Kiến thức cơ bản về kiến trúc DWH: Data Warehouse Architecture
Bài đăng này đã không được cập nhật trong 3 năm
 Data Warehouse Architecture là một phương pháp xác định kiến trúc tổng thể của quá trình xử lý và trình bày giao tiếp dữ liệu tồn tại cho máy tính của khách hàng cuối trong doanh nghiệp. Mỗi kho dữ liệu đều khác nhau, nhưng tất cả đều được đặc trưng bởi các thành phần quan trọng tiêu chuẩn.
Data Warehouse Architecture là một phương pháp xác định kiến trúc tổng thể của quá trình xử lý và trình bày giao tiếp dữ liệu tồn tại cho máy tính của khách hàng cuối trong doanh nghiệp. Mỗi kho dữ liệu đều khác nhau, nhưng tất cả đều được đặc trưng bởi các thành phần quan trọng tiêu chuẩn.
Đọc thêm:
KHOÁ HỌC TRUY VẤN VÀ THAO TÁC DỮ LIỆU SQL TỪ CƠ BẢN ĐẾN NÂNG CAO
KHÓA HỌC DATA WAREHOUSE : TỔNG HỢP, CHUẨN HÓA VÀ XÂY DỰNG KHO DỮ LIỆU TRONG DOANH NGHIỆP
KHÓA HỌC DATA MODEL - THIẾT KẾ MÔ HÌNH DỮ LIỆU TRONG DOANH NGHIỆP
LỘ TRÌNH TRỞ THÀNH DATA ENGINEER CHO NGƯỜI MỚI BẮT ĐẦU
DATA ENGINEER LÀ GÌ? CÔNG VIỆC CHÍNH CỦA DATA ENGINEER? CÁC KỸ NĂNG CẦN THIẾT
Các ứng dụng sản xuất như tài khoản trả lương phải trả khi mua sản phẩm và kiểm soát hàng tồn kho được thiết kế để xử lý giao dịch trực tuyến (OLTP). Các ứng dụng như vậy thu thập dữ liệu chi tiết từ các hoạt động hàng ngày.
Các ứng dụng Data Warehouse được thiết kế để hỗ trợ các yêu cầu dữ liệu đặc biệt của người dùng, một hoạt động gần đây được gọi là xử lý phân tích trực tuyến (OLAP). Chúng bao gồm các ứng dụng như dự báo, lập hồ sơ, báo cáo tóm tắt và phân tích xu hướng.
Cơ sở dữ liệu sản xuất được cập nhật liên tục bằng tay hoặc thông qua các ứng dụng OLTP. Ngược lại, cơ sở dữ liệu kho hàng được cập nhật định kỳ từ các hệ thống vận hành, thường là trong giờ ngoài giờ. Khi dữ liệu OLTP được tích lũy trong cơ sở dữ liệu sản xuất, nó thường xuyên được trích xuất, lọc và sau đó được tải vào một máy chủ kho chuyên dụng mà người dùng có thể truy cập. Khi kho được nhập, nó phải được cấu trúc lại các bảng không chuẩn hóa, dữ liệu được làm sạch các lỗi và phần dư thừa, các trường và khóa mới được thêm vào để phản ánh nhu cầu sắp xếp, kết hợp và tổng hợp dữ liệu của người dùng.
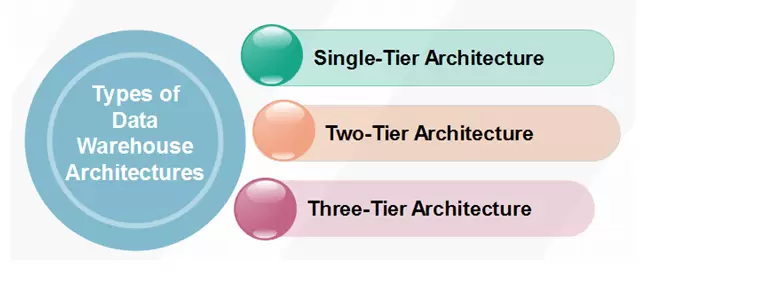
Kho dữ liệu và kiến trúc của chúng phụ thuộc rất nhiều vào các yếu tố tình huống của tổ chức.
