Redis for true high loads
Bài đăng này đã không được cập nhật trong 4 năm
Redis for true high loads

Introduction
Surely most backend developers were dealing with the NoSQL Redis. I think many of them were wondering how to set up Redis so that it would fit under high loads, so that you could open hundreds of thousands of sockets for working with data. This is a really highload, so let's explore the best practices for setting up systems together.
Since the theme of setting for high loads is quite extensive and involves many aspects of the system's infrastructure, I will try to reduce the size of the material, showing only real settings with examples and descriptions to them, for which this setting is required.
Disclaimer
The following text and examples of commands are provided for informational purposes and that you understand the main directions for setting up the Redis server and operating system. Their implementation on production servers lies entirely on your responsibility. I recommend that you study each setting individually. Do not copy examples of commands thoughtlessly right into the terminal before you understand their effect and possible consequences.
Configuring OS for Redis server
In order to provide the best performance and reduce overhead hardware costs for working with data we need to make some adjustments to the operating system. These settings are highly recommended. I would like to draw your attention to the fact that all the recommendations and examples of commands apply only to the UNIX family of operating systems. The commands may differ in different OS, however, in each of them, it is possible to configure the following characteristics.
-
Tuning the kernel memory
Under high performance conditions we noticed the occasional blip in performance due to memory allocation. To avoid problems with the operation of Redis (point 3 of the manual), you should disable the Transparent HugePages kernel function. Execute in the terminal:
echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
Add the following lines to the /etc/rc.local file so that after the server reboot this function has been disabled:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo 'never' > /sys/kernel/mm/transparent_hugepage/defrag
fi
After this command, you need to restart the server:
service redis restart
-
The maximum value of the connection queue
Open the configuration file:
nano /etc/rc.local
Find the following line in the configuration body and set the same value as indicated below:
sysctl -w net.core.somaxconn=65535
-
Disable SWAP
Detailed information on the impact of SWAP on performance is described in the official documentation
echo 0 > /proc/sys/vm/swappiness
-
Enabling CPU RPS
Redis is mostly single threaded application. To ensure that redis is not running on the same CPU as those handling any network traffic, it is highly recommended that RPS is enabled.
The following setting will allow you to distribute the Redis server to all processor cores on your server. The value of the number of cores you must independently change to the amount that is on your physical server.
The rps_cpus files use comma-delimited CPU bitmaps. Therefore, to allow a CPU to handle interrupts for the receive queue on an interface, set the value of their positions in the bitmap to 1. For example, to handle interrupts with CPUs 0, 1, 2, and 3, set the value of rps_cpus to 00001111 (1+2+4+8), or f (the hexadecimal value for 15).
To enable RPS on CPUs 0-1 (need root privileges):
echo '3' > /sys/class/net/eth0/queues/rx-0/rps_cpus
'3' we recorded a value of the above rules 1 + 2 = 3, to the first two cores eth0* - Replace with your network interface, probably it can be eth1
To set the CPU affinity for redis to CPUs 2-8:
# config is set to write pid to /var/run/redis.pid
$ taskset -pc 2-8 `cat /var/run/redis.pid`
pid 8946's current affinity list: 0-8
pid 8946's new affinity list: 2-8
If you have a dual-core processor, the values are as follows:
echo '1' > /sys/class/net/eth0/queues/rx-0/rps_cpus
taskset -pc 1 `cat /var/run/redis.pid`
Above is an example of the performance boost from a stock compile on a temporary host:
| RPS Status | Get Operations/second | Set Operations/second |
|---|---|---|
| Off | 761.15 | 777.22 |
| On | 834 .45 | 859 .87 |
-
Limits
Set file descriptor limits for the redis user. If you have not set the correct number of file descriptors for the redis user, you may see the following lines:
ulimit -Sn 101000 # This will only work if hard limit is big enough.
sysctl -w fs.file-max=1024000
redis*soft nofile 65535
redis hard nofile 65535
Information about the limits of the output of the buffer and why it is needed can be found in the official documentation
Attention! If you set a sufficiently large value for the available file descriptors, then you must have the hardware capability to work with so many files. HDD with low speed can become a bottleneck in your system. It is highly recommended to use SSD disks.
Configuring the Redis Server
- Use only the UNIX socket if possible. if your Redis server and client are located within the local machine. This will reduce the cost of TCP connection by at least 30%, since the unix socket works without the overhead of establishing a connection, in particular
getaddrinfo,bind,ntohs. Information on the differences between these two types of connection can be obtained from the Redis source code server (here and here)
Comparative timetable for unixsocket and TCP:
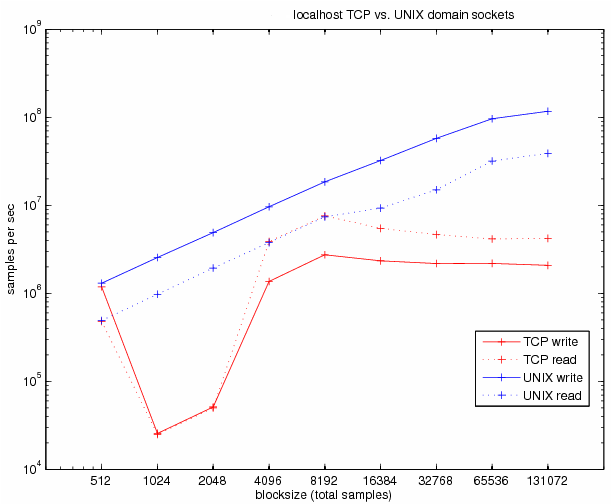
From the above it follows that you need to disable TCP for Redis in the config redis.conf
