Phân biệt: Database, Data Warehouse, Data Mart, Data Lake, Data Lakehouse, Data Fabric, Data Mesh
Bài đăng này đã không được cập nhật trong 3 năm
Chào mọi người,
Hôm nay, tiếp tục Series Phân tích dữ liệu kinh doanh, mình sẽ chia sẻ với mọi người những khái niệm phổ biến nhất liên quan về thiết kế hệ thống dữ liệu bên dưới nhé, vì khi làm phân tích dữ liệu thì chúng ta cũng sẽ cần biết đến nó. Mình thì không chuyên về mấy Database Connections ở dưới, mình chủ yếu mạnh về phân tích thôi. Bên mình có hợp tác 1 anh Expert về Database Management & Architect (Joseph Tan), bên mình đang hoàn thiện giáo trình chương trình “Enterprise Data Warehouse”. Hi vọng sẽ “launching” chương trình mới này sớm.
*Data repositories (including databases, data warehouses, data lakes, data marts, and data lakehouses…): tất cả khái niệm này gọi chung là data repositories nhé mọi người (source), riêng từ này mình không biết dịch ra tiếng Việt như thế nào mới sát nghĩa nữa.
1. Database (cơ sở dữ liệu)
Cơ sở dữ liệu là nơi lưu trữ các dữ liệu liên quan được sử dụng để nắm bắt một tình huống cụ thể. Một ví dụ về cơ sở dữ liệu là cơ sở dữ liệu điểm bán hàng (POS). Cơ sở dữ liệu POS sẽ thu thập và lưu trữ tất cả dữ liệu có liên quan xung quanh các giao dịch của cửa hàng bán lẻ.
Cơ sở dữ liệu có nhiều loại:
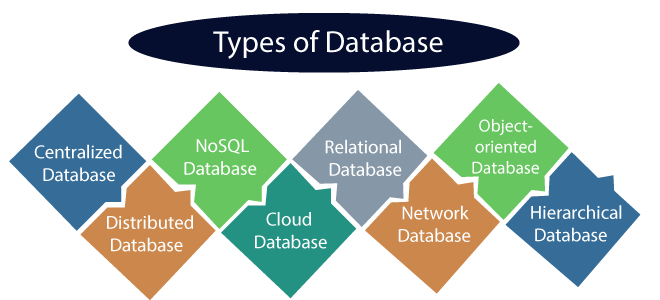
Dữ liệu mới đi vào cơ sở dữ liệu được xử lý, sắp xếp, quản lý, cập nhật và sau đó được lưu trữ trong các bảng. Cơ sở dữ liệu là kho lưu trữ dành cho mục đích duy nhất của dữ liệu giao dịch thô (raw transactional data). Bởi vì cơ sở dữ liệu được gắn chặt với các giao dịch, cơ sở dữ liệu thực hiện xử lý giao dịch trực tuyến (OLTP – online transactional processing).
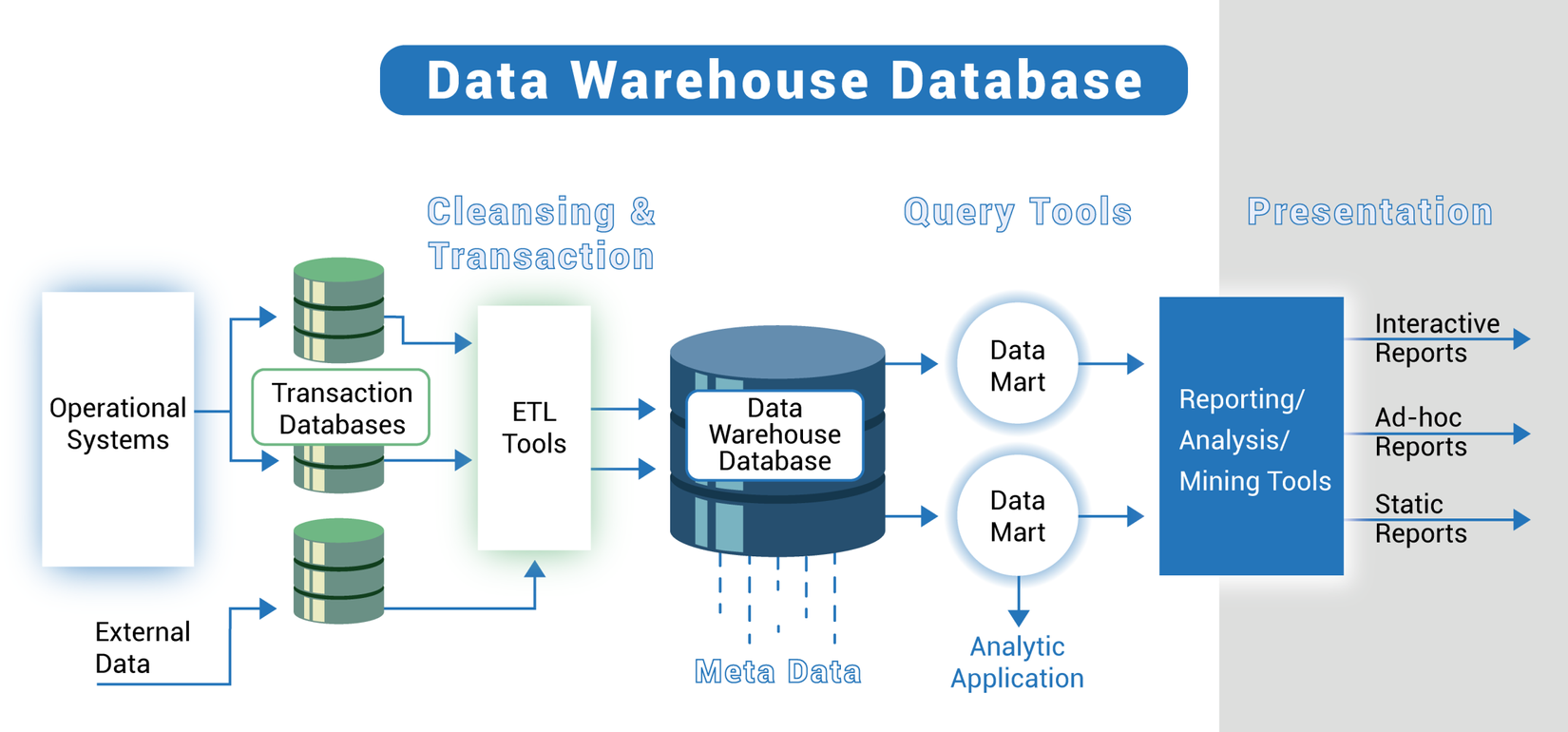
