Redis Stack: Có gì hay?
Bài đăng này đã không được cập nhật trong 3 năm
Tản mạn
Dạo gần đây mình tình cờ được nghe về "Redis Stack", tính mình hay tò mò nên mình cũng tìm hiểu thử.
Như tên gọi thì nó là ngăn xếp Redis, hiểu đơn giản thì ngăn xếp này sẽ chứa các modules nhằm phục vụ 1 mục đích riêng biệt như RedisJSON, RediSearch, RedisGraph, RedisTimeSeries và RedisBloom.
Chắc hẳn các bạn làm các ứng dụng web cũng đã sử dụng qua Redis để làm tầng cache giúp tăng tốc cho ứng dụng của mình.
Dưới đây là 1 mô hình điển hình về việc thiết lặp cache trong Redis:
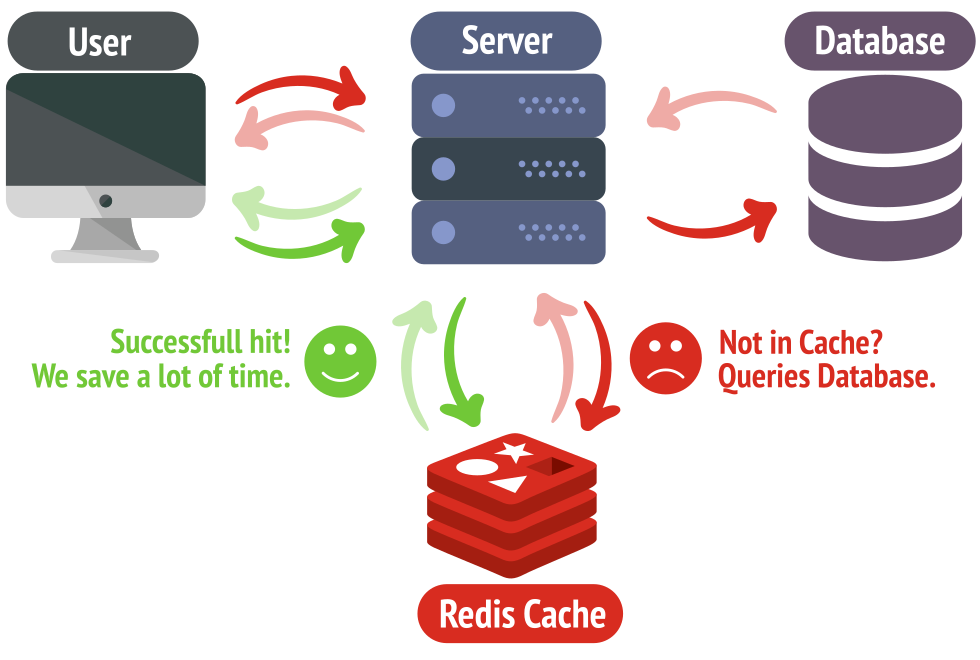
Giải thích ngắn gọn cho mô hình trên là chúng ta sẽ ưu tiên lấy dữ liệu từ cache, nếu cache data không tồn tại thì chúng ta sẽ lấy dữ liệu từ database và sau đó cập nhật lại vào cache.
Tuy nhiên khi làm việc với cache, đôi khi chúng ta cần lưu trữ dữ liệu JSON. Với các kiểu dữ liệu hiện có trong Redis chỉ bao gồm strings, hashes, lists, sets, bitmaps, sorted sets, hyper logs và geospatial indexes. Như cách thông thường thì chúng ta sẽ phải serialize JSON data thành string để lưu.
Việc lưu trữ dữ liệu JSON dưới dạng string có thể gây khó khăn cho ứng dụng.
Bởi vì để lưu trữ dữ liệu đó dưới dạng chuỗi, chúng ta phải serialize dữ liệu trước khi lưu. Ngoài ra, khi chúng tôi cần lấy thông tin 1 trường trong phần dữ liệu, chúng ta buộc phải get toàn bộ dữ liệu, sau đó deserialize nó để lấy đối tượng JSON ban đầu, cập nhật lại và serialize lại trước khi lưu trữ.
Khá phức tạp phải không nào? Chưa dừng lại ở đó. Khi một trường duy nhất trong đối tượng cần được cập nhật, quá trình trên được lặp lại.
