
[Paper explained] NISER: Normalized Item and Session Representations to Handle Popularity Bias
Bài đăng này đã không được cập nhật trong 3 năm
Nếu đã dùng qua các trang web như YouTube, có thể bạn đã từng để ý rằng một khi các bạn đã click vào một video nào đó, hệ thống của YouTube sẽ tự động gợi ý các video liên quan ở autoplay list hay là trang homepage. Điều này là do YouTube, dùng một Recommendation System để tự động gợi ý các video có độ liên quan cao đến video bạn vừa xem kể cả khi bạn đã login hay chưa login tài khoản Google. Nếu bạn chưa login hoặc dùng tab ẩn danh để xem video, YouTube vẫn có thể suggest các video liên quan ở ngay trong session của browser bởi Recommendation System của YouTube cũng có thể hoạt động theo cơ chế session-based, tức là chỉ sử dụng thông tin của session hiện tại để đưa ra các gợi ý.
1. Định nghĩa bài toán Session-based Recommendation
Gọi là một tập các session và là tập gồm item mà ta quan sát được từ . Trong mỗi session , các click event được sắp xếp theo thứ tự thời gian , trong đó, với là vị trí của item trong session . Một session có thể được mô hình hoá dưới dạng một đồ thị . Mỗi item là một node trong đồ thị. Cạnh ( là cạnh có hướng biểu diễn trình tự click từ đến . Cho một session , nhiệm vụ của Session-based Recommendation là phải dự đoán item mà người dùng có thể bằng cách tính toán một vector gồm -chiều tương ứng với item trong . Sau khi tính toán xong, item có điểm số cao nhất sẽ được lấy để tạo một danh sách top- các item được recommend. Giả sử ta có là tập hợp các video trên YouTube và một session có các item là một vài video nhạc Pop. Khi đó, trong vector của session này, các video nhạc Pop sẽ có điểm số cao hơn so với các video nhạc Rock hoặc các video không phải là ca nhạc.
2. Học biểu diễn của item và session
Trong NISER, mỗi item sẽ được biểu diễn bằng một embedding vector gồm -chiều. Với item, ta có ma trận cần phải train. Với một session có danh sách item , vector embedding của session sẽ được tính như sau: với là tham số của hàm . Trong bài báo này, mục tiêu của tác giả là tính được sao cho gần với embedding của target item với với , tức là là chỉ số của vector sát với nhất thông qua phép dot product.
Công thức để tính xác suất item tiếp theo là là:
Để tính , ta có thể tối ưu hàm cross-entropy loss:
với , tương ứng với đúng target item .
3. Chuẩn hoá embedding
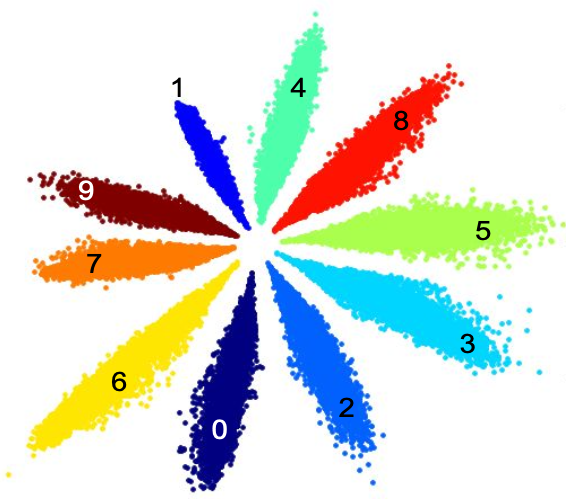
Theo [2], các features khi train bằng softmax sẽ có dạng hình tia như hình trên. Từ đó, bài báo suy luận rằng: các target item dễ đoán thường sẽ có chuẩn lớn hơn. Ví dụ như các item được click khá nhiều sẽ thường được click thường xuyên, từ đó và sẽ được huấn luyện để recommend các item này thường xuyên hơn dẫn đến hiện tượng popularity bias, các item phổ biến được recommend thường xuyên hơn so với các item không phổ biến. Điều này khiến cho performance của model giảm khi mà popularity (độ phổ biến) của item giảm.