2. Data Warehouse (kho dữ liệu)
Nhìn vào hình trên, tiếp theo Databases: dữ liệu sẽ được đẩy vào ETL Tools để đẩy qua Data warehouse. Kho dữ liệu thường chỉ lưu trữ dữ liệu đã được lập mô hình / cấu trúc (thường lưu trữ dữ liệu có cấu trúc – structured data).
So sánh Database vs Data Warehouse:

3. Data Mart (phiên bản đơn giản của Data Warehouse)
Trong khi kho dữ liệu (Data warehouse) là nơi lưu trữ đa mục đích cho các trường hợp sử dụng khác nhau, thì kho dữ liệu (mart) là một phần phụ của kho dữ liệu, được thiết kế và xây dựng đặc biệt cho một bộ phận / chức năng kinh doanh cụ thể.
Một số lợi ích của việc sử dụng data-mart:
- Bảo mật được tách biệt: Vì data-mart chỉ chứa dữ liệu cụ thể cho bộ phận đó, bạn được đảm bảo rằng không thể truy cập dữ liệu ngoài ý muốn (dữ liệu tài chính, dữ liệu doanh thu).
- Hiệu suất được tách biệt: Tương tự như vậy, vì mỗi data-mart chỉ được sử dụng cho một bộ phận cụ thể, tải hiệu suất được quản lý và truyền đạt tốt trong bộ phận, do đó không ảnh hưởng đến các khối lượng công việc phân tích khác. 3 Loại Data Mart:
-
Kho dữ liệu phụ thuộc (Dependent Data Marts) – Kho dữ liệu phụ thuộc được xây dựng từ kho dữ liệu hiện có. Nó có cách tiếp cận từ trên xuống bắt đầu bằng việc lưu trữ tất cả dữ liệu kinh doanh của bạn ở một vị trí tập trung, sau đó rút một phần dữ liệu xác định khi cần để phân tích.
-
Kho dữ liệu độc lập (Independent Data Marts) – Kho dữ liệu độc lập là một hệ thống độc lập, được tạo ra mà không cần sử dụng kho dữ liệu và tập trung vào một chức năng nghiệp vụ. Dữ liệu được giải phóng từ các nguồn dữ liệu bên trong hoặc bên ngoài, được tinh chỉnh, sau đó được tải vào data mart, nơi nó được lưu cho đến khi cần thiết hoặc phân tích nghiệp vụ.
