
[Paper explained] Non-local Neural Networks
Bài đăng này đã không được cập nhật trong 3 năm
Trong deep learning, việc lấy được các thông tin ở xa so với vị trí hiện tại khá là quan trọng. Ví dụ, với dữ liệu dạng sequence, ta có thể dùng phép recurrent để làm việc này. Còn với dữ liệu dạng ảnh, ta thường stack các phép convolution lên nhau để mở rộng receptive field. Cả hai phép này đều có đặc điểm là chúng chỉ xử lý các local neighborhood (các phép recurrent thường chỉ lấy thông tin của state ngay trước nó, còn convolution thì thường lấy các pixel xung quanh nhưng bị giới hạn bởi kích thước của kernel). Do đó, để lấy được các thông tin ở xa, ta cần lặp lại các phép tính trên nhiều lần. Việc này khiến cho khối lượng tính toán tăng lên rất nhiều lần và cần phải tối ưu thêm (ví dụ như LSTM với recurrent và residual connection với convolution).
Trong bài báo Non-local Neural Networks, các tác giả của bài báo đã giới thiệu non-local operation dựa trên phương pháp non-local means trong xử lý ảnh. Theo tác giả, việc dùng các non-local operation có 3 điểm mạnh sau:
- Có thể lấy được thông tin giữa 2 vị trí một cách trực tiếp, bất kể khoảng cách giữa chúng.
- Non-local operations hiệu quả hơn và chỉ cần dùng vài layer là có thể đạt được kết quả tốt nhất.
- Có thể dùng được khi kích thước input không cố định và có thể kết hợp được với các operation khác, ví dụ như convolution.
1. Thuật toán non-local means trong xử lý ảnh
Để hiểu được cách non-local neural networks hoạt động, đầu tiên, bài viết này sẽ giới thiệu phương pháp non-local means trong xử lý ảnh trước.
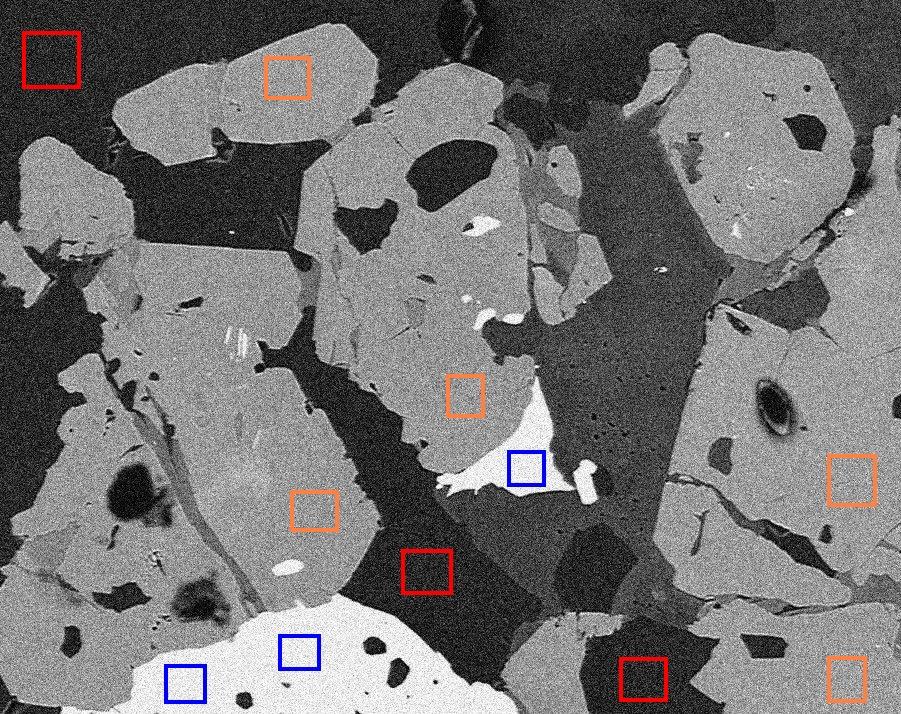
Trong xử lý ảnh, thuật toán non-local means là một thuật toán được dùng để denoise (khử nhiễu) ảnh. Khác với các thuật toán sử dụng các bộ lọc "local mean" chỉ sử dụng thông tin xung quanh của một nhóm pixel xung quanh một target pixel như mean filter, median filter,... non-local means sẽ dùng toàn bộ các pixel trong ảnh và đánh trọng số cho chúng dựa trên sự tương đồng của chúng so với target pixel (càng tương đồng thì trọng số sẽ càng cao). Ví dụ như trong hình dưới đây, nếu ta lấy một pixel trong ô màu đỏ làm target pixel thì các pixel khác trong các ô đỏ (cùng hoặc khác) sẽ có trọng số cao hơn khi so với các pixel trong các ô màu cam hoặc xanh (các ô cùng màu sẽ có sự tương đồng nhau cao).