Giải pháp
Để tránh những nhược điểm này và cải thiện trải nghiệm cho anh em developer khi làm việc với cache, Redis stack đã offer cho ta 1 module là RedisJSON - module này cho phép chúng ta truy xuất và lưu trữ dữ liệu JSON thay vì string như truyền thống.
Nghe thật hoàn hảo đúng không nhỉ ? 
Nhưng cuộc đời thì làm gì có gì hoàn hảo, RedisJSON cũng vậy . Chúng ta sẽ phải trả giá nếu chúng ta lạm dụng nó.
Cùng tham khảo 2 hình sau để nhận thấy sự khác biệt:
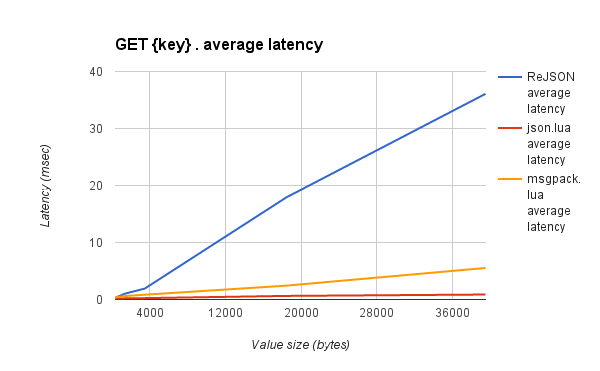
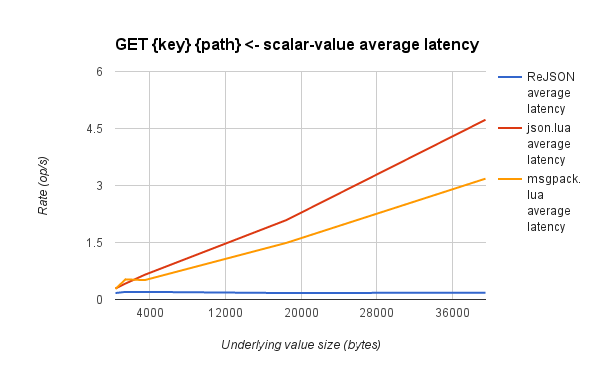
-
Về performance: Ưu điểm là việc cập nhật các sub-elements của một document sẽ nhanh hơn thao tác với một chuỗi chứa đối tượng JSON được serialize. Nhưng việc truy xuất và lưu toàn bộ document sẽ tốn kém chi phí hơn so với string.
-
Về maintainability: Sử dụng một số kiểu dữ liệu gốc trong Redis cho đối tượng JSON của bạn có thể thực sự hiệu quả, nhưng code sẽ phức tạp hơn để bảo trì. Có thể có thêm công việc migrate/refactor khi cấu trúc của document bị thay đổi.
Thực chiến
Tiếp theo chúng ta cùng nhau trải nghiệm thực tế RedisJSON nhé.
# sử dụng image Docker redis-stack-server để chạy RedisJSON với Docker
$ docker run -d --name redis-stack -p 6379:6379 –p 8001:8001 redis/redis-stack:latest
# Truy cập vào container đó thôi
$ docker exec redis-stack bash
# bật redis-cli lên nào
$ redis-cli
Chúng ta sẽ thử các thao tác GET/SET/DEL
127.0.0.1:6379> JSON.SET example $ '[ true, { "answer": 42 }, null ]'
OK
127.0.0.1:6379> JSON.GET example $
"[[true,{\"answer\":42},null]]"
127.0.0.1:6379> JSON.GET example $[1].answer
"[42]"
127.0.0.1:6379> JSON.DEL example $[-1]
(integer) 1
127.0.0.1:6379> JSON.GET example $
"[[true,{\"answer\":42}]]"
Rất đơn giản phải không!
Bài viết cũng khá dài rồi nên mình xin phép kết thúc tại đây. Bài tiếp theo mình sẽ giới thiệu tiếp về full-text search trong Redis.
Cùng chờ mình nhé.
Tài liệu tham khảo:
https://redis.io/docs/stack/json/performance/#comparison-vs-server-side-lua-scripting
All rights reserved