-
Kết hợp dữ liệu Mart (Hybrid Data Marts) – Một kho dữ liệu kết hợp tích hợp dữ liệu từ kho dữ liệu hiện tại và các hệ thống nguồn hoạt động bổ sung. Nó kết hợp tốc độ và sự tập trung vào người dùng cuối của phương pháp tiếp cận từ trên xuống với sự hỗ trợ của việc tích hợp cấp độ doanh nghiệp của phương pháp từ dưới lên.
4. Data Lake (hồ dữ liệu)
Chọn Data Lake vì 2 lý do chính:
Bạn cần một cách rẻ để lưu trữ các loại dữ liệu khác nhau với số lượng lớn.
Bạn không có kế hoạch để làm gì với dữ liệu, nhưng bạn có ý định sử dụng nó vào một lúc nào đó. Do đó, bạn thu thập dữ liệu trước và phân tích sau.
So sánh Data Warehouse vs Data Lake
 So sánh Data Lake vs. Data Warehouse vs. Data Mart
So sánh Data Lake vs. Data Warehouse vs. Data Mart
 Nhìn vào hình trên:
Nhìn vào hình trên:
Data Lake phù hợp với những doanh nghiệp có nhu cầu phân tích Advance (sử dụng cả dữ liệu phi cấu trúc), do lượng dữ liệu lớn nên thời gian truy vấn, phân tích dữ liệu tính bằng tuần/ tháng, chi phí cao do lượng data cần lưu trữ rất lớn, và chỉ 1 nhóm đối tượng có khả năng phân tích nâng cao sử dụng Data Warehouse là kho dữ liệu tổng thể tập hợp các hệ thống dữ liệu có cấu trúc tại các phòng ban, rất phổ biến tại hầu hết doanh nghiệp, các doanh nghiệp đã có các hệ thống dữ liệu ở nhiều phòng ban, giờ tập hợp tại 1 nơi, đa phần nhiều “Business Users” có thể sử dụng dữ liệu này, đây là kho dữ liệu tổng của doanh nghiệp Data Mart là kho dữ liệu riêng lẻ được thiết kế riêng cho từng phòng ban.
5. Data Lakehouse
A Data Lakehouse combines the advantages of a Data Lake and a Data Warehouse.