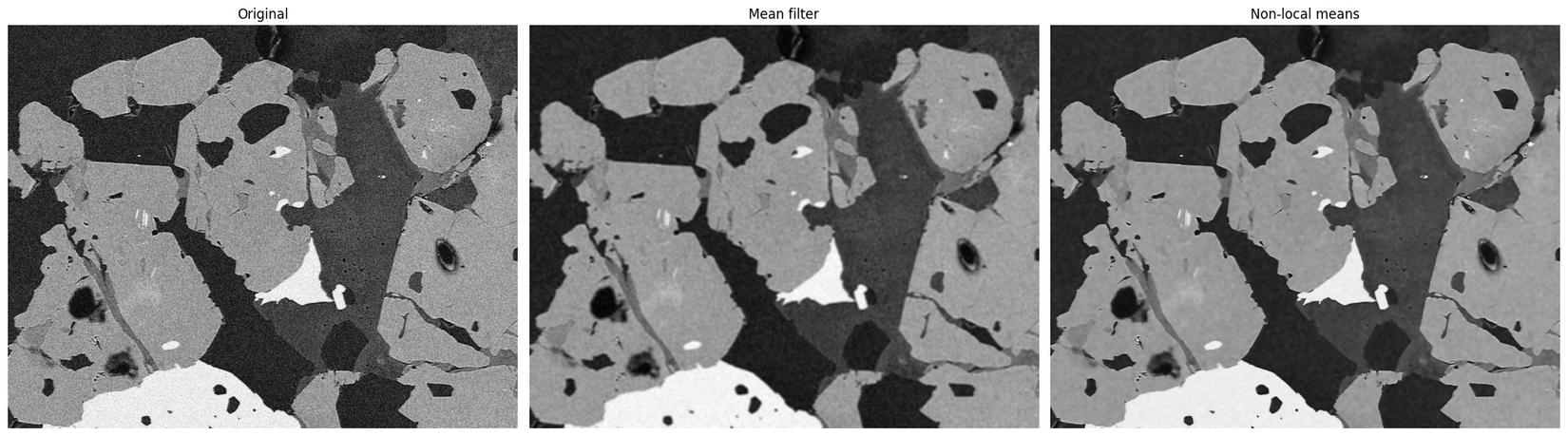
So với các thuật toán local mean, non-local means ngoài khử được noise ra còn có khả năng giữ lại được nhiều chi tiết ảnh hơn.
Thuật toán của non-local means được định nghĩa như sau. Cho một ảnh , tại một pixel , giá trị denoise của pixel được tính như sau:
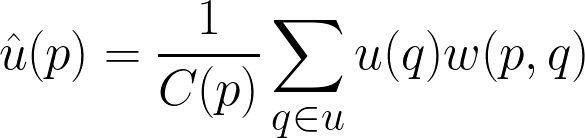
trong đó, hệ số normalize được tính như sau:
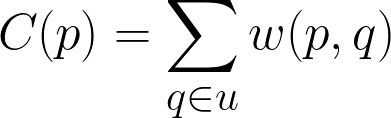
là hàm tính trọng số của pixel và . Một trong những cách tính trọng số phổ biến nhất là dùng khoảng cách Euclidean có trọng số. Gọi là giá trị trung bình của các pixel xung quanh pixel , là một tham số điều chỉnh mức độ giảm của trọng số khi khoảng cách Euclidean tăng.
