
[Paper Explained] Dùng mạng GAN để upscale ảnh trông chân thực hơn
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu
Mặc dù việc upscale ảnh bằng mạng CNN đã đạt được nhiều tiến bộ đáng kể về độ chính xác và thời gian chạy, ta vẫn còn một vấn đề lớn vẫn chưa được giải quyết: làm sao để khôi phục được các chi tiết trên bề mặt các object, nhất là khi hệ số upscale lớn (3x, 4x,...)? Bài báo "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network" sẽ giải quyết vấn đề này theo hướng sử dụng một mạng GAN để upscale ảnh.
Vấn đề
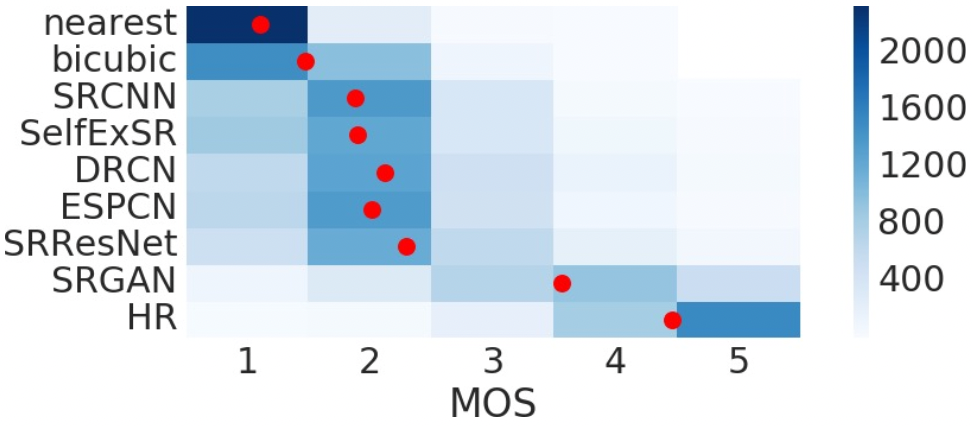
Khi upscale ảnh bằng mạng CNN, người ta thường sử dụng hàm loss MSE (Mean-Squared Error) để train model (ví dụ: SRCNN và FSRCNN). Việc minimize kết quả hàm MSE kéo theo việc tăng Peak signal-to-noise ratio (PSNR), một metric thường được dùng để đánh giá các thuật toán Super Resolution. Tuy nhiên, hàm MSE lại có hạn chế trong việc bắt những chi tiết mà mắt người có thể phân biệt được, ví dụ như các texture chi tiết của object, bởi nó chỉ được định nghĩa theo từng pixel của ảnh. Việc minimize hàm MSE sẽ làm cho model sinh ra các solution là trung bình trong không gian solution, làm cho các pixel này trông khá là mượt nhưng lại kém chất lượng theo trực quan của người nhìn. Do đó, việc tăng metric PSNR không đồng nghĩa với việc kết quả upscale trông sẽ tốt hơn. Ví dụ, trong hình dưới đây, output của SRResNet (được tối ưu cho hàm MSE) có chỉ số PSNR và SSIM (Structural Similarity Index Measure) cao hơn hẳn so với SRGAN nhưng trông vẫn mờ hơn.

Dùng mạng GAN để giải quyết vấn đề
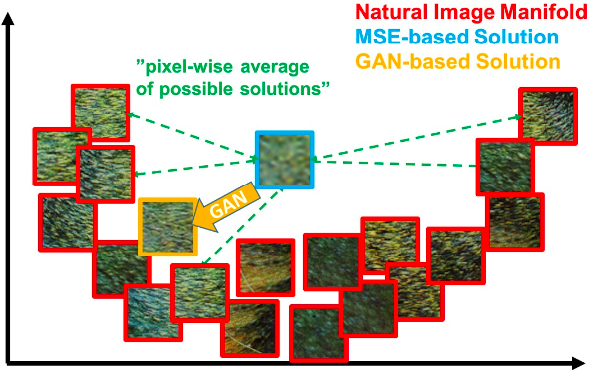
Theo tác giả bài báo, mạng GAN có thể giúp tái tạo lại ảnh có chất lượng cao hơn bởi quá trình training sẽ giúp chúng tìm kiếm solution ở các vùng có xác suất ảnh trông thật cao hơn và từ đó sinh ra ảnh gần giống ảnh tự nhiên hơn. Như hình dưới đây, thay vì estimate một solution average ở giữa trong solution space như MSE (màu xanh lam), mạng GAN (màu vàng) sẽ tìm hẳn một solution gần với phân bố của ảnh tự nhiên (màu đỏ), từ đó sinh ra kết quả trông rõ nét hơn nhiều so với MSE.
