Lựa chọn giải thuật Machine Learning tốt nhất cho vấn đề hồi quy của bạn
Bài đăng này đã không được cập nhật trong 7 năm
Khi tiếp cận bất kỳ loại vấn đề của Machine Learning (ML) nào, có rất nhiều giải thuật để lựa chọn. Trong machine learning, có 1 thứ gọi là "Không có gì dễ dàng" ( No Free Lunch) tạm hiểu là không có cách lựa chọn 1 giải thuật ML là tốt nhất để giải quyết mọi vấn đề. Hiệu năng của giải thuật ML phụ thuộc lớn vào kích thước cũng như cấu trúc dữ liệu của bạn. Do đó, sự lựa chọn thuật toán chính xác vẫn chưa rõ ràng trừ khi chúng tôi kiểm tra chúng bằng các thử nghiệm cũ và các lỗi.
Nhưng, có 1 vài ưu và nhược điểm đối với mỗi thuật toán ML và chúng ta có thể sử dụng chúng như hướng dẫn viên. Mặc dù, một thuật toán sẽ không lúc nào cũng tốt hơn cái khác, có vài thuộc tính của mỗi giải thuật chúng ta có thể sử dụng chúng như hướng dẫn lựa chọn chính xác nhanh và điểu chỉnh các tham số mạnh mẽ. Chúng ta đang có 1 cái nhìn về 1 số thuật toán nỏi bật cho các vấn đề hồi quy và cài đặt hướng dẫn cho tới khi sử dụng chúng dựa trên điểm mạnh và yếu của chúng. Bài viết này sẽ phục vụ như là một trợ giúp tuyệt vời cho việc lựa chọn thuật toán ML tốt nhất cho vấn đề hồi quy của bạn!
Hồi quy tuyến tính và đa thức
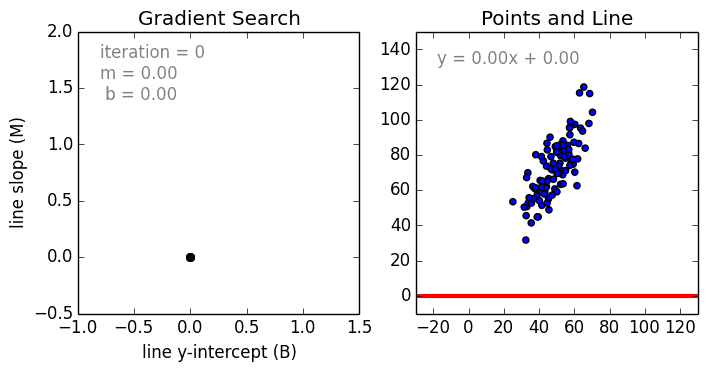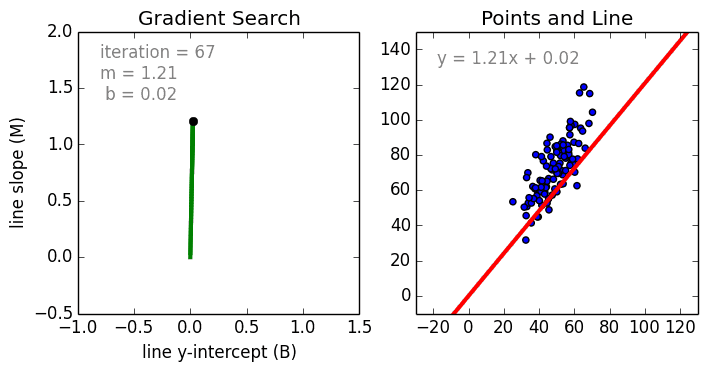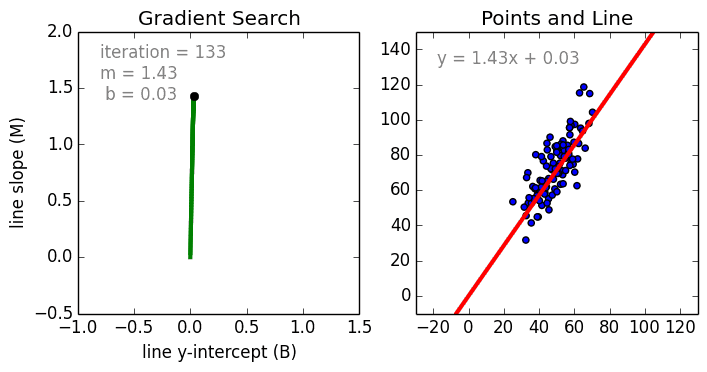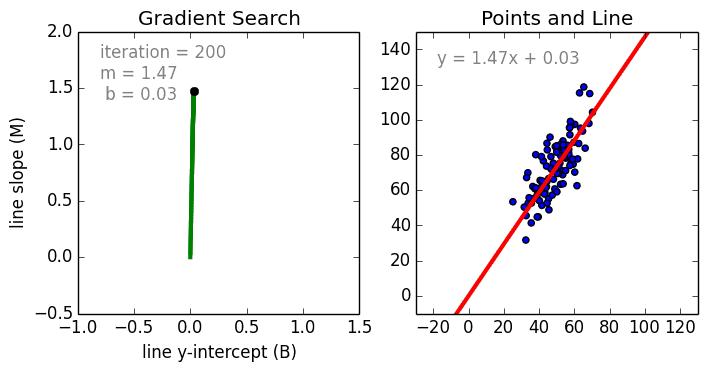
