Cách tiếp cận trong bài toán khai phá và phân tích dữ liệu trong Machine Learning
Bài đăng này đã không được cập nhật trong 8 năm
Mở đầu
Khi làm bài giảng về ML trong bài toán hồi qui tuyến tính thì tiện thể viết luôn 1 số ý kiến để các bạn mới tiếp cận có thể tham khảo cho dễ hiểu. Thời gian trước khi vào ĐN làm một buổi training thì cũng đã hướng dẫn cho các bạn ĐN biết cách phân tích dữ liệu và xử lý trong bài toán hồi qui tuyến tính rồi. Tuy nhiên, mình lại chưa nói rõ cách quan sát dữ liệu khi có một tập dữ liệu được cho để xây dựng mô hình và tìm cách để tối ưu hoá tập dữ liệu cần thiết để đưa vào training trong học máy. Cái này tương đối quan trọng các bạn nhé! Bởi rõ ràng, tập dữ liệu nó ảnh hưởng trực tiếp đến việc sử dụng thuật toán nào trong xây dựng mô hình của máy học và sẽ sử dụng mô hình đó để phán đoán các kết quả trong tương lai. Bởi vậy, khi có tập dữ liệu thì việc đầu tiên ta phải xem xem là các thuộc tính của nó ảnh hưởng thế nào đến nhãn (mục tiêu) của bộ dữ liệu này, hay nó có đặc biệt gì hay không. Do đó, trong bài toán về học máy thì các bước như thu thập dữ liệu, đánh giá dữ liệu, xây dựng mô hình, kiểm thử mô hình, tối ưu hoá thuật toán là các bước vô cùng quan trọng. Đến đây thì ta mượn tạm dữ liệu của bạn Phạm Văn Toàn để đi đánh giá thử xem thế nào nhé! Trước hết, ta đọc dữ liệu của bạn ấy cung cấp trên Viblo để đọc dữ liệu bình thường như sau:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
file_path='data/home_data.txt'
data=pd.read_csv(file_path, delimiter=',',header ='infer',skipinitialspace=True)
Hiển thị thử 20 dữ liệu ban đầu, ta sẽ có được bảng bên dưới:
data.head(20)
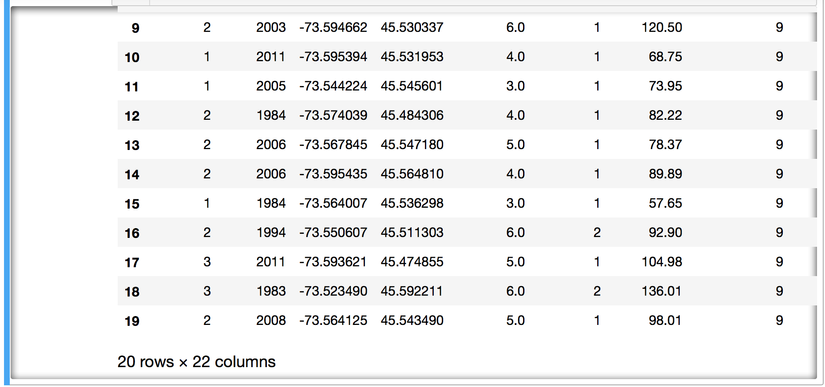
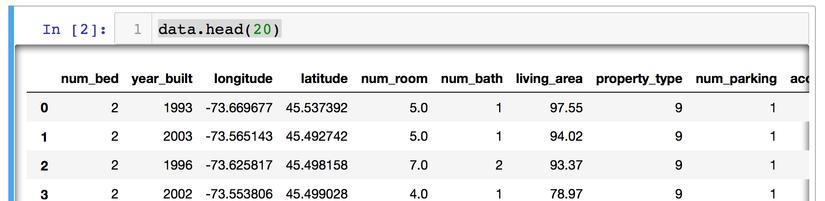
Ta có khoảng 22 thuộc tính cho mỗi một trường dữ liệu, phản ánh cho đặc trưng của một căn hộ. Vậy ta phải đánh giá thế nào để biết được thuộc tính nào sẽ ảnh hưởng đến giá của một căn hộ được? Tất nhiên, ta có thể phán đoán luôn là diện tích, số phòng, vị trí, .... Tuy nhiên, đây là một dữ liệu quá dễ phán đoán và ta gặp phải nhiều trong thực tế. Còn đối với 1 số dữ liệu khác mà ta chưa hề tiếp cận thì thao tác đánh giá dữ liệu phải là việc làm đầu tiên để khảo sát đặc trưng của dữ liệu này.