Ba kiến trúc phổ biến là:
- Data Warehouse Architecture: Basic
- Data Warehouse Architecture: With Staging Area
- Data Warehouse Architecture: With Staging Area and Data Marts
Tóm tắt nội dung
Data Warehouse Architecture: Basic
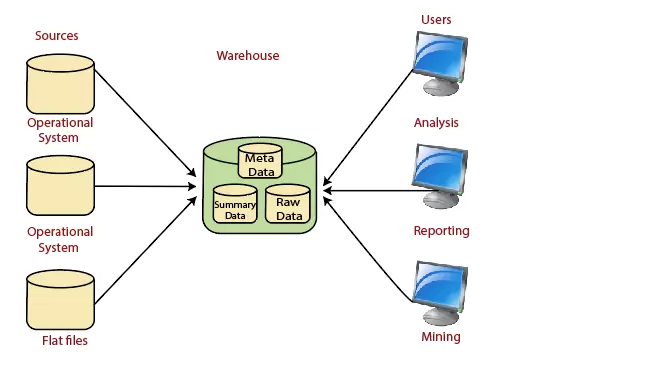 1. Operational System
1. Operational System
Operational System là một phương pháp được sử dụng trong kho dữ liệu để chỉ một hệ thống được sử dụng để xử lý các giao dịch hàng ngày của một tổ chức.
2. Flat Files
Flat Files là một hệ thống tệp trong đó dữ liệu giao dịch được lưu trữ và mọi tệp trong hệ thống phải có một tên khác.
3. Metadata
Tập hợp dữ liệu xác định và cung cấp thông tin về dữ liệu khác.
Dữ liệu meta được sử dụng trong Kho dữ liệu cho nhiều mục đích khác nhau, bao gồm:
Dữ liệu meta tóm tắt thông tin cần thiết về dữ liệu, có thể giúp việc tìm kiếm và làm việc với các trường hợp dữ liệu cụ thể dễ tiếp cận hơn. Ví dụ: tác giả, bản dựng dữ liệu và dữ liệu đã thay đổi và kích thước tệp là những ví dụ về siêu dữ liệu tài liệu rất cơ bản.
Siêu dữ liệu được sử dụng để hướng một truy vấn đến nguồn dữ liệu thích hợp nhất.
4. Dữ liệu tóm tắt nhẹ nhàng và cao
Khu vực của kho dữ liệu lưu tất cả các dữ liệu được xác định trước (tổng hợp) nhẹ và cao do người quản lý kho tạo ra.
Mục tiêu của thông tin tóm tắt là để tăng tốc hiệu suất truy vấn. Bản ghi tóm tắt được cập nhật liên tục khi thông tin mới được tải vào kho.
5. End-User access Tools
Mục đích chính của kho dữ liệu là cung cấp thông tin cho các nhà quản lý doanh nghiệp để ra quyết định chiến lược. Những khách hàng này tương tác với nhà kho bằng các công cụ truy cập khách hàng cuối.
Ví dụ về một số công cụ truy cập người dùng cuối có thể là:
- Reporting and Query Tools
- Application Development Tools
- Executive Information Systems Tools
- Online Analytical Processing Tools
- Data Mining Tools
>> Tìm hiểu thêm các kiến thức về Data Warehouse
Data Warehouse Architecture: With Staging Area
Chúng tôi phải làm sạch và xử lý thông tin hoạt động của bạn trước khi đưa vào kho.
Chúng ta có thể làm việc này theo chương trình, mặc dù các kho dữ liệu sử dụng một khu vực dàn (Nơi xử lý dữ liệu trước khi nhập kho).
Một khu vực tổ chức đơn giản hóa việc làm sạch và hợp nhất dữ liệu cho phương pháp hoạt động đến từ nhiều hệ thống nguồn, đặc biệt là đối với các kho dữ liệu doanh nghiệp, nơi tất cả dữ liệu có liên quan của một doanh nghiệp được hợp nhất.
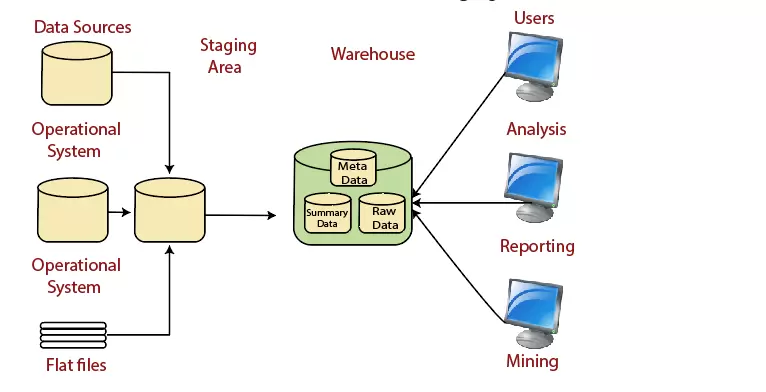 Khu vực tổ chức kho dữ liệu là một vị trí tạm thời, nơi một bản ghi từ hệ thống nguồn được sao chép.
