Hadoop, Spark Multinode Cluster in DataProc
Bài đăng này đã không được cập nhật trong 4 năm
Google offers a managed Spark and Hadoop service. They call it Google Cloud Data Proc. It is almost same as Amazon's EMR. You can use Data Proc service to create a Hadoop and Spark cluster in less than two minutes.
- Setup your Google cloud account and a default project.
- Start your Google Cloud Console.
- Go to products and services menu.
- Scroll down to Data Proc and select clusters.
- Hit the create cluster button.
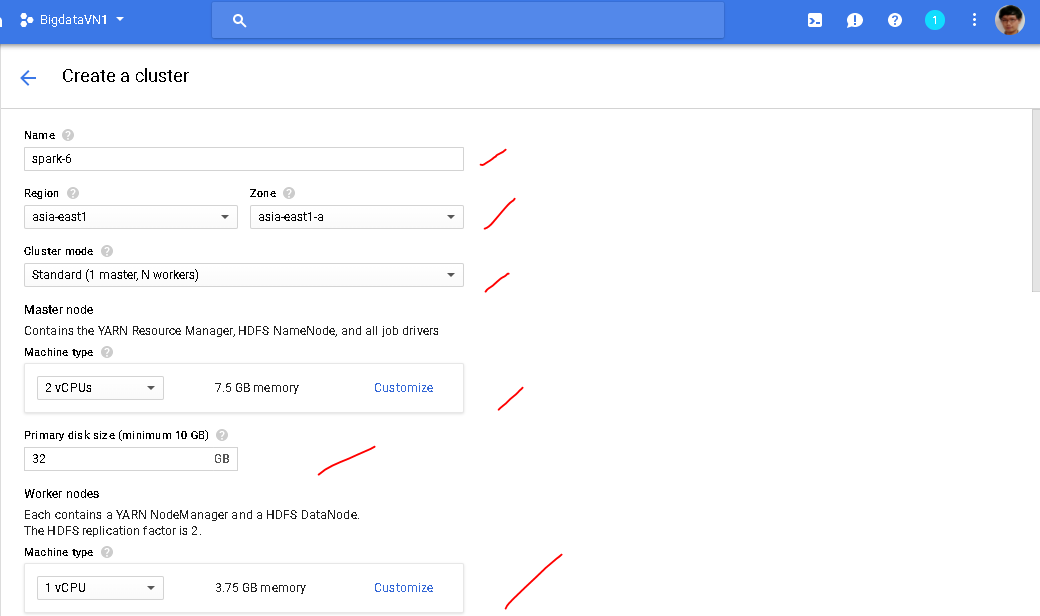
- Give a name to your Cluster and choose your region.
- Choose a machine type for your master node.
- Select a cluster type.
- Select the disk size for the master node.
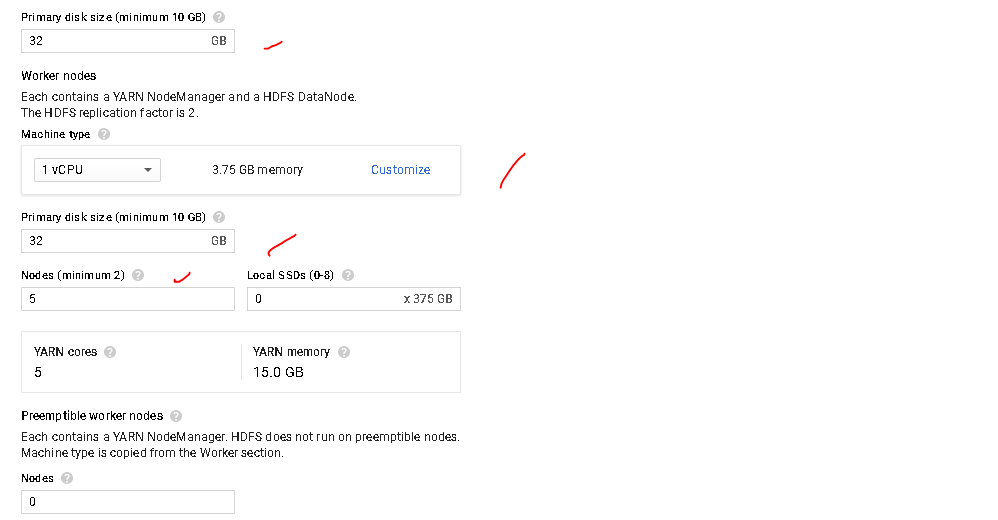
- Choose the data node configuration and the number of workers.
- Select the disk size for each worker.