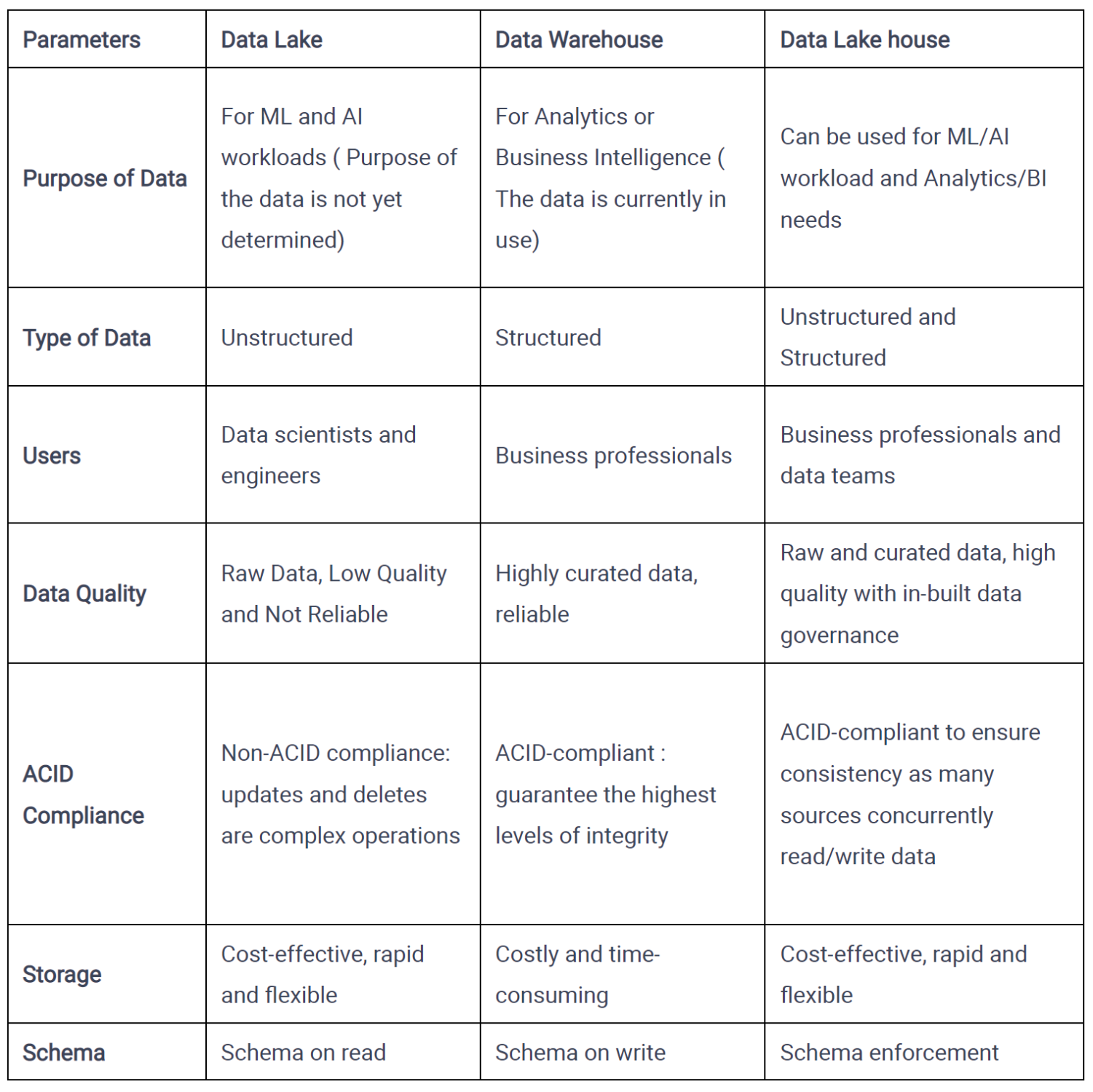
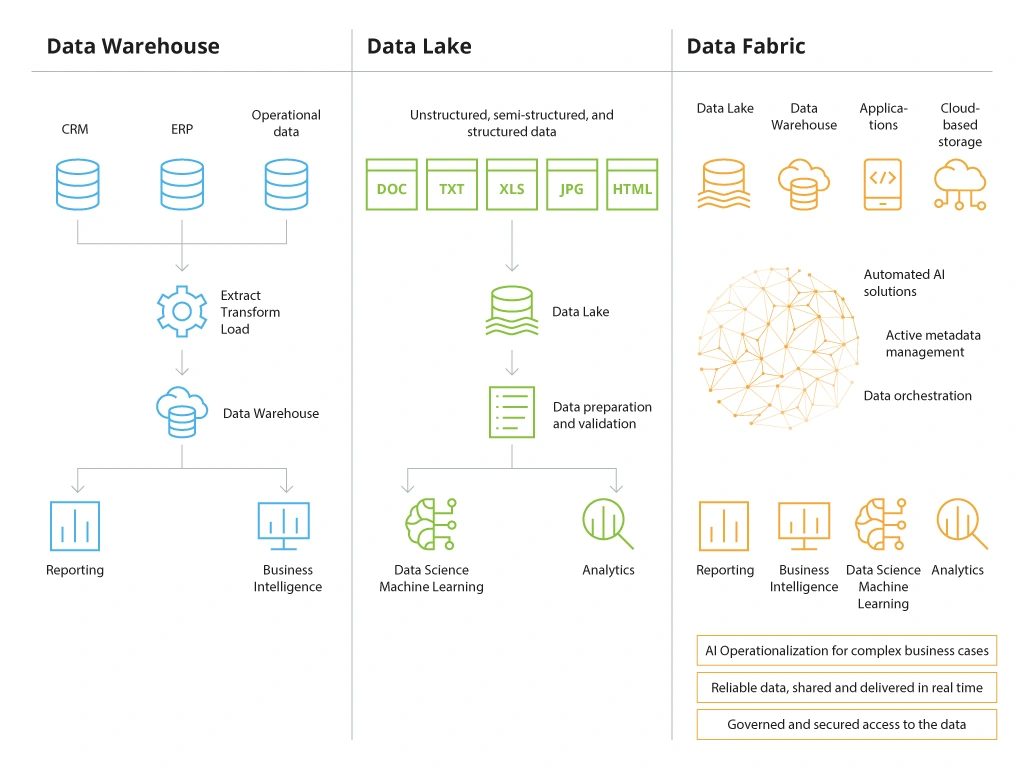
6. Data Fabric?
Data Fabric được thiết kế để giúp các tổ chức giải quyết các vấn đề phức tạp về dữ liệu. Các trường hợp sử dụng bằng cách quản lý dữ liệu của họ bất kể loại ứng dụng, nền tảng và nơi dữ liệu được lưu trữ. Nó cho phép truy cập liền mạch và chia sẻ dữ liệu trong môi trường dữ liệu phân tán. Nó tương tự như Data Lakehouse, kết hợp Data Warehouse và Data Lake, nhưng tiến thêm một bước nữa và cũng tích hợp dữ liệu từ các ứng dụng với nhau. Data Fabrics tiến thêm một bước nữa và cung cấp cho bạn các dịch vụ hỗ trợ kiểm soát, giám sát, v.v. cho bạn và công ty.
7. Data Mesh (lưới dữ liệu)
Mặc dù lưới dữ liệu (Data Mesh) nhằm mục đích giải quyết nhiều vấn đề tương tự như kết cấu dữ liệu (Data Fabric) – cụ thể là: khó khăn trong việc quản lý dữ liệu trong môi trường dữ liệu không đồng nhất – nó giải quyết vấn đề theo một cách cơ bản khác. Nói tóm lại, trong khi kết cấu dữ liệu (data fabric) tìm cách xây dựng một lớp quản lý ảo duy nhất trên dữ liệu phân tán, thì lưới dữ liệu (data mesh) khuyến khích các nhóm phân tán quản lý dữ liệu khi họ thấy phù hợp, mặc dù với một số quy định quản trị chung.
Next Data Platform là Data Mesh?
Data Mesh là “ngôi sao mới nổi” khi nhắc về kiểu lưu trữ dữ liệu hiện nay. Trước khi tìm hiểu Data Mesh là gì, chúng ta cùng đi qua 2 khái niệm quan trọng: Monolithic Vs. Microservices Architecture
 Source: Muhammad M. Atout
Source: Muhammad M. Atout
Monolithic architecture
Trong kiến trúc phần mềm (software engineering), kiến trúc nguyên khối (monolithic architecture) được coi là mô hình truyền thống, đó là xây dựng ứng dụng như một khối thống nhất khép kín và độc lập với các ứng dụng khác.