Trong bài báo này, tác giả để xuất mạng SRGAN cùng với một vài hàm loss thay thế. Cũng giống như các mạng GAN khác, SRGAN sẽ gồm 2 thành phần là Generator và Discriminator. Generator sẽ cố gắng học cách sinh ra ảnh super-resolution trông thật nhất có thể để đánh lừa Discriminator. Còn Discriminator sẽ học cách phân biệt ảnh thật so với ảnh mà Generator sinh ra. Việc huấn luyện cả 2 để nhằm mục đích giải bài toán min-max sau, giúp cho Generator sinh được ảnh nằm trong không gian của ảnh tự nhiên mà Discriminator không thể phân biệt được.
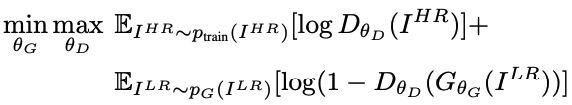
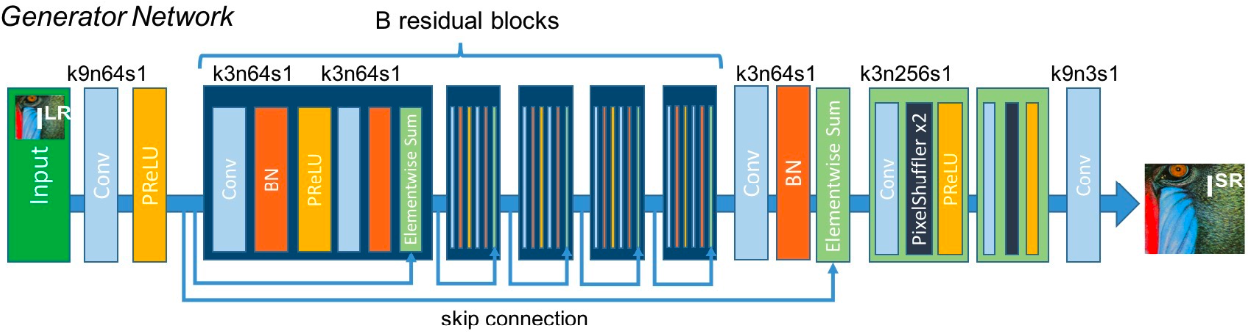
Generator
Generator của SRGAN sẽ nhận ảnh đầu vào là (low resolution) được sinh ra từ một ảnh (high resolution). có kích thước là . Nhiệm vụ của generator là sinh ra một ảnh (super resolution) từ ảnh input . và sẽ có kích thước là , trong đó là hệ số upsample.
Kiến trúc mạng Generator sẽ có residual block gồm 2 kernel với channels theo sau bởi hàm batch normalization và hàm activation ParametricReLU (PReLU). Để upsample kích thước ảnh, tác giả sử dụng 2 layer PixelShuffle, mỗi layer sẽ upsample kích thước ảnh lên gấp đôi. Do đó, output của Generator sẽ gấp 4 lần so với kích thước ảnh input (hay ). Mạng này cũng được gọi là SRResNet. Hình dưới đây là kiến trúc của Generator.
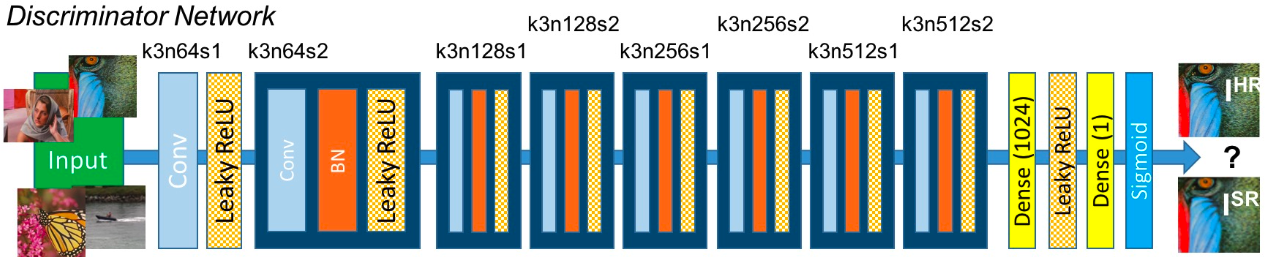
Discriminator
Discriminator của SRGAN sẽ chịu trách nhiệm phân biệt ảnh super-resolution do Generator sinh ra với ảnh thật.
Kiến trúc mạng Discriminator gồm 8 layer convolution với số lượng channel tăng dần theo bội số của 2 từ 64 đến 512 giống như trong mạng VGG. Strided convolution được dùng để giảm kích thước ảnh sau mỗi lần tăng gấp đôi số lượng feature. 512 feature map sẽ được đưa vào 2 layer Dense rồi đến một layer sigmoid cuối cùng để lấy ra xác suất phân biệt ảnh. Hình dưới đây là kiến trúc của Discriminator.