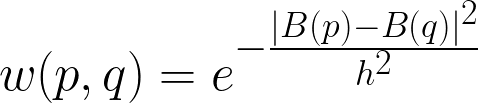
Trong thư viện scikit-image đã có sẵn hàm denoise_nl_means (doc) dùng để thực hiện phép non-local means trên ảnh. Bạn có thể tham khảo document và code chạy trên Colab.
2. Non-local neural network
2.1. Non-local operation
Dựa trên định nghĩa của non-local means, tác giả bài báo này đã định nghĩa phép non-local trong mạng deep neural network như sau:
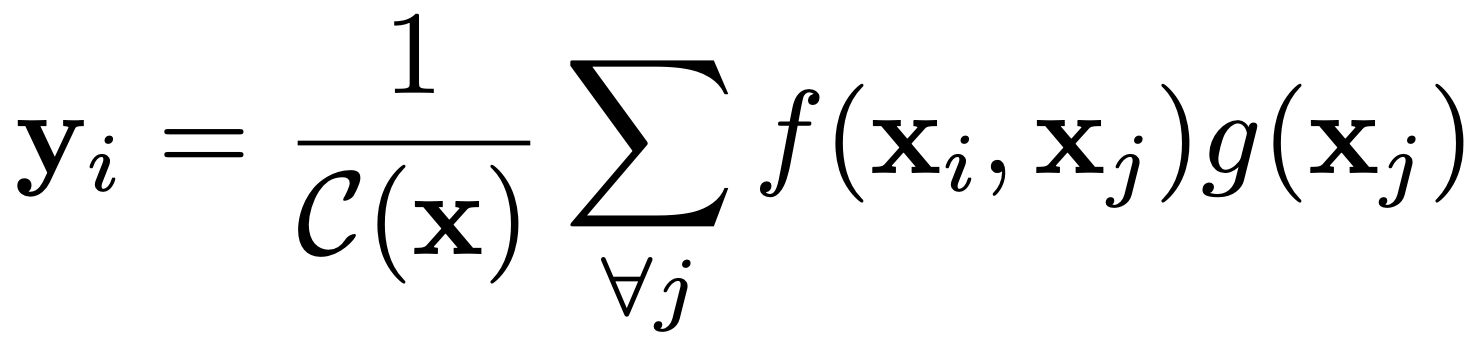
Trong công thức trên, là index của vị trí cần tính giá trị response, còn là index tất cả các vị trí trong input. là input (thường là feature của ảnh, chuỗi hoặc video), là output có cùng kích thước với . Tương tự như non-local means, là hàm tính trọng số và là hệ số normalize. Khác với công thức của non-local means, trong công thức này, thay vì dùng thẳng giá trị input của , ta sẽ đưa nó qua một hàm để tính trước. Để cho đơn giản, bài báo coi là một hàm linear embedding: với là một ma trận trọng số cần được huấn luyện.
Đối với hàm , tác giả bài báo có thử vài lựa chọn như sau:
- Gaussian: . Khi đó, .
- Embedded Gaussian: với và là 2 embedding cần học. tương tự như trên. Với lựa chọn này, việc tính cũng khá giống với phương pháp self-attention nhưng hay hơn ở chỗ là nó dùng được cho dữ liệu dạng ảnh và video.
Hai lựa chọn trên giống nhau ở chỗ là chúng đều có dạng của hàm softmax. Còn hai lựa chọn tiếp theo thì hoàn toàn không:
- Dot product: . Khi đó, với là số lượng vị trí trong để cho việc tính toán gradient được đơn giản hoá.
- Concatenation: với là phép concat, là trọng số cần học. Khi đó, như trên.
2.2. Non-local Block
Với phép non-local ở trên, ta có non-local block được định nghĩa như sau:
với được tính như trong mục 2.1, "+" là residual connection. Theo tác giả, việc này giúp ta có thể thêm non-local block vào bất kỳ mạng neural đã được huấn luyện mà không làm thay đổi hành vi ban đầu của nó nếu như được khởi tạo bằng . Giả sử với là embedded Gaussian, ta sẽ có một non-local block như hình dưới đây.