Kiến trúc này sẽ rất thuận tiện cho các giai đoạn đầu trong vòng đời của bất kỳ dự án nào để dễ dàng phát triển và triển khai mã. Nói cách khác, cách tiếp cận nguyên khối cho phép mọi thứ được giải phóng cùng một lúc, và như với mọi thứ trong cuộc sống này, cách tiếp cận này có các dòng chảy của nó bao gồm:
- Tốc độ phát triển chậm hơn (Slower development speed) – Một ứng dụng lớn, nguyên khối làm cho việc phát triển phức tạp hơn và chậm hơn.
- Áp dụng công nghệ mới (New technology adoption) – Bất kỳ thay đổi hoặc nâng cấp nào trong công nghệ được sử dụng đều ảnh hưởng đến toàn bộ ứng dụng, khiến quyết định này trở nên tốn kém và khó khăn.
- Phát triển và triển khai Khả năng mở rộng (Development and deployment Scalability) – Khi hệ thống phát triển để nâng cấp một thành phần duy nhất sẽ rất khó khăn và bất kỳ thay đổi nhỏ nào đối với một ứng dụng nguyên khối cũng yêu cầu triển khai lại toàn bộ nguyên khối.
Microservices architecture
Mặt khác, phương pháp Microservices là một phương pháp kiến trúc dựa trên một loạt các dịch vụ có thể triển khai độc lập. Các dịch vụ này có cơ sở dữ liệu và logic nghiệp vụ riêng với một mục tiêu cụ thể. Cập nhật, thử nghiệm, triển khai và mở rộng diễn ra trong mỗi dịch vụ. Điều này giúp loại bỏ nhược điểm của cách tiếp cận nguyên khối, nhưng “như mọi khi” lại tạo ra nhược điểm mới. Ví dụ:
- Thêm độ phức tạp khi phát triển (Added development complexity) – Microservices thêm phức tạp hơn so với kiến trúc nguyên khối vì có nhiều dịch vụ hơn ở nhiều nơi do nhiều nhóm tạo ra. Nếu quá trình phát triển không được quản lý đúng cách, sẽ dẫn đến tốc độ phát triển chậm hơn và hiệu suất hoạt động kém.