Tiến hành khảo sát dữ liệu
Mục tiêu của bước này là để khảo sát, hiểu được dữ liệu mà nó phản ánh đến mục tiêu của nó như thế nào. Nắm được chắc chắn các ảnh hưởng của các thuộc tính thì ta sẽ có thể dùng trọng số để nâng cao tính ảnh hưởng hoặc có thể loại bỏ luôn những dữ liệu mà không có giá trị trong xây dựng mô hình. Vậy sẽ làm tăng được hiệu quả của thuật toán của chúng ta.
Vậy quay về bài toán phán đoán giá bất động sản này thì sao? Ta khảo sát thử một số thuộc tính ảnh hưởng đến giá nhà của căn hộ xem xu hướng nó thế nào. Trước hết thử số phòng ngủ của các căn hộ xem đa phần các căn hộ loại nào sẽ chiếm ưu thế.
data['num_bed'].value_counts().plot(kind='bar')
plt.title('number of bedroom')
plt.xlabel('Bedrooms')
plt.ylabel('Count')
sns.despine
plt.show()
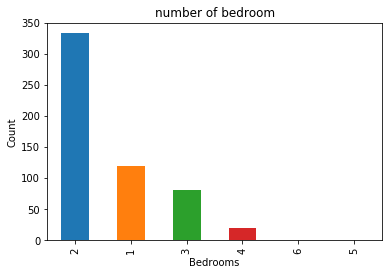
Từ đồ thị này ta thấy được số căn hộ có 2 phòng ngủ chiếm ưu thế nhiều nhất. Chứng tỏ nhu cầu mua căn hộ có hai phòng ngủ sẽ rất cao theo thị hiếu người dùng. Do đó, đối với các nhà BĐS thì họ sẽ có xu thế chạy theo nhu cầu của khách hàng để cân bằng cung cầu.
Tiếp đến, ta thử khảo sát xem vị trí của các căn hộ sẽ tập trung ở đâu là được chú ý nhiều hơn thì ta sẽ dùng code sau để khảo sát tập dữ liệu này:
plt.figure(figsize=(10,10))
sns.jointplot(x=data.latitude.values, y=data.longitude.values, size=10)
plt.ylabel('Longitude', fontsize=12)
plt.xlabel('Latitude', fontsize=12)
plt.show()
sns.despine
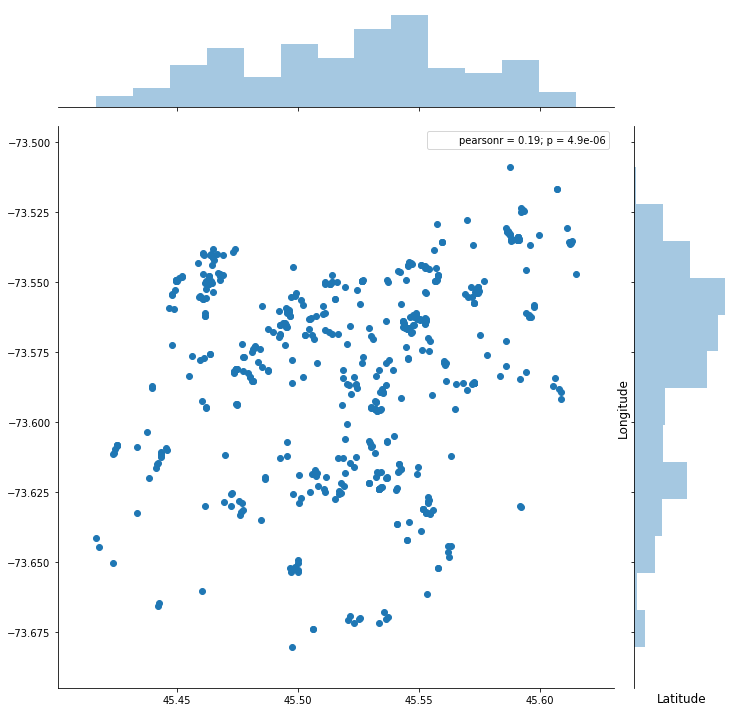
Rõ ràng tập dữ liệu này hơi nhỏ nên số lượng căn hộ phân bố chưa được rõ ràng lắm. Nhưng ta cũng thấy được số lượng căn hộ tập trung ở vùng Lat 45.50 ~ 45.55 và vùng Lon 73.55 ~ 73.60 là nhiều. Nó phản ánh được tỷ lệ chọn nhà trong vùng này lớn thí giá của các căn hộ ở đây sẽ cao thôi.