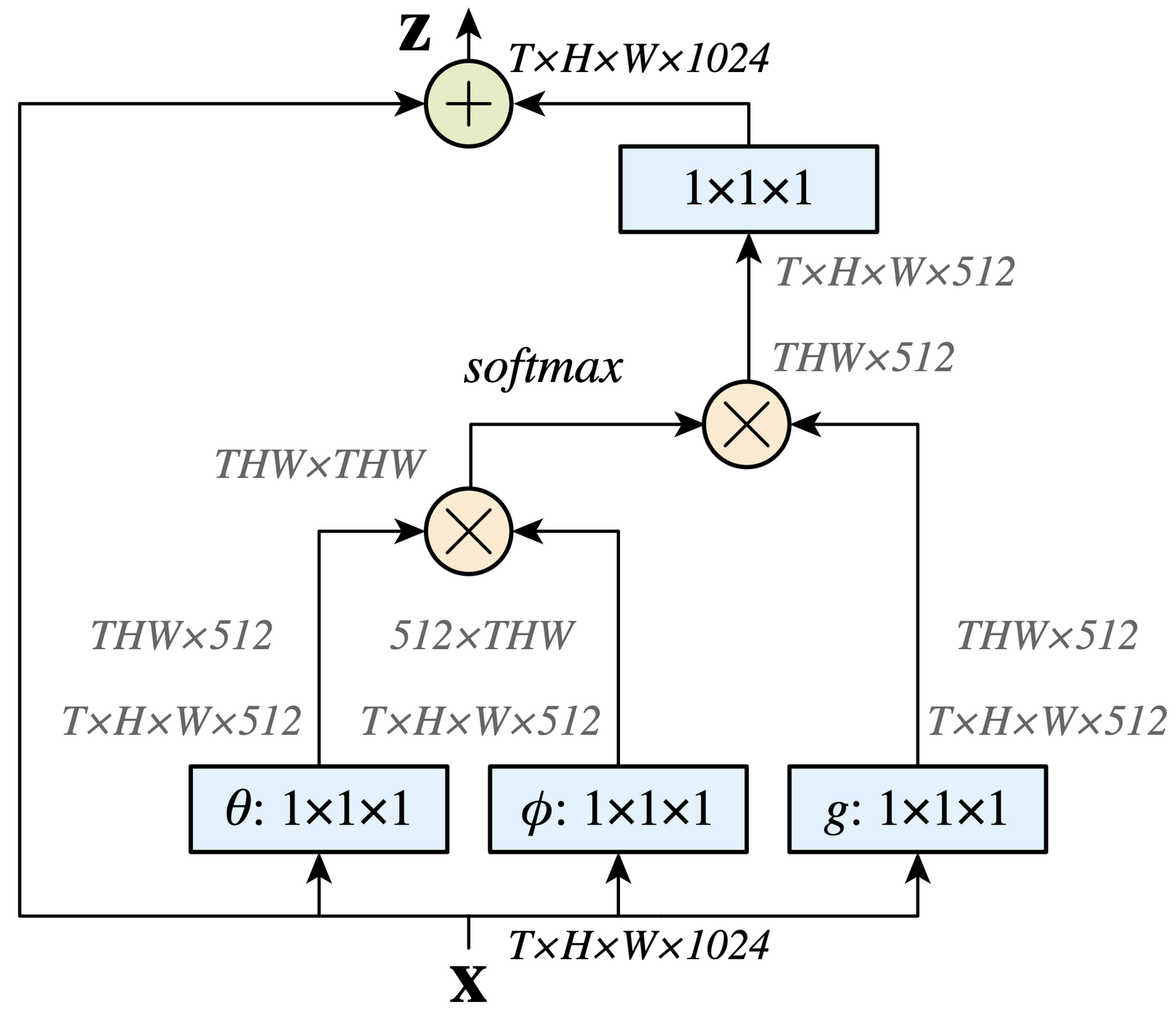
Để giảm khối lượng tính toán, số lượng channel đầu ra của , và sẽ bằng một nửa so với của . Còn ma trận trọng số sẽ đóng vai trò tính embedding cho từng vị trí một trên với số lượng channel khớp với của . Ngoài ra, tác giả còn đề xuất việc subsample bằng cách đặt layer pooling ngay sau và . Khi đó, khối lượng tính toán sẽ được giảm còn mà không làm thay đổi bản chất non-local.