- Chi phí cơ sở hạ tầng cao (High infrastructure costs) – Mỗi dịch vụ vi mô mới có thể có chi phí riêng cho bộ thử nghiệm, sách phát triển khai, cơ sở hạ tầng lưu trữ, công cụ giám sát,…
- Các thách thức về gỡ lỗi (Debugging challenges) – Mỗi microservice đều có một bộ nhật ký riêng, điều này làm cho việc gỡ lỗi trở nên phức tạp hơn.
- Thiếu quyền sở hữu rõ ràng (Lack of clear ownership) – Khi có nhiều dịch vụ hơn được giới thiệu, số lượng nhóm điều hành các dịch vụ đó cũng vậy. Theo thời gian, rất khó để biết các dịch vụ sẵn có mà nhóm có thể tận dụng và liên hệ với ai để được hỗ trợ.
Data Mesh là gì?
Data mesh is the data platform version of microservices (lưới dữ liệu là phiên bản nền tảng dữ liệu của microservices.)
Theo Zhamak Dehghani – consultant in ThoughtWorks, người đưa ra định nghĩa này đầu tiên: “Data Mesh (lưới dữ liệu) là một loại kiến trúc nền tảng dữ liệu bao gồm tính phổ biến của dữ liệu trong doanh nghiệp (embraces the ubiquity of data in the enterprise) bằng cách tận dụng thiết kế tự phục vụ (self-serve design), theo định hướng theo mảng (leveraging a domain-oriented). Vay mượn lý thuyết của Eric Evans về thiết kế theo hướng mảng (theory of domain-driven design), một mô hình phát triển phần mềm linh hoạt, có thể mở rộng phù hợp với cấu trúc và ngôn ngữ mã của bạn với miền kinh doanh tương ứng của nó ”.
Nói một cách đơn giản hơn, Không giống như cơ sở hạ tầng dữ liệu nguyên khối truyền thống xử lý việc nhập, lưu trữ, chuyển đổi và xuất dữ liệu trong một hồ dữ liệu trung tâm, lưới dữ liệu hỗ trợ người tiêu dùng dữ liệu phân tán, theo mảng cụ thể và chế độ xem “data-as-a-product”, với mỗi miền xử lý các đường ống dẫn dữ liệu của riêng mình. Mô kết nối các miền này và các tài sản dữ liệu liên quan của chúng là một lớp khả năng tương tác chung áp dụng cùng một cú pháp và các tiêu chuẩn dữ liệu.
Nhiều công ty cho đến nay đã tận dụng một kho dữ liệu duy nhất (single data warehouse) được kết nối với nhiều nền tảng kinh doanh thông minh (business intelligence platforms). Các giải pháp như vậy thường gây ra nợ kỹ thuật (Technical debt) đáng kể trong việc duy trì đường ống trung tâm bởi một nhóm nhỏ các kỹ sư dữ liệu, điều này tạo ra tắc nghẽn trong nền tảng dữ liệu của tổ chức.
*Technical debt là nợ kỹ thuật. Hiểu đơn giản thì technical debt là khối lượng công việc cần phải được giải quyết trong một dự án về công nghệ thông tin.
Đối với nhiều tổ chức, kiến trúc nguyên khối dữ liệu (data monolithic architecture) có nhiều luồng (flows), bao gồm:
- Đường ống ETL trung tâm cung cấp cho các nhóm kỹ thuật dữ liệu ít quyền kiểm soát hơn đối với việc tăng khối lượng dữ liệu.
- Các trường hợp sử dụng dữ liệu khác nhau yêu cầu các kiểu biến đổi khác nhau, đặt nặng lên nền tảng trung tâm.
Các hồ dữ liệu tập trung như vậy dẫn đến việc các nhà sản xuất dữ liệu bị ngắt kết nối, những người tiêu dùng dữ liệu thiếu kiên nhẫn và tệ hơn là, một nhóm kỹ thuật dữ liệu tồn đọng đang phải vật lộn để bắt kịp với nhu cầu của doanh nghiệp.
Instead, domain-oriented data architectures, like data meshes, give teams the best of both worlds: a centralized database (or a distributed data lake) with domains (or business areas) responsible for handling their own pipelines. As Zhamak argues, data architectures can be most easily scaled by being broken down into smaller, domain-oriented components.
Thay vào đó, các kiến trúc dữ liệu hướng mảng (domain-oriented data architectures), như lưới dữ liệu (data mesh), cung cấp cho các nhóm điều tốt nhất của cả hai thế giới: cơ sở dữ liệu tập trung – a centralized database (hoặc hồ dữ liệu phân tán – distributed data lake) với các mảng kinh doanh (hoặc khu vực kinh doanh) – domains (or business areas) chịu trách nhiệm xử lý các đường ống dẫn của riêng họ. Như Zhamak lập luận, các kiến trúc dữ liệu (data architectures) có thể dễ dàng mở rộng quy mô nhất bằng cách được chia nhỏ thành các thành phần hướng mảng kinh doanh.