Khu vực tổ chức kho dữ liệu là một vị trí tạm thời, nơi một bản ghi từ hệ thống nguồn được sao chép.
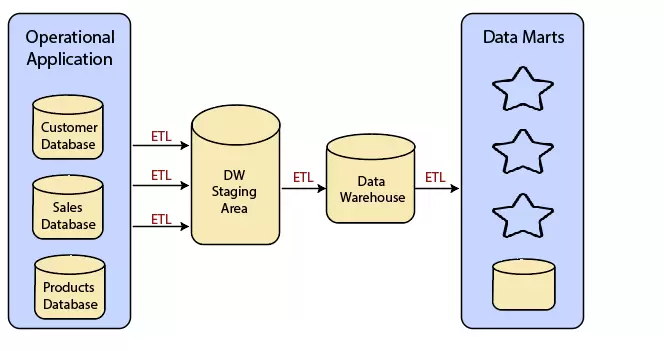
Data Warehouse Architecture: With Staging Area and Data Marts
Chúng tôi có thể muốn tùy chỉnh kiến trúc nhà kho của mình cho nhiều nhóm trong tổ chức của chúng tôi.
Chúng tôi có thể làm điều này bằng cách thêm các ổ chứa dữ liệu. Data mart là một phân đoạn của kho dữ liệu có thể cung cấp thông tin để báo cáo và phân tích về một bộ phận, đơn vị, bộ phận hoặc hoạt động trong công ty, ví dụ: bán hàng, tính lương, sản xuất, v.v.
 Thuộc tính của Data Warehouse Architectures
Thuộc tính của Data Warehouse Architectures
Các thuộc tính kiến trúc sau đây là cần thiết cho hệ thống kho dữ liệu:
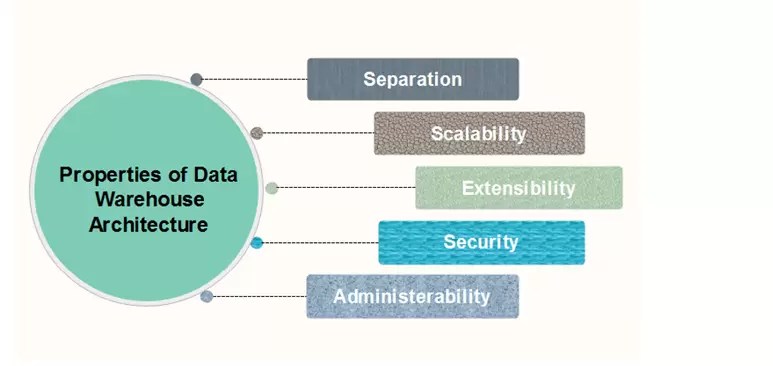 1. Separation: Quá trình xử lý phân tích và giao dịch phải càng xa nhau càng tốt.
1. Separation: Quá trình xử lý phân tích và giao dịch phải càng xa nhau càng tốt.
2. Scalability: Kiến trúc phần cứng và phần mềm phải đơn giản để nâng cấp khối lượng dữ liệu, điều này phải là con người
già đi và xử lý, đồng thời số lượng yêu cầu của người dùng phải được đáp ứng, tăng dần.
3. Extensibility: Kiến trúc phải có thể thực hiện các hoạt động và công nghệ mới mà không cần thiết kế lại toàn bộ hệ thống.
**4. Security: **Việc giám sát các truy cập là cần thiết vì dữ liệu chiến lược được lưu trữ trong các kho dữ liệu.
**5. Administerability: **Quản lý Kho dữ liệu không nên phức tạp.
Các loại Data Warehouse Architecture
Single-Tier Architecture
Kiến trúc một tầng không được sử dụng định kỳ trong thực tế. Mục đích của nó là giảm thiểu lượng dữ liệu được lưu trữ để đạt được mục tiêu này; nó loại bỏ dư thừa dữ liệu.
