[Paper Explained] Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu
Trong bài toán super resolution, mạng CNN đã chứng tỏ được sức mạnh của nó trong bài toán này với độ chính xác vượt trội hơn so với các phương pháp truyền thống. Chỉ với vài 3 lớp layer convolution, mạng SRCNN đã có thể outperform được phương pháp bicubic interpolation ngay ở đoạn đầu quá trình learning. Tuy vậy, trong bài báo Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, các tác giả đã đề xuất một phương pháp mới để thực hiện bài toán này mà có thể tốt hơn về accuracy và tốc độ xử lý. Để đạt được điều đó, họ đã sử dụng một kỹ thuật gọi là sub-pixel convolution layer
Vấn đề với mạng SRCNN
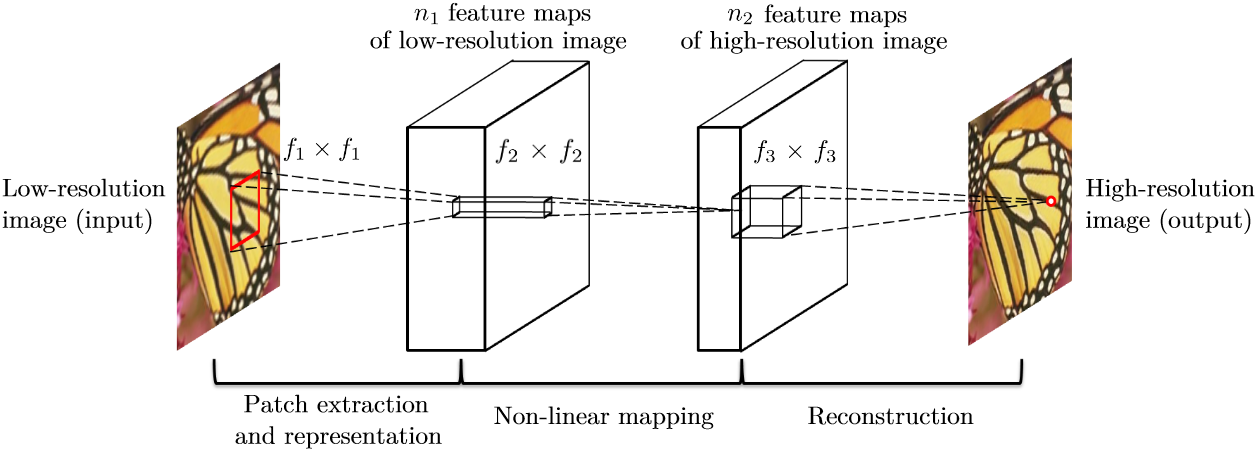
Trong mạng SRCNN, để xử lý một ảnh input low-resolution (LR), tác giả đã dùng phương pháp bicubic interpolation để upsample ảnh lên sao cho nó có kích thước giống với ảnh high-resolution (HR). Điều này có hai điểm bất lợi sau:
- Việc tăng kích thước của ảnh input cho bằng với kích thước của output khiến cho khối lượng công việc lên rất nhiều lần. Nó bao gồm upscale ảnh trước khi đưa vào model và tính toán của model với đầu vào là ảnh đã upsample (có kích thước gấp nhiều lần so với ảnh nhỏ). Riêng với model, giả sử nếu tăng kích thước lên lần thì khối lượng tính toán sẽ đội lên lần. Điều này khiến cho mạng SRCNN có thời gian chạy khá lâu và không thích hợp với các real-time application [2].
- Phương pháp bicubic interpolation không mang lại thêm thông tin gì cho model. Ngoài ra, việc dùng bicubic interpolation cũng khiến cho kết quả của model cũng bị ảnh hưởng bởi kết quả của phép nội suy này.
Do đó, tác giả bài báo Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network đã đề xuất ra một phương pháp mới để giải quyết 2 điểm yếu trên. Thay vì thực hiện việc upscale ngay ở input để khớp với kích thước high resolution của output, họ đề xuất thực hiện việc này ở cuối mạng để giảm chi phí tính toán của model.