Nói một cách đơn giản hơn, các yêu cầu về cơ sở hạ tầng dữ liệu của công ty bạn càng phức tạp và khắt khe, thì tổ chức của bạn càng có nhiều khả năng được hưởng lợi từ lưới dữ liệu.
Ví dụ Data mesh ở mức “high-level”:
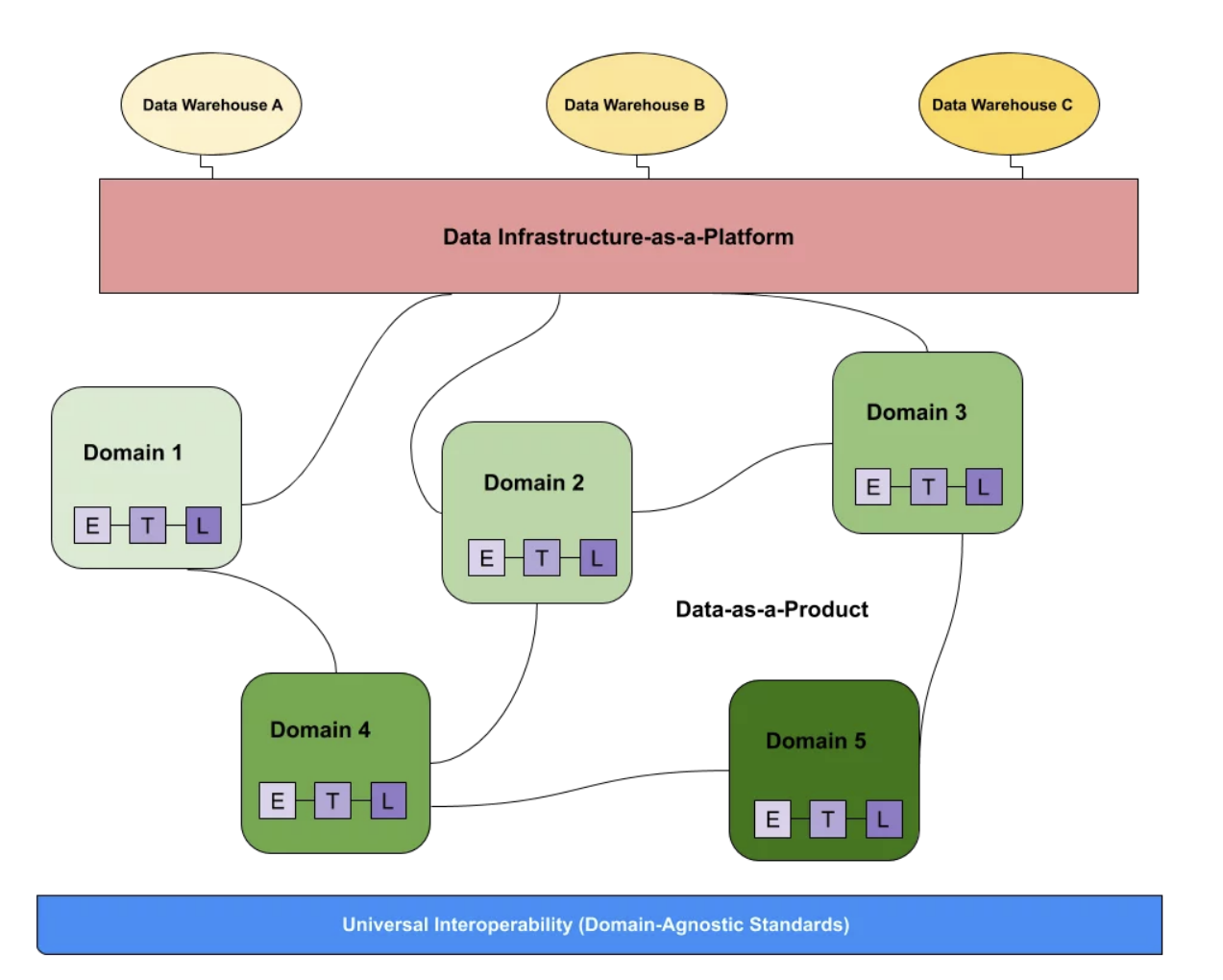 A data mesh architecture diagram is composed of three separate components: data sources, data infrastructure, and domain-oriented data pipelines managed by functional owners.