Điều này là do softmax loss cố gắng học sao cho norm cao để phép inner product cho ra giá trị cao. Để giải quyết tình trạng này, tác giả bài báo chuyển sang dùng cosine similarity để đo độ tương đồng giữa item và session embedding thay vì dùng inner product. Item embedding sẽ được normalize và từ đó lấy được item embedding matrix đã normalize . Khi đó, session embedding sẽ trở thành và cũng được normalize thành .
Khi đó, score của item sẽ được trở thành:
với .
4. NISER
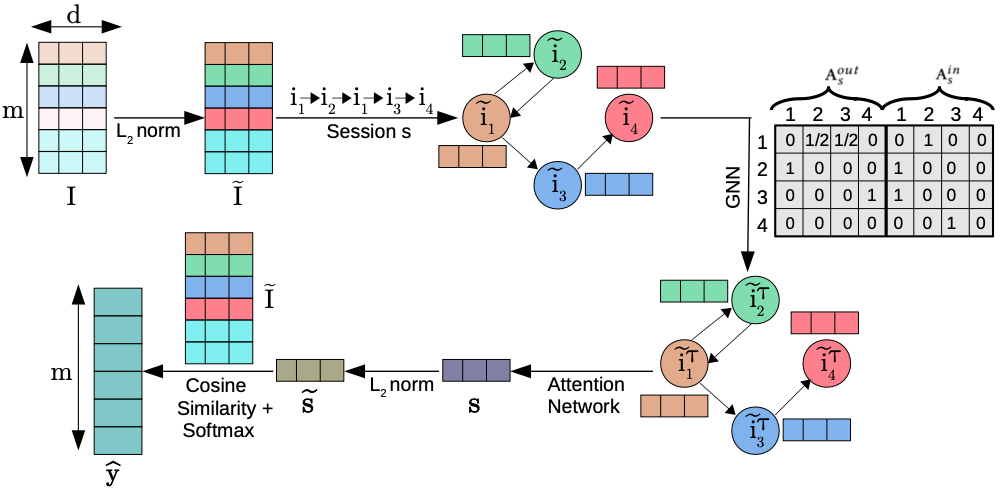
Trong bài báo này, tác giả dùng Graph Neural Network (GNN) để học embedding của item và session. Một session sẽ được biểu diễn bằng một đồ thị . Ta sẽ có hai ma trận liền kề và tương ứng với cạnh vào và ra trong đồ thị . Mạng GNN sẽ nhận , và item embedding đã normalize làm input và trả về một tập các embedding sau bước propogate thông tin trên graph:
với là trọng số của hàm GNN G. Với mỗi node, embedding của nó sẽ được cập nhật bằng embedding của nó và embedding của hàng xóm lần theo các bước sau:
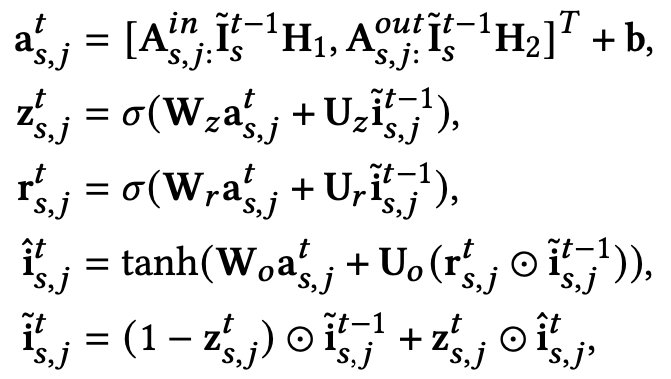
với là hàng thứ của ma trận và . , và là các tham số cần train. là hàm sigmoid và là phép nhân element-wise. Đây chính là Gated Recurrent Unit với là update gate, là reset gate.