Kiến trúc mạng Efficient Sub-Pixel Convolutional Neural Network (ESPCN)
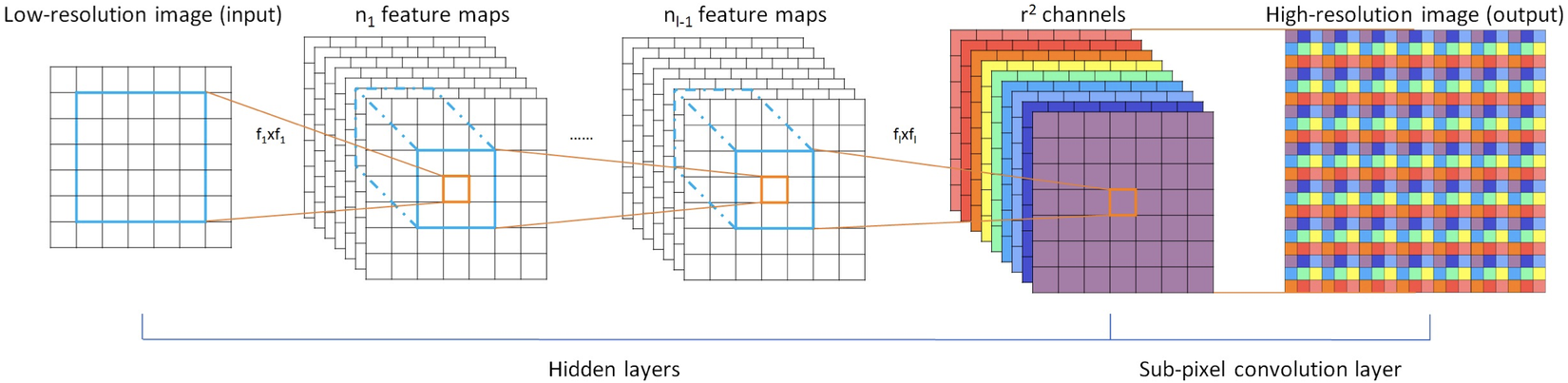
Trong mạng ESPCN của bài báo, bước feature extraction cũng được thực hiện giống như mạng SRCNN. Tuy nhiên, ESPCN khác ở chỗ ảnh input LR sẽ không được upscale bằng bicubic interpolation như SRCNN, mà nó sẽ được đưa trực tiếp qua các hidden layer (các lớp convolution) để lấy ra các feature map. Sau bước này, ta thu được các feature map ở trong không gian LR (low resolution space). Việc tiếp theo là xây dựng ảnh HR từ feature map LR đã được extract như thế nào? Giả sử, từ một ảnh LR với kích thước , ta cần upscale nó lên ảnh HR với kích thước ( là hệ số upscale).
Một phương pháp đầu tiên ta có thể nghĩ đến đó là dùng một lớp deconvolutional layer (hay transposed convolution). Nếu như các lớp convolutional layer được dùng chủ yếu để giảm chiều không gian (gồm height và width), thì lớp deconvolutional layer được dùng để đảo lại việc đó, tức là tạo ra output có height và width lớn hơn so với input. Thực ra, phép nội suy bicubic interpolation trong mạng SRCNN cũng được coi như là một deconvolutional layer do nó cũng được dùng để tăng kích thước của input.
Sub-pixel
Khi chụp một tấm ảnh số, hệ thống hình ảnh (imaging system) của camera sẽ chiếu khung cảnh (scene) lên một image plane rồi thực hiện bước sampling và quantize để ra được một tấm ảnh số. Bước sampling ở đây sẽ dùng để số hoá (digitize) toạ độ lấy mẫu ra các pixel, còn bước quantize dùng để số hoá giá trị của từng pixel. Do giới hạn của sensor, ảnh sẽ thường bị giới hạn ở một độ phân giải nhất định. Vì thế, trên ảnh đó ta sẽ không có thêm thông tin gì ở giữa hai pixel cạnh nhau. Tuy nhiên, ở trong thế giới thực, ta có thể có rất nhiều các pixel nằm giữa 2 pixel đó. Các pixel nằm giữa đó sẽ được gọi là sub-pixel. Như hình ví dụ dưới đây, các điểm đỏ vuông là các điểm được lấy mẫu và sẽ xuất hiện ở trong bức ảnh, còn các điểm đen tròn nằm giữa sẽ không được lấy mẫu và đây chính là các sub-pixel.