Bắt đầu với trường hợp đơn giản, Hồi quy tuyến tính biến đơn là một kỹ thuật được sử dụng để mô hình hóa mối quan hệ giữa một biến độc lập đầu vào (biến tính năng) và biến phụ thuộc đầu ra bằng mô hình tuyến tính, ví dụ như một đường. Trường hợp tổng quát hơn là Hồi quy tuyến tính đa biến trong đó một mô hình được tạo cho mối quan hệ giữa nhiều biến đầu vào độc lập (biến tính năng) và biến phụ thuộc đầu ra. Mô hình vẫn tuyến tính trong đó đầu ra là sự kết hợp tuyến tính của các biến đầu vào.
Có một trường hợp tổng quát thứ ba được gọi là Hồi quy đa thức trong đó mô hình bây giờ trở thành tổ hợp phi tuyến tính của các biến tính năng, có thể có các biến số mũ, sin và cos, v.v. Tuy nhiên, điều này đòi hỏi kiến thức về cách dữ liệu liên quan đến đầu ra. Các mô hình hồi quy có thể được đào tạo bằng cách sử dụng Stochastic Gradient Descent (SGD).
Ưu điểm:
-
Nhanh chóng để mô hình hóa và đặc biệt hữu ích khi mối quan hệ được mô hình hóa không quá phức tạp và nếu bạn không có nhiều dữ liệu.
-
Hồi quy tuyến tính là đơn giản để hiểu, nó rất có giá trị cho các quyết định kinh doanh.
Nhược điểm:
-
Đối với dữ liệu phi tuyến tính, hồi quy đa thức có thể khá khó khăn để thiết kế, vì người ta phải có một số thông tin về cấu trúc của dữ liệu và mối quan hệ giữa các biến tính năng.
-
Kết quả của những điều trên, các mô hình này không tốt như các mô hình khác khi nói đến dữ liệu rất phức tạp.
Neural Networks
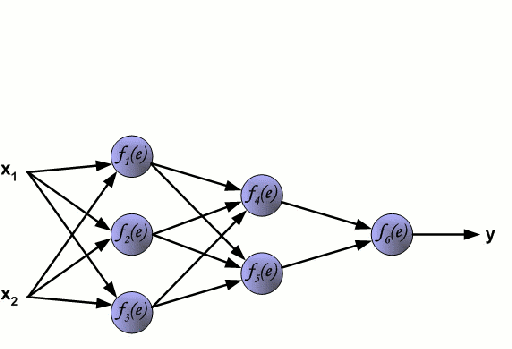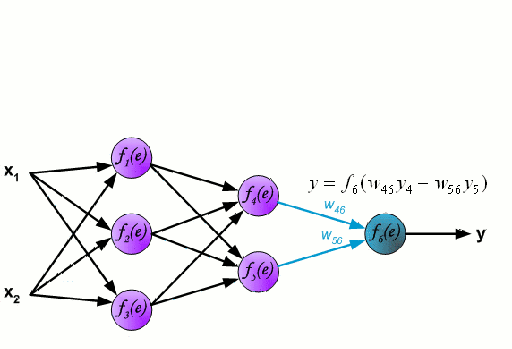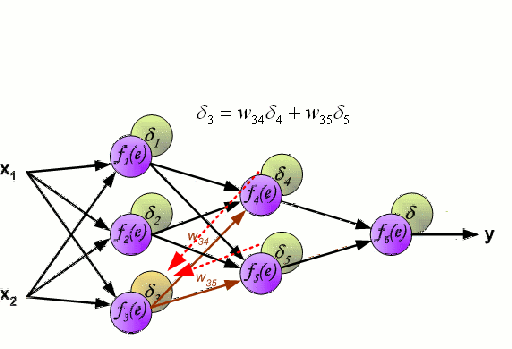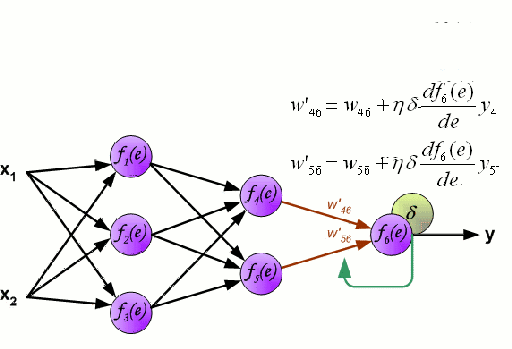