# Accept connections on the specified port, default is 6379.
# If port 0 is specified Redis will not listen on a TCP socket.
port 0
-
Setup UDS
Set the following values in the redis.conf configuration
unixsocket /var/run/redis.sock
unixsocketperm 777
-
Disable background saving to disk
Redis will attempt to persist the data to disk. While redis forks for this process, it still slows everything down. Comment out the lines that start with save in redis.conf:
#save 900 1
#save 300 10
#save 60 10000
-
Maxclients
The default is 10000 and if you have many connections you may need to go higher.
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
maxclients 100000
-
Memory usage
By default redis is set to suck up all available memory on the box. Better to set this to 75-80% of the system memory using a facter fact. When running several instances of redis on a single machine this should be tuned down. This setting can be changed on a running process.
# memory size in bytes // 12 of 16gb
maxmemory 12884901888
-
Hardware Throughput
Try to work with data in small portions, since this will significantly increase the speed of processing requests. Take a look at the graph to understand the dependence of the amount of data on time:
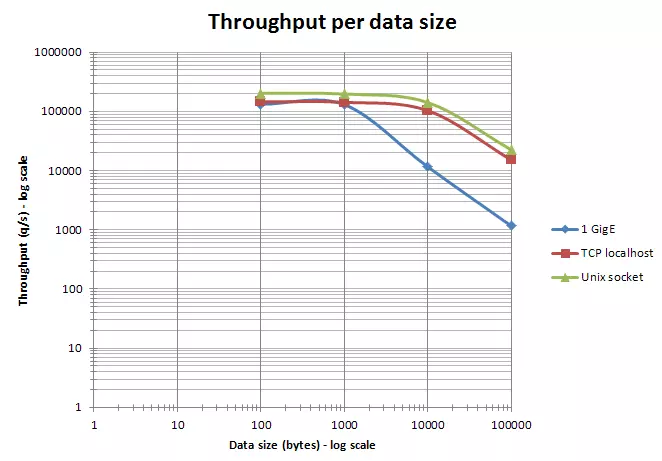 It can be seen from the graph that the packet size is not more than 1000 bytes is the most preferable. Thus, the data can be transferred within the same package, which creates the best bandwidth for the hardware of your server.
The larger the packet size, the longer the delay, and this is the transmission of data in several packets to the client and the speed limit of the network interface.
It can be seen from the graph that the packet size is not more than 1000 bytes is the most preferable. Thus, the data can be transferred within the same package, which creates the best bandwidth for the hardware of your server.
The larger the packet size, the longer the delay, and this is the transmission of data in several packets to the client and the speed limit of the network interface.
Verifying the results of the configuration
In order to check for real improvements, or vice versa, you can make test measurements using the built-in utility redis-benchmark
redis-benchmark -s /path/to/your/redis.sock -c 100 -n 100000 -d 256 -q
It is recommended to change the parameters -c 100 -n 100000 -d 256 and monitor the test results in order to make timely conclusions about the current state of your system settings.
On multi CPU sockets servers, Redis performance becomes dependant on the NUMA configuration and process location. The most visible effect is that redis-benchmark results seem non deterministic because client and server processes are distributed randomly on the cores.
General recommendations
- The performance benefit of unix domain sockets compared to TCP/IP loopback tends to decrease when pipelining is heavily used (i.e. long pipelines).
- It is possible to achieve higher throughput by tuning the
NIC(s)configuration and associated interruptions. Best throughput is achieved by setting an affinity betweenRx/Tx NICqueues and CPU cores. - Depending on the platform, Redis can be compiled against different memory allocators (
libc malloc,jemalloc,tcmalloc), which may have different behaviors in term of raw speed, internal and external fragmentation. If you did not compile Redis by yourself, you can use the INFO command to check themem_allocatorfield. Please note most benchmarks do not run long enough to generate significant external fragmentation (contrary to production Redis instances). - A good practice is to try to run tests on isolated hardware as far as possible. If it is not possible, then the system must be monitored to check the benchmark is not impacted by some external activity.
- Some configurations (desktops and laptops for sure, some servers as well) have a variable CPU core frequency mechanism. The policy controlling this mechanism can be set at the OS level. Some CPU models are more aggressive than others at adapting the frequency of the CPU cores to the workload. To get reproducible results, it is better to set the highest possible fixed frequency for all the CPU cores involved in the benchmark.
- An important point is to size the system accordingly to the benchmark. The system must have enough RAM and must not swap. On Linux, do not forget to set the
overcommit_memoryparameter correctly. Please note 32 and 64 bits Redis instances have not the same memory footprint. - If you plan to use
RDBorAOFfor your benchmark, please check there is no other I/O activity in the system. Avoid putting RDB or AOF files onNASorNFSshares, or on any other devices impacting your network bandwidth and/or latency - Set Redis logging level (loglevel parameter) to warning or notice.
Conclusion
Redis is extremely useful in many types of environments, but can be a little daunting at first. By following the best practices, it can perform as a rock solid caching layer to speed up your application.
Helpful links
All rights reserved