Efficient sub-pixel convolution layer
Trong paper này, tác giả giới thiệu một loại layer mới là sub-pixel convolution layer. Layer này gồm 2 bước, bước đầu tiên là convolution thông thường để đưa ra output là , bước còn lại là shuffle lại pixel để cho ra output là , đúng với độ phân giải của . Bước pixel shuffle này được thực hiện bằng cách coi mỗi pixel trên feature map là các sub-pixel, ta sẽ sắp xếp lại chúng theo một thứ tự nhất định ở trên ảnh đầu ra. Hình dưới sẽ minh hoạ cách sắp xếp lại pixel để sinh ra ảnh output.
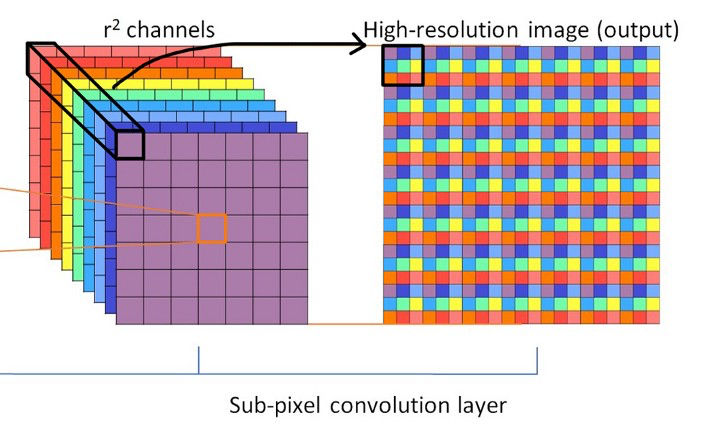
Việc dùng layer này có hai điểm lợi chính:
- Giúp ta tránh được việc phải dùng zero-padding làm ảnh hưởng đến kết quả output.
- Dùng deconvolution layer sẽ khiến cho chi phí tính toán tăng lên do phép convolution được thực hiện trong không gian high-resolution.
Kết quả
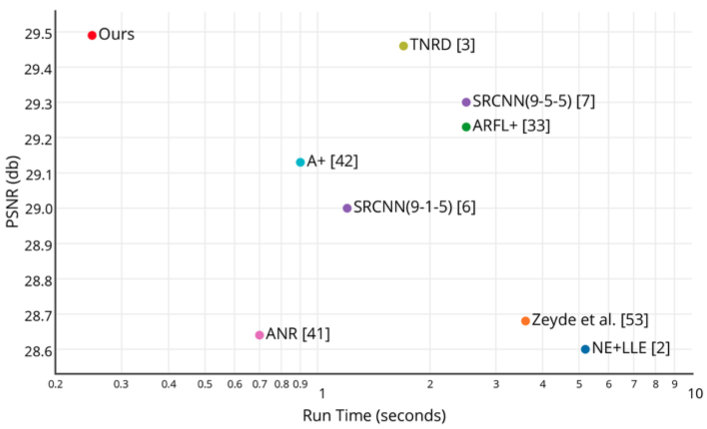
Mạng ESPCN có kết quả nhỉnh hơn chút so với các mạng khác như SRCNN và TNRD.
