có thể tham khảo link Colab. Sau 7 epoch training, CapsNet đã đạt được độ chính xác 99% và peak tại 99.5% (do mình chưa train hết 500 epoch  ).
).
Hi vọng bài viết trên đã giúp cho các bạn hiểu cách Capsule hoạt động để khắc phục điểm yếu của hàm pooling trong mạng CNN và cách áp dụng nó trong mạng CapsNet.
All rights reserved