Ta khảo sát đến mối tương quan của thuộc tính là diện tích căn hộ ảnh hưởng đến giá như thế nào nhé!
plt.scatter(data.askprice,data.living_area)
plt.title("Price vs Living Area")
plt.ylabel('Living Area', fontsize=12)
plt.xlabel('Price', fontsize=12)
plt.show()
sns.despine
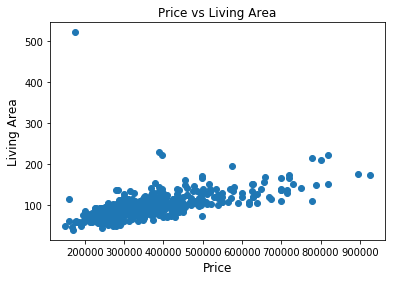
Rõ ràng ta thấy diện tích căn hộ và giá của nó đã tỷ lệ tuyến tính với nhau. Diện tích càng lớn thì giá càng cao nhỉ. Có 1 số dữ liệu hơi bất thường 1 chút ở đây thì khi training model thì chúng ta lưu ý để loại đối tượng này đi là được bởi nó sẽ tạo ra nhiễu ảnh hưởng đến độ chính xác của model nhé!
Đến đây, ta mới đang khảo sát 1 thuộc tính ảnh hưởng đến giá của căn hộ, vậy cách để khảo sát nhiều thuộc tính thì sao. Ta thử khảo sát xem số phòng ngủ và diện tích căn hộ thì ảnh hưởng như thế nào đến giá căn hộ.
plt.scatter((data['num_bed']+data['living_area']),data['askprice'])
plt.title("Bedroom and Living area vs Price ")
plt.xlabel("Bedroom and Living area")
plt.ylabel("Price")
plt.show()
sns.despine
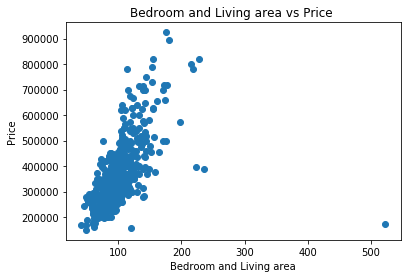
Như vậy, thuộc tính về số phòng ngủ và diện tích của căn hộ cũng có xu hướng tỷ lệ tuyến tính với giá căn hộ. Nhìn đồ thị là ta có thể khảo sát được rất rõ ràng đặc trưng của dữ liệu ảnh hưởng đến nhãn của dữ liệu. Nhãn ở bài toán này là giá của căn hộ mà có trong tập dữ liệu nhé! Đến đây, các bạn đã biết được cách khảo sát các thuộc tính trong dữ liệu rồi thì thử khảo sát nhiều thuộc tính khác xem nó ảnh hưởng đến giá như thế nào.
Xây dựng mô hình hồi qui tuyến tính
Bây giờ ta tiến hành xây dựng mô hình hồi qui tuyến tính để phán đoán giá căn hộ dựa trên tập dữ liệu được cung cấp như sau:
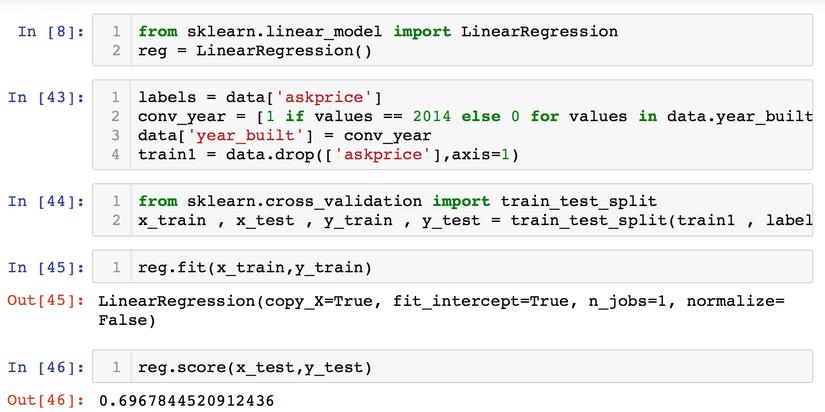
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
labels = data['askprice']
conv_year = [1 if values == 2014 else 0 for values in data.year_built ]
data['year_built'] = conv_year
train1 = data.drop(['askprice'],axis=1)
from sklearn.cross_validation import train_test_split
x_train , x_test , y_train , y_test = train_test_split(train1 , labels , test_size = 0.10,random_state = 2018)
reg.fit(x_train,y_train)
reg.score(x_test,y_test)
Với việc sử dụng thuật toán hồi qui tuyến tính, độ chính xác trong tập dữ liệu này đạt được là 69.67%. Chú ý là sau khi khảo sát xong độ ảnh hưởng của thuộc tính dữ liệu thì bài viết chưa loại trừ (drop) các dữ liệu đột biến. Việc này dành làm bài tập cho những ai quan tâm để nâng cao hiệu quả của mô hình nhé!