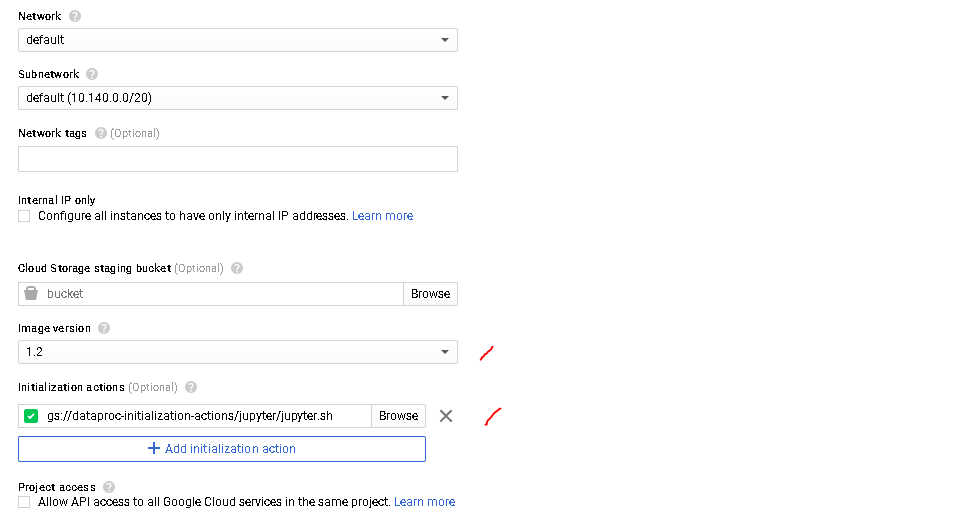
- Select an initialization action (Optional)
- Hit the create button.
Get initialization actions:

Wait a minute or two, and the Data Proc API will provision your cluster. You don't need a download, no installation, and nothing. Your Spark cluster should be ready in just a few clicks.
How to access Spark Cluster in Cloud?
-
Download and install cloud sdk: https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe?hl=vi
-
Run the following command prompt:
gcloud compute ssh --zone=asia-east1-a --ssh-flag="-D" --ssh-flag="10000" --ssh-flag="-N" "spark-6-m"
After Putty will automatic run, authenticate user:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" "http://spark-6-m:8088"
--proxy-server="socks5://localhost:10000" --host-resolver-rules="MAP * 0.0.0.0, EXCLUDE localhost"
--user-data-dir=c:\test\spark-6-m
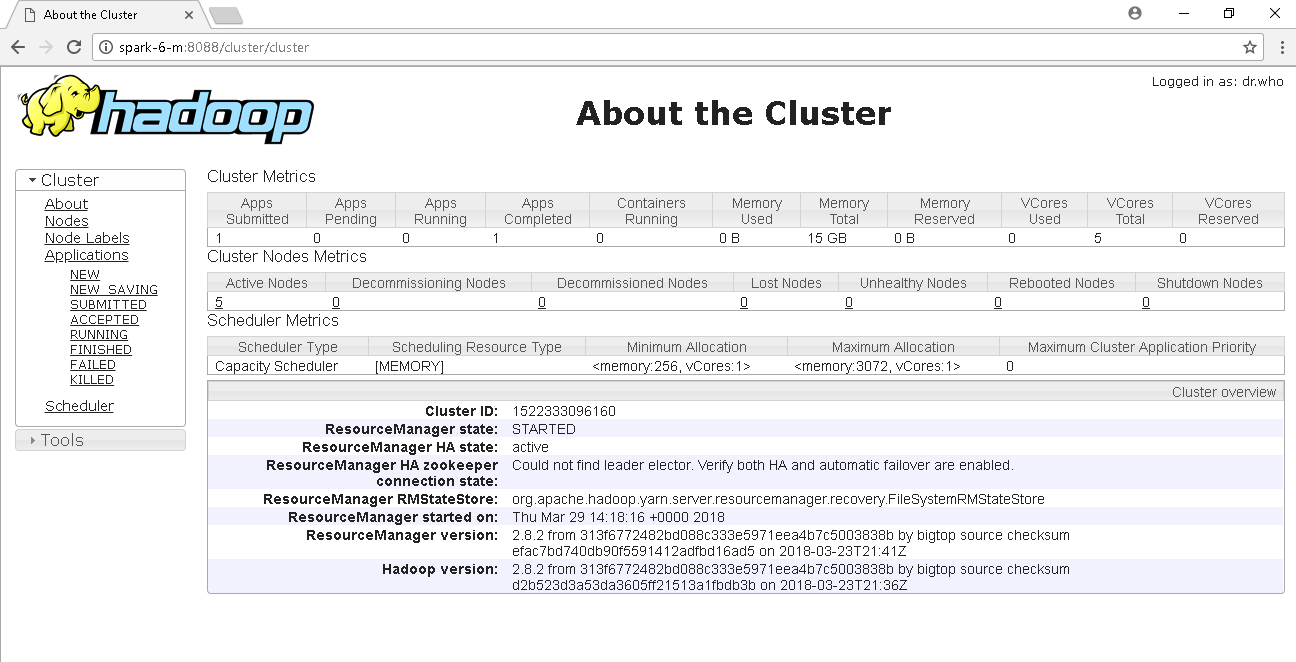
I am starting chrome.exe with my YARN Resource Manager URL. Next one is the proxy server. It should use the socks5 protocol on my local machine's port 10000. That's the port where we started the SSH tunnel. Right? The next flag is to avoid any DNS resolves by chrome. Finally, the last option is a non-existent directory path. This option allows chrome to start a brand-new session. That's it. You can access the resource manager in the new browser. This video demonstrated to get you a Spark cluster. You can access that over the web and SSH. Execute your Jobs, play with it and later go back to your Data Proc clusters list and delete it. We don't have an option to keep it there in shutdown state. Creating and removing a cluster is as simple as few clicks. You can create a new one every day, use it and then throw it away.
References more: Spark SQL, DataFrames and Datasets Guide
All rights reserved