Hình cho thấy lớp duy nhất có sẵn về mặt vật lý là lớp nguồn. Trong phương pháp này, kho dữ liệu là ảo. Điều này có nghĩa là kho dữ liệu được thực hiện dưới dạng một cái nhìn đa chiều về dữ liệu hoạt động được tạo bởi phần mềm trung gian cụ thể hoặc một lớp xử lý trung gian.
 Lỗ hổng của kiến trúc này nằm ở chỗ nó không đáp ứng được yêu cầu tách biệt giữa xử lý phân tích và giao dịch. Các truy vấn phân tích được đồng ý với dữ liệu hoạt động sau khi phần mềm trung gian giải thích chúng. Theo cách này, các truy vấn ảnh hưởng đến khối lượng công việc giao dịch.
Lỗ hổng của kiến trúc này nằm ở chỗ nó không đáp ứng được yêu cầu tách biệt giữa xử lý phân tích và giao dịch. Các truy vấn phân tích được đồng ý với dữ liệu hoạt động sau khi phần mềm trung gian giải thích chúng. Theo cách này, các truy vấn ảnh hưởng đến khối lượng công việc giao dịch.
Two-Tier Architecture
Yêu cầu phân tách đóng một vai trò thiết yếu trong việc xác định kiến trúc hai tầng cho hệ thống kho dữ liệu, như thể hiện trong hình:
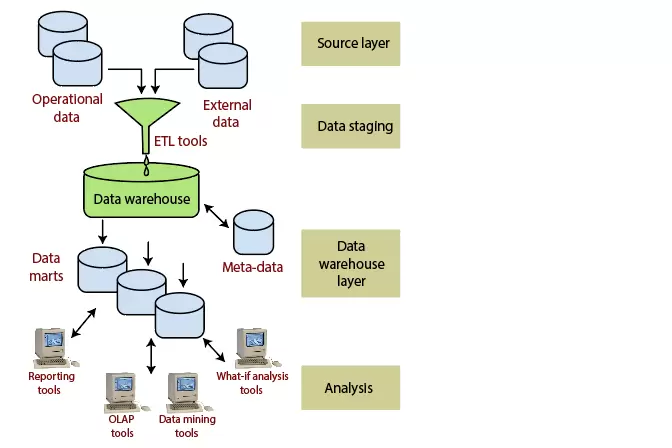 Mặc dù nó thường được gọi là kiến trúc hai lớp để làm nổi bật sự tách biệt giữa các nguồn có sẵn vật lý và kho dữ liệu, trên thực tế, bao gồm bốn giai đoạn luồng dữ liệu tiếp theo:
Mặc dù nó thường được gọi là kiến trúc hai lớp để làm nổi bật sự tách biệt giữa các nguồn có sẵn vật lý và kho dữ liệu, trên thực tế, bao gồm bốn giai đoạn luồng dữ liệu tiếp theo:
Lớp nguồn: Một hệ thống kho dữ liệu sử dụng một nguồn dữ liệu không đồng nhất. Dữ liệu đó ban đầu được lưu trữ vào cơ sở dữ liệu quan hệ của công ty hoặc cơ sở dữ liệu kế thừa, hoặc nó có thể đến từ một hệ thống thông tin bên ngoài các bức tường của công ty.
Giai đoạn dữ liệu: Dữ liệu được lưu trữ vào nguồn phải được trích xuất, làm sạch để loại bỏ sự mâu thuẫn và lấp đầy khoảng trống, đồng thời tích hợp để hợp nhất các nguồn không đồng nhất thành một lược đồ tiêu chuẩn. Công cụ trích xuất, chuyển đổi và tải (ETL) có tên như vậy có thể kết hợp các schemata không đồng nhất, trích xuất, chuyển đổi, làm sạch, xác thực, lọc và tải dữ liệu nguồn vào kho dữ liệu.
Lớp Kho dữ liệu: Thông tin được lưu vào một kho lưu trữ riêng lẻ tập trung hợp lý: kho dữ liệu. Các kho dữ liệu có thể được truy cập trực tiếp, nhưng nó cũng có thể được sử dụng như một nguồn để tạo các data mart, một phần sao chép nội dung kho dữ liệu và được thiết kế cho các bộ phận doanh nghiệp cụ thể. Kho lưu trữ siêu dữ liệu lưu trữ thông tin về nguồn, thủ tục truy cập, tổ chức dữ liệu, người dùng, lược đồ trung tâm dữ liệu, v.v.