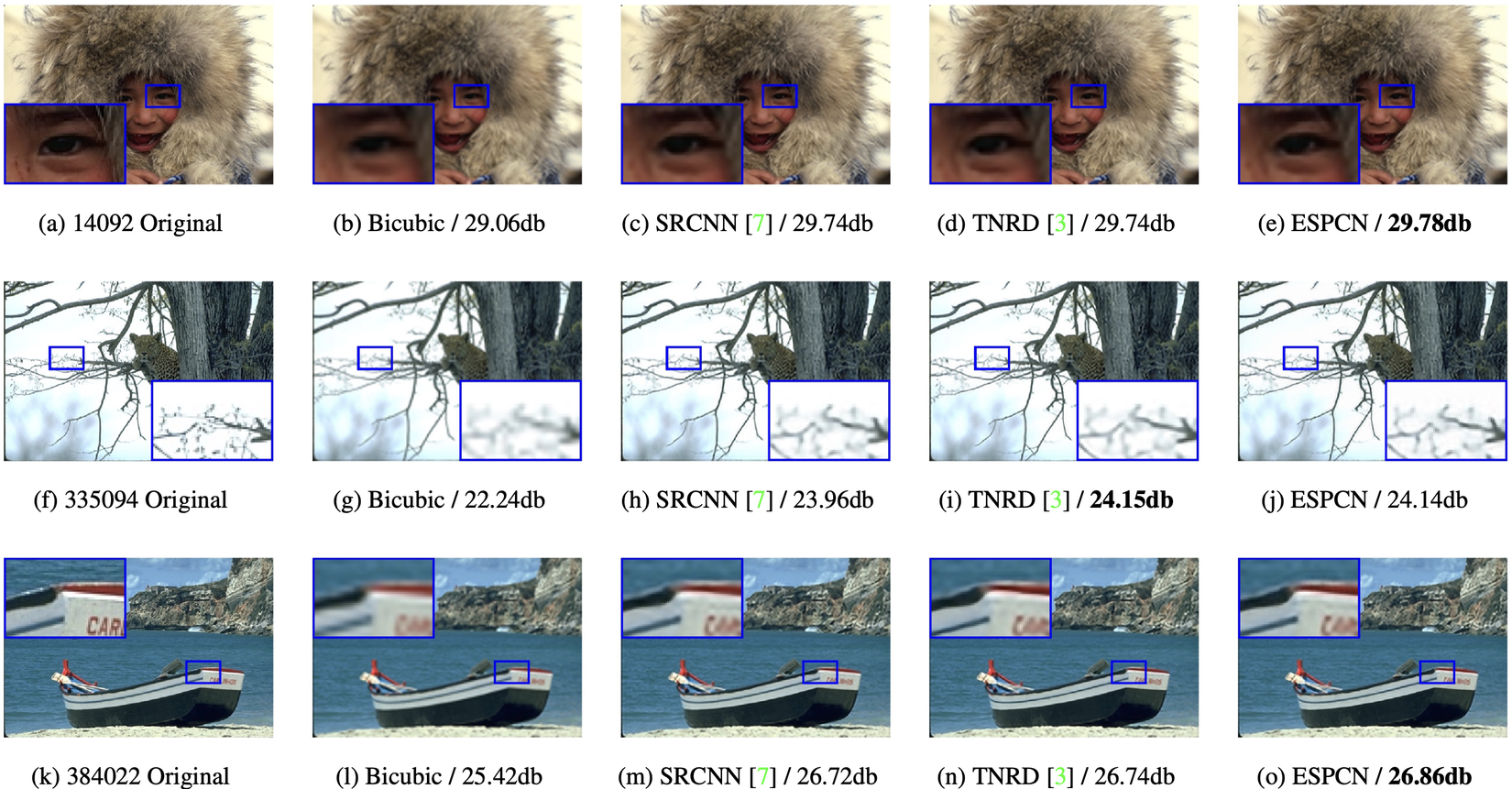
Tuy nhiên, điểm nhấn của ESPCN nằm ở thời gian chạy. Với upscaling factor là 3, thời gian chạy của ESPCN (ours) đều tốt hơn SRCNN và các mạng khác rất nhiều lần:
Kết luận
Như vậy, chỉ với lớp sub-pixel convolution và pixel shuffle, mạng ESPCN đã có thể giảm được thời gian thực hiện super-resolution đi rất nhiều lần mà độ chính xác vẫn được cải thiện so với người tiền nhiệm SRCNN.
Tài liệu tham khảo:
All rights reserved