Để cho model học được thông tin về thứ tự của item, tác giả bài báo cũng dùng thêm cả positional embedding để thêm vào mỗi item embedding, từ đó lấy được embedding của item có thông tin vị trí của nó trong session cũng như session embedding. Item embedding khi đi thêm thông tin positional sẽ trở thành với là positional embedding vector tại vị trí lấy từ ma trận , là chiều dài tối đa của tất cả các input session.
Ngoài ra, từng item ở trong session cũng được tính soft-attention weight với , . Sau đó, các weight này cũng được normalize bằng softmax và session embedding trung gian được tính . Embedding session cuối cùng sẽ là với .
5. Thí nghiệm
Có 3 metric đánh giá sẽ được dùng để đánh giá model trong bài báo này:
- Recall@K: tỉ lệ item cần xuất hiện có trong top- các item có score cao nhất.
- MRR@K (Mean Reciprocal Rank): trung bình rank của item cần xuất hiện đứng thứ bao nhiêu trong top- item có score cao nhất. Giá trị MRR lớn sẽ thể hiện là item cần xuất hiện có rank càng cao trong recommendation list.
- Average Recommendation Popularity: độ phổ biến trung bình của item được recommend trong mỗi list.
Các bộ dataset được dùng là Yoochoose, Diginetica và RetailRocket. Có 2 cách đánh giá trong bài báo này:
- Offline setting: chia bộ dataset thành train và test set, train model và đánh giá như thông thường.