Phân tích: Trong lớp này, dữ liệu tích hợp được truy cập hiệu quả và linh hoạt để đưa ra báo cáo, phân tích động thông tin và mô phỏng các tình huống kinh doanh giả định. Nó phải có tính năng điều hướng thông tin tổng hợp, trình tối ưu hóa truy vấn phức tạp và GUI thân thiện với khách hàng.
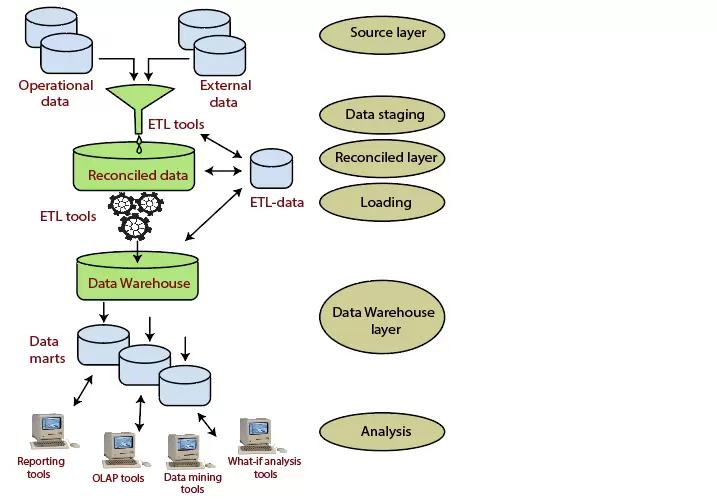
Three-Tier Architecture
Kiến trúc ba tầng bao gồm lớp nguồn (chứa nhiều hệ thống nguồn), lớp đối chiếu và lớp kho dữ liệu (chứa cả kho dữ liệu và ổ chứa dữ liệu). Lớp đối chiếu nằm giữa dữ liệu nguồn và kho dữ liệu.
Ưu điểm chính của lớp đối chiếu là nó tạo ra một mô hình dữ liệu tham chiếu tiêu chuẩn cho toàn bộ doanh nghiệp. Đồng thời, nó tách biệt các vấn đề khai thác và tích hợp dữ liệu nguồn với các vấn đề của tổng thể kho dữ liệu. Trong một số trường hợp, lớp đối chiếu cũng được sử dụng trực tiếp để hoàn thành tốt hơn một số nhiệm vụ hoạt động, chẳng hạn như tạo báo cáo hàng ngày mà không thể chuẩn bị thỏa đáng bằng cách sử dụng các ứng dụng của công ty hoặc tạo luồng dữ liệu để cung cấp các quy trình bên ngoài theo định kỳ để hưởng lợi từ việc làm sạch và tích hợp.
Kiến trúc này đặc biệt hữu ích cho các hệ thống mở rộng, toàn doanh nghiệp. Một nhược điểm của cấu trúc này là không gian lưu trữ tệp bổ sung được sử dụng thông qua lớp điều hòa dư thừa. Nó cũng làm cho các công cụ phân tích xa hơn một chút so với thời gian thực.
Cảm ơn mọi người đã dành thời gian để đọc bài viết. Hẹn gặp mọi người trong những bài viết tiếp theo!
Để tìm hiểu cũng như muốn tham gia vào mảng dữ liệu, bạn có thể tham khảo thông tin các KHÓA HỌC “PHÂN TÍCH DỮ LIỆU KINH DOANH” – ONLINE/OFFLINE tại https://indaacademy.vn/
Học viện đào tạo INDA là đơn vị dẫn đầu mảng Đào tạo kĩ năng Phân tích dữ liệu kinh doanh tại Việt Nam. Các khóa học Phân tích dữ liệu kinh doanh tại INDA sẽ được khai giảng định kỳ hàng tháng, mỗi lớp học thu hút +100 anh/chị học viên – là trung tâm đào tạo Phân tích dữ liệu kinh doanh duy nhất tại Việt Nam thu hút được đông đảo học viên mỗi lớp như vậy, đã mở 34 khóa học Public trên thị trường và là đối tác đào tạo phân tích dữ liệu cho các doanh nghiệp lớn tại Việt Nam.
All rights reserved