3. Thí nghiệm
3.1. Video Classification
Để thí nghiệm, tác giả đã dùng 3 model. Tất cả đều có input là video 32 frames có kích thước .
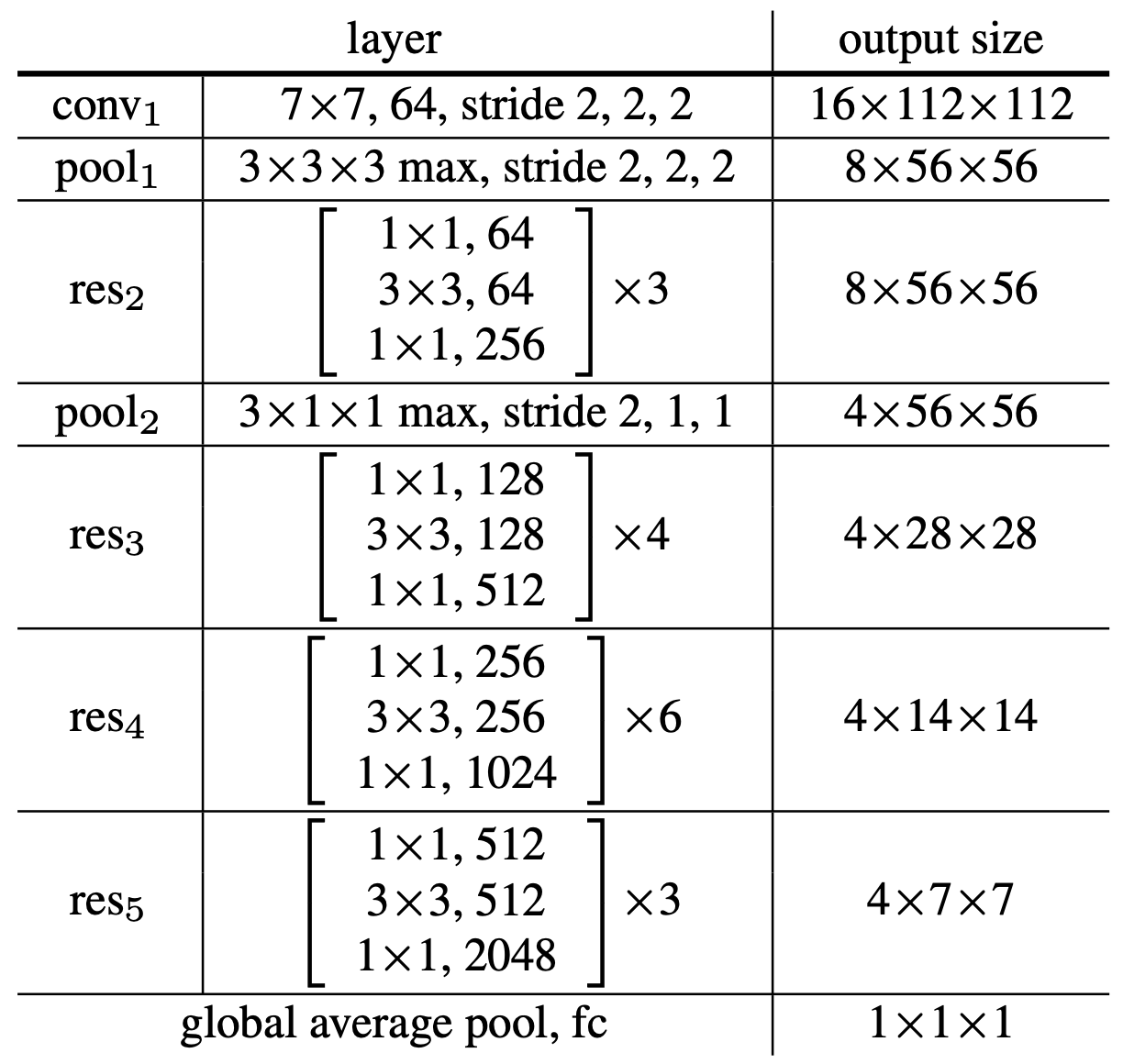
- 2D ConvNet baseline (C2D): model này chỉ xử lý video trên từng frame một. Weight được khởi tạo từ ResNet. Kiến trúc của model có dạng như hình trên.