A data mesh architecture diagram is composed of three separate components: data sources, data infrastructure, and domain-oriented data pipelines managed by functional owners.
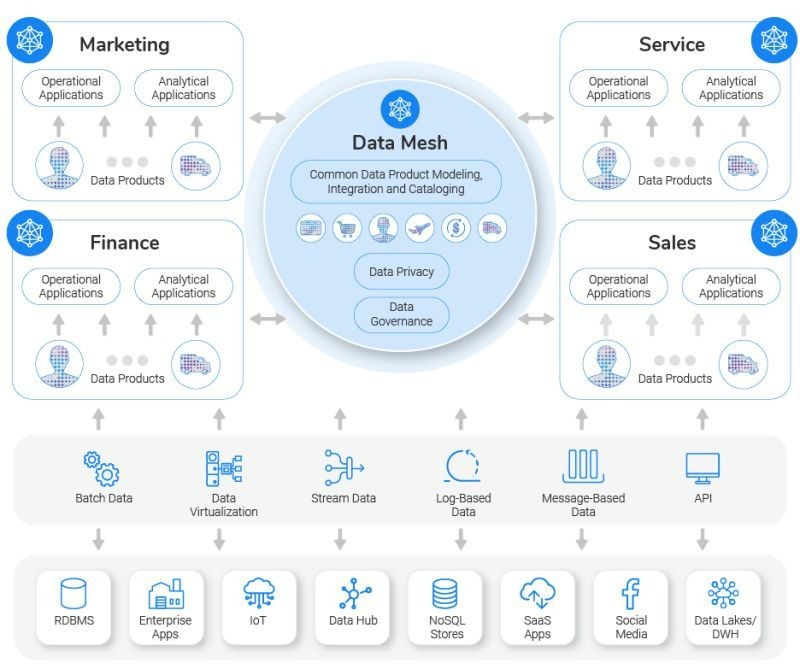
Source: Internet
Phân biệt Data Lakehouse vs Data Mesh: “Data Mesh is a paradigm – Lakehouse is a platform”, phân biệt chi tiết hơn, mọi người xem tại video này nhé!https://www.linkedin.com/embeds/publishingEmbed.html?articleId=7073142464567856814&li_theme=light Do đây là những khái niệm lý thuyết, nên mình tham khảo định nghĩa học thuật của nó, mình đã để link tham khảo tại từng khái niệm, ở đây mình sẽ tổng hợp lại cho 1 số anh/chị muốn đọc tham khảo thêm nhé:
https://www.zuar.com/blog/data-mart-vs-data-warehouse-vs-database-vs-data-lake/ https://www.holistics.io/blog/data-lake-vs-data-warehouse-vs-data-mart/ https://medium.com/@mhatout/data-mesh-as-i-know-it-d30d9fc1ea69 https://www.javatpoint.com/types-of-databases https://www.atlassian.com/microservices/microservices-architecture/microservices-vs-monolith https://www.montecarlodata.com/blog-what-is-a-data-mesh-and-how-not-to-mesh-it-up/ https://martinfowler.com/articles/data-monolith-to-mesh.html https://www.databricks.com/session_na20/data-mesh-in-practice-how-europes-leading-online-platform-for-fashion-goes-beyond-the-data-lake —-
Cảm ơn mọi người đã dành thời gian để đọc bài viết. Hẹn gặp mọi người trong những bài viết tiếp theo! Tham khảo thông tin KHÓA HỌC “PHÂN TÍCH DỮ LIỆU KINH DOANH” – ONLINE/OFFLINE tại https://indaacademy.vn/
Học viện đào tạo INDA là đơn vị dẫn đầu mảng Đào tạo kĩ năng Phân tích dữ liệu kinh doanh tại Việt Nam. Các khóa học Phân tích dữ liệu kinh doanh tại INDA sẽ được khai giảng định kỳ hàng tháng, mỗi lớp học thu hút +100 anh/chị học viên – là trung tâm đào tạo Phân tích dữ liệu kinh doanh duy nhất tại Việt Nam thu hút được đông đảo học viên mỗi lớp như vậy, đã mở 34 khóa học Public trên thị trường và là đối tác đào tạo phân tích dữ liệu cho các doanh nghiệp lớn tại Việt Nam.
#dataanalyst #DataAnalytics #Data #dulieu #Analytics
All rights reserved