Để nâng cao hiệu của của mô hình, nhiều chuyên gia thường sử dụng thuật toán gradient boosting regression [1] để nâng cao hiệu quả. Để đọc thêm thuật toán này thì các bạn có thể tìm đọc tài liệu 1 bên dưới. Tác giả bài viết sử dụng thử thuật toán này thì thấy hiệu quả được nâng lên chút như sau:

from sklearn import ensemble
clf = ensemble.GradientBoostingRegressor(n_estimators = 20, max_depth = 5, min_samples_split = 2, learning_rate = 0.1, loss = 'ls')
clf.fit(x_train, y_train)
clf.score(x_test,y_test)
Các tham số trên hiện tác giả đang chọn ngẫu nhiên thôi nha! Tỷ lệ chính xác đã được tăng lên rồi, 73.34%. Đến đây, để biết được tập tham số nào tốt nhất cho mô hình thì ta nghĩ đến ngay phương pháp GridSearchCV. Thử với hàm sau nhé!
from sklearn.model_selection import GridSearchCV
def model_gradient_boosting_tree(Xtrain,Xtest,ytrain):
X_train = Xtrain
y_train = ytrain
gbr = ensemble.GradientBoostingRegressor(random_state=2018)
param_grid = {
'n_estimators': [20,150],
'max_features': [5,10,15,20],
'max_depth': [6,10],
'learning_rate': [0.1],
'subsample': [1]
}
model = GridSearchCV(estimator=gbr, param_grid=param_grid, n_jobs=1, cv=10, scoring='mean_squared_error')
model.fit(X_train, y_train)
print('Gradient boosted tree regression...')
print('Best Params:')
print(model.best_params_)
print('Best CV Score:')
print(-model.best_score_)
y_pred = model.predict(Xtest)
return y_pred, -model.best_score_
Kết quả ta được bộ params chuẩn được chọn như trong hình dưới.
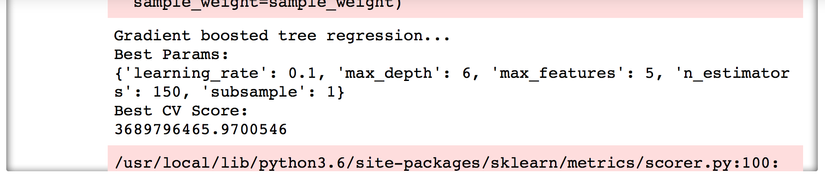
Dùng bộ params này chạy lại thì ta được kết quả như sau:
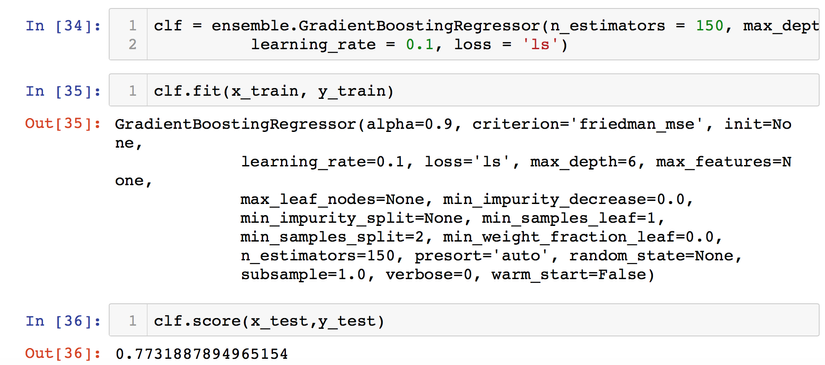
Hiệu quả lại được tăng lên rồi đó. Ta thấy đã được tăng lên là 77.31%. Nếu còn thời gian bạn đọc cố để cải thiện lên 90% nhé!
Lưu mô hình và triển khai dịch vụ
Để lưu mô hình thì mình đã hướng dẫn trong ĐN tương đối nhiều rồi nên bỏ qua bước này.
Cơ bản là khi có thông tin đầu vào mới thì ta có thể estimate 1 giá gần sát với thực tế thì càng tốt.
Ví dụ như kết quả bên dưới chẳng hạn.

P/S: Do code dùng để training nội bộ nên tác giả ko public được. Ai có nhu cầu thì pm để nhận code nhé!
Tài liệu tham khảo
All rights reserved