- Online setting: giống với cách các live system hoạt động, model sẽ được retrain mỗi ngày bằng cách thêm các session của ngày hiện tại vào bộ train set trước đó và đánh giá trên dữ liệu của ngày tiếp theo.
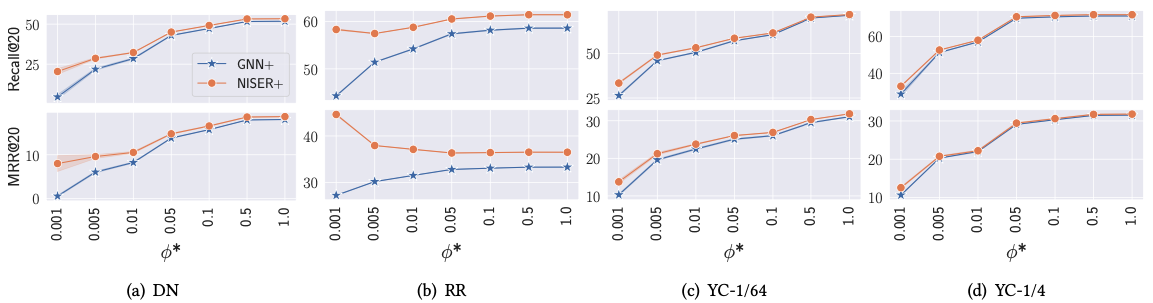
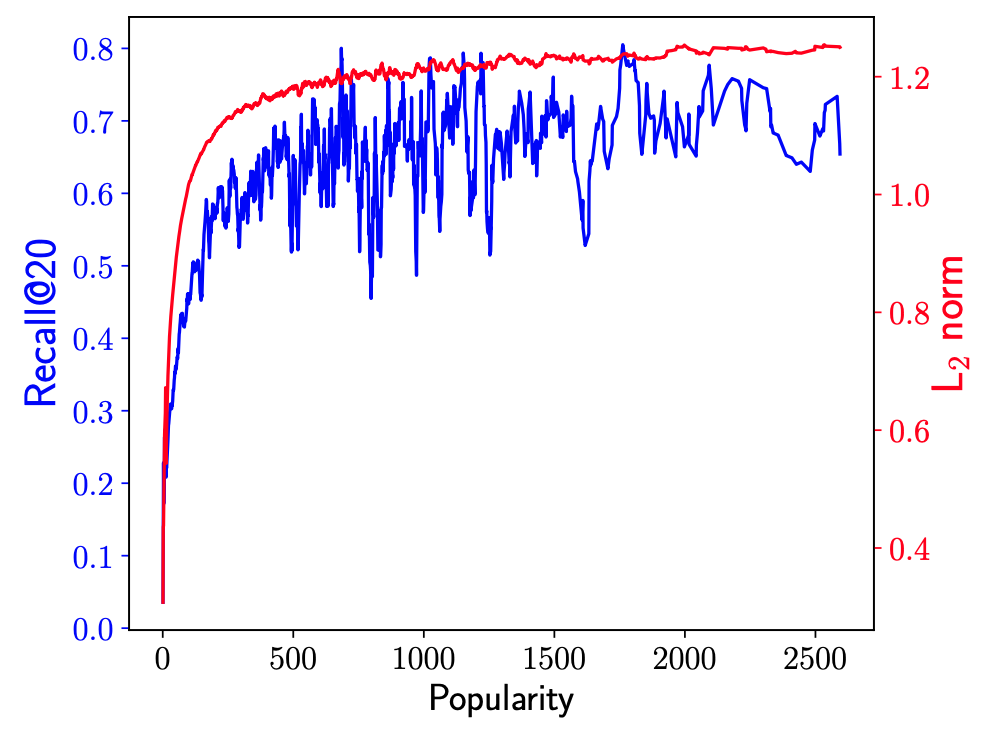
Có thể thấy từ kết quả, so với mô hình GNN bình thường, NISER đã cải thiện được hiệu năng của model khi dự đoán các item có độ popularity thấp (biểu diễn bởi ).
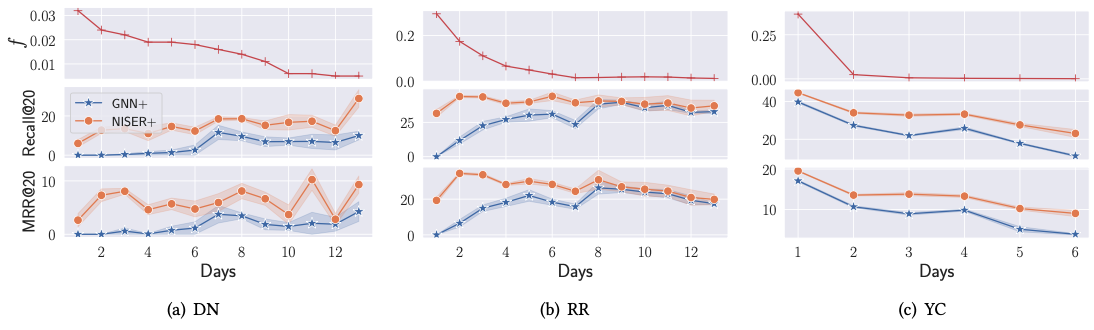
Đối với online training, NISER cũng thực hiện tốt hơn mạng GNN thông thường ngay trong những ngày đầu chạy.

Ngoài ra, NISER cũng cho ra ARP thấp hơn GNN, nghĩa là popularity bias của NISER thấp hơn, các item có popularity thấp cũng được recommend nhiều hơn.
Kết luận
Như vậy, bài báo đã cho thấy được rằng bằng cách normalize item và session embedding, ta có thể giúp cho model tránh được việc recommend các item đã quá phổ biến, cải thiện hiệu năng của hệ thống Session-based Recommendation khi popularity của item thấp.
Tham khảo
- Gupta, Priyanka, et al. "NISER: Normalized item and session representations to handle popularity bias." arXiv preprint arXiv:1909.04276 (2019).
- Zheng, Yutong, Dipan K. Pal, and Marios Savvides. "Ring loss: Convex feature normalization for face recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
All rights reserved