- Inflated 3D ConvNet (I3D): là model C2D nhưng các kernel được inflated (làm phồng lên) từ thành . Với mô hình này, trọng số của layer 3D có thể được lấy từ layer 2D tương ứng của ResNet rồi scale xuống .
- Non-local network: là 1 trong 2 model baseline C2D hoặc I3D nhưng có thêm các số lượng non-local blocks khác nhau ở từng stage () cụ thể.
Với việc thêm các phép non-local vào model C2D giúp cho việc huấn luyện model trở nên tốt hơn rất nhiều trên cả bộ train và validation.
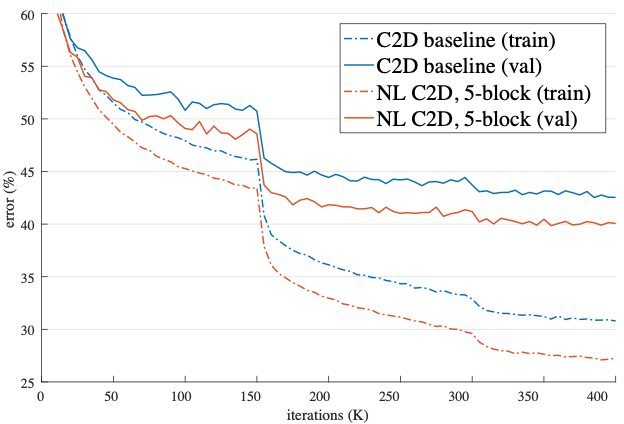
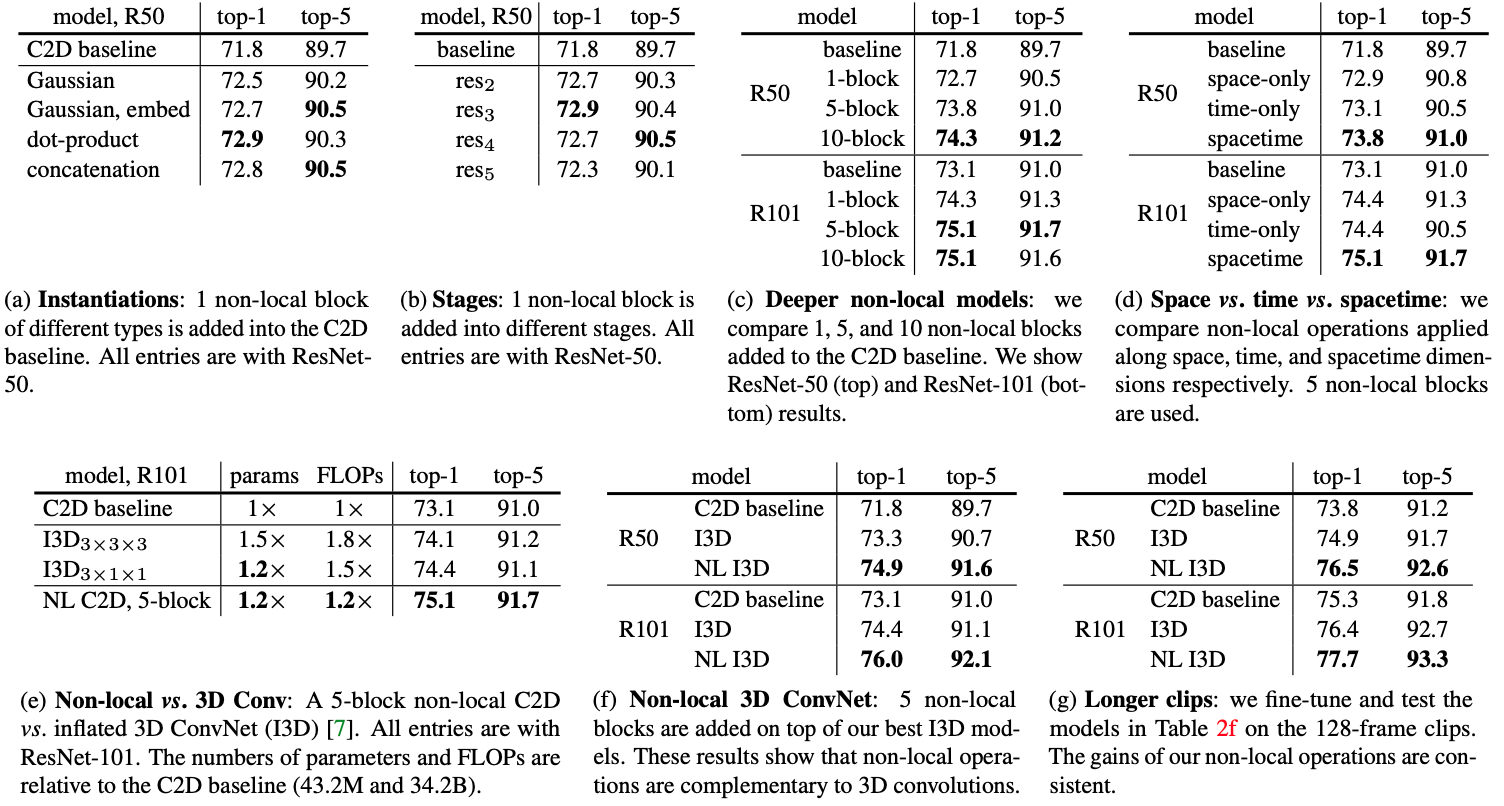
Từ bảng so sánh kết quả thí nghiệm trên, ta có thể thấy:
- Việc thêm non-local vào, dù chỉ dùng có 1 block, cũng giúp kết quả tăng khoảng so với model baseline.
- Các phương pháp chọn hàm như embedded Gaussian, dot product hay concatenation đều có hiệu năng ngang ngửa nhau.