Hàm loss
Thay vì sử dụng luôn MSE làm hàm loss, tác giả thiết kế hàm perceptual loss được mô hình theo MSE. Hàm perceptual loss sẽ gồm 2 hàm loss con là content loss và adversarial loss .
Content loss
Hàm MSE loss theo từng pixel được định nghĩa như sau:
Do hàm MSE bị hạn chế trong việc khôi phục các chi tiết high-frequency (các chi tiết có các pixel thay đổi khá thường xuyên trong không gian ảnh, ví dụ như cạnh của các object trong ảnh), tác giả định nghĩa hàm loss VGG. Thay vì tính theo từng pixel, hàm loss này sẽ được tính dựa trên feature map giữa 2 ảnh. Các feature map này sẽ được tính dựa trên các activation layer của mạng VGG19 đã được pre-train. Gọi là feature map có được từ layer convolution thứ trước hàm max-pooling thứ trong VGG19. Hàm loss giữa ảnh sinh và ảnh được định nghĩa:
với và là chiều của feature map trong mạng VGG.
Adversarial loss
Để khuyến khích mạng tìm các solution giống với ảnh thật và đánh lừa được Discriminator, tác giả sử dụng hàm generative loss :
trong đó là xác suất ảnh sinh là ảnh thật.
Kết quả
Để đánh giá performance của model, tác giả sử dụng 3 metric: PSNR, SSIM và MOS (Mean Opinion Score, dựa trên đánh giá cảm quan của người xem trên thang từ 1 đến 5).
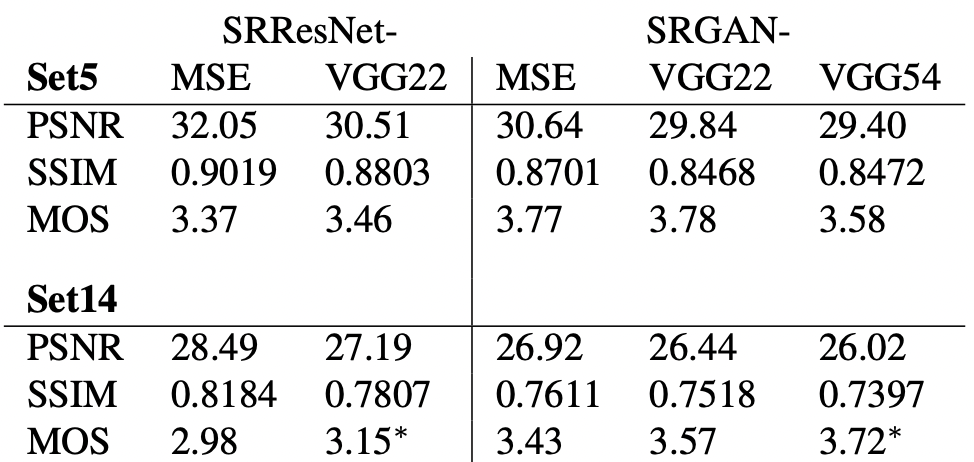
Có thể thấy, việc dùng SRGAN tuy có kết quả PSNR và SSIM kém hơn nhiều so với SRResNet, điểm MOS của mạng GAN lại cao hơn hẳn. Tương tự, MOS của SRGAN cũng cao hơn hẳn khi so sánh với các phương pháp khác (trừ HR là ảnh gốc).
Trong hình dưới đây, ta có thể thấy mạng SRGAN cho ra ảnh trông chi tiết hơn so với SRResNet khi upscale factor là 4. Khi chuyển từ MSE sang VGG22 và VGG54, các chi tiết như lòng mắt hay lông trên mặt trông cũng rõ hơn rất nhiều. Theo như tác giả bài báo, các feature map của các layer sâu hơn sẽ tập trung hoàn toàn vào nội dung của ảnh, còn adversarial loss sẽ tập trung hơn vào chi tiết của texture nên chất lượng ảnh khi upsample sẽ tốt hơn.

Kết luận
Như vậy, các đóng góp của tác giả trong bài báo bao gồm:
- Đề xuất mạng SRResNet đạt kết quả PSNR và SSIM cao khi thực hiện task upscale với factor 4x.
- Đề xuất mạng SRGAN cùng với hàm perceptual loss để thay thế cho hàm loss MSE. Hàm loss mới tính dựa trên feature map sinh ra bởi mạng VGG.
- Dùng MOS để đánh giá kết quả của SRGAN. Kết quả cho thấy SRGAN có thể upscale với hệ số rất lớn (4x) mà vẫn có thể sinh ra ảnh có chất lượng giống ảnh tự nhiên.
Tài liệu tham khảo
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Image Super-Resolution Using Deep Convolutional Networks
Accelerating the Super-Resolution Convolutional Neural Network
All rights reserved