- Việc thêm non-local block ở stage chỉ cải thiện được một chút so với khi thêm ở các stage trước đó. Điều này có thể được giải thích là do stage này có kích thước khá nhỏ nên nó không cung cấp đủ thông tin.
- Tăng số lượng non-local block cũng làm tăng performance của model. Theo tác giả, điều này xảy ra do việc thêm block vào khiến cho thông tin có thể được chuyển qua lại dễ dàng hơn.
- So với I3D, model có kết quả tốt hơn trong khi có số lượng param như nhau và lượng phép tính toán ít hơn. Ngoài ra, non-local neural network cũng cho kết quả tốt hơn đối với các video có thời lượng dài.
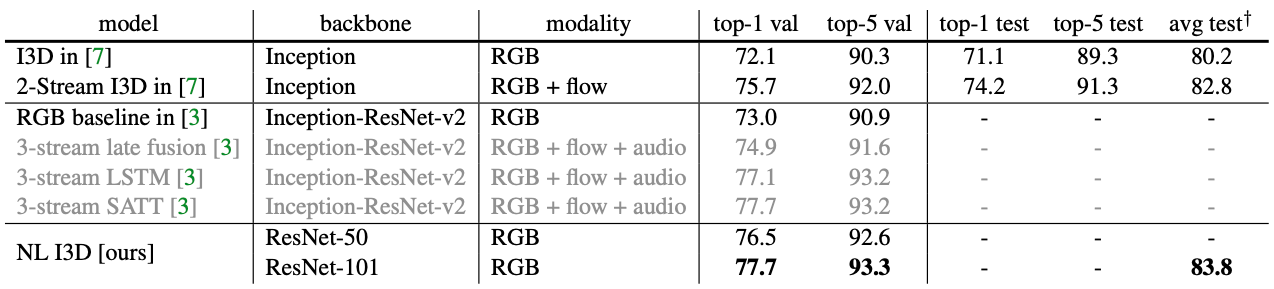
Trên bộ Kinetics, kết quả của non-local I3D cũng vượt qua được các phương pháp chỉ sử dụng thông tin RGB. Ngoài ra, chỉ với thông tin RGB, non-local I3D cũng có performance ngang ngửa với các phương pháp SOTA khác mà không cần đến các thông tin khác như optical flow hay âm thanh.
Trong hình dưới đây, tác giả paper đã visualize một non-local block với 20 cặp và có trọng số cao nhất của mỗi điểm . Coi điểm bắt đầu của mũi tên là và đầu mũi tên là . Hình trên cho thấy việc thêm non-local block giúp cho model có thể tìm các feature liên quan để cải thiện kết quả predict của nó bất kể ở xa hay gần về mặt không gian và thời gian.

3.2. Object Detection, Instance Segmentation và Keypoint Detection
Với task Object Detection và Instance Segmentation, thí nghiệm của tác giả cho thấy rằng chỉ cần thêm 1 non-local block là có thể giúp cải thiện model baseline do block này giúp model có khả năng bắt được các thông tin non-local một cách hiệu quả. Ngoài ra, việc thêm non-local block chỉ tăng một lượng tính toán nhỏ và việc thêm nhiều hơn cũng không cải thiện model được nhiều.
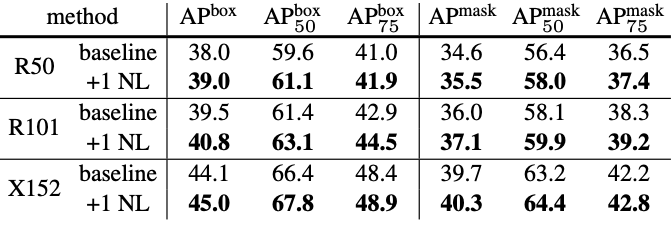
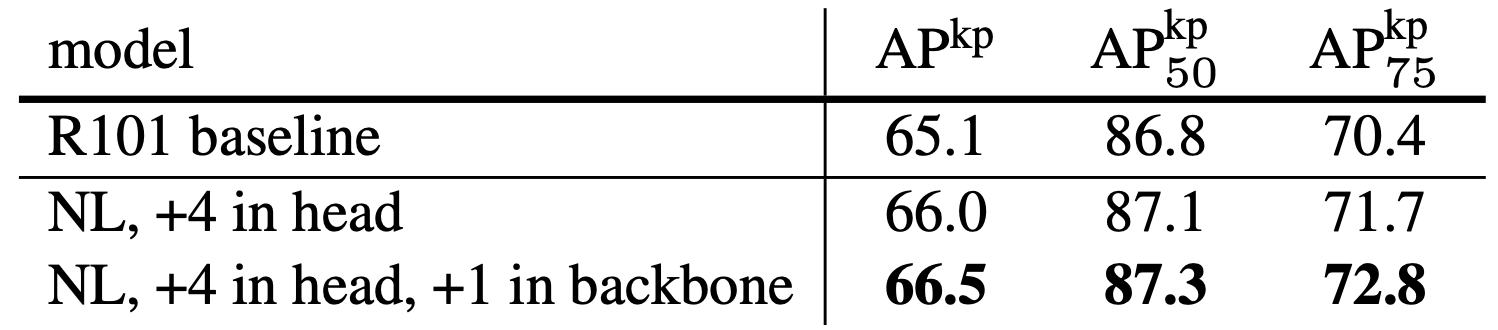
Với task Keypoint Detection, performance của model cũng được cải thiện khi thêm non-local block, nhất là khi thêm vào backbone.
4. Kết luận
Như vậy, bài báo đã cho ta thấy rằng việc thêm non-local block vào model có thể giúp nó bắt được thông tin ở xa về mặt thời gian lẫn không gian, cải thiện hiệu năng đáng kể so với model gốc.
Tham khảo
- Buades, Antoni, Bartomeu Coll, and J-M. Morel. "A non-local algorithm for image denoising." 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05). Vol. 2. Ieee, 2005.
- Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
All rights reserved