Mạng nơ-ron bao gồm một nhóm các nút được liên kết với nhau gọi là nơ-ron. Các biến tính năng đầu vào từ dữ liệu được truyền cho các nơ ron này dưới dạng kết hợp tuyến tính đa biến, trong đó các giá trị nhân với mỗi biến tính năng được gọi là trọng số. Một phi tuyến tính sau đó được áp dụng cho sự kết hợp tuyến tính này mang lại cho mạng thần kinh khả năng mô hình hóa các mối quan hệ phi tuyến tính phức tạp. Một mạng lưới thần kinh có thể có nhiều lớp trong đó đầu ra của một lớp được truyền sang lớp kế tiếp theo cùng một cách. Ở đầu ra, thường không áp dụng phi tuyến tính. Mạng nơ-ron được đào tạo bằng cách sử dụng Stochastic Gradient Descent (SGD) và thuật toán backpropagation (cả hai được hiển thị trong GIF ở trên).
Ưu điểm:
-
Vì các mạng thần kinh có thể có nhiều lớp (và do đó là các tham số) với các phi tuyến tính, nên chúng rất hiệu quả trong việc mô hình hóa các mối quan hệ phi tuyến tính rất phức tạp.
-
Chúng tôi nói chung don don phải lo lắng về cấu trúc dữ liệu tại các mạng thần kinh rất linh hoạt trong việc học hầu hết mọi loại mối quan hệ biến đổi tính năng.
-
Nghiên cứu đã chỉ ra rằng chỉ cần cung cấp cho mạng nhiều dữ liệu đào tạo hơn, cho dù hoàn toàn mới hoặc từ việc tăng bộ dữ liệu gốc, sẽ mang lại hiệu quả cho mạng
Nhược điểm:
-
Do sự phức tạp của các mô hình này, chúng không dễ hiểu và để hiểu.
-
Chúng có thể khá khó khăn và tính toán chuyên sâu để sử dụng, đòi hỏi phải điều chỉnh siêu tham số cẩn thận và thiết lập lịch trình tỷ lệ học tập.
-
Chúng đòi hỏi rất nhiều dữ liệu để đạt được hiệu năng cao và thường vượt trội hơn so với các thuật toán ML khác trong các trường hợp dữ liệu nhỏ
Cây hồi quy và rừng ngẫu nhiên
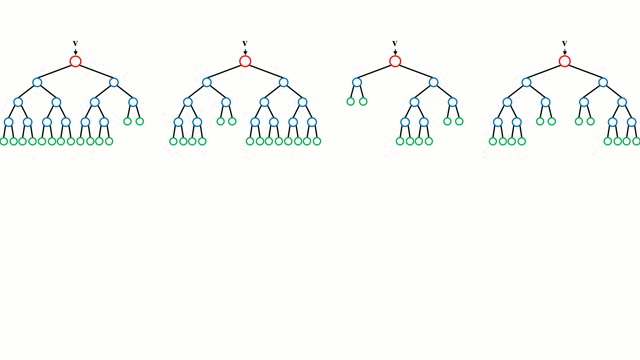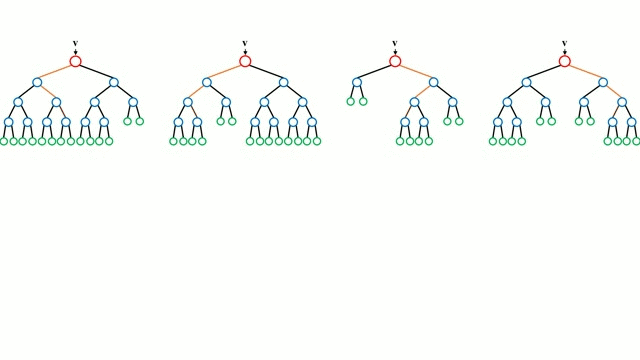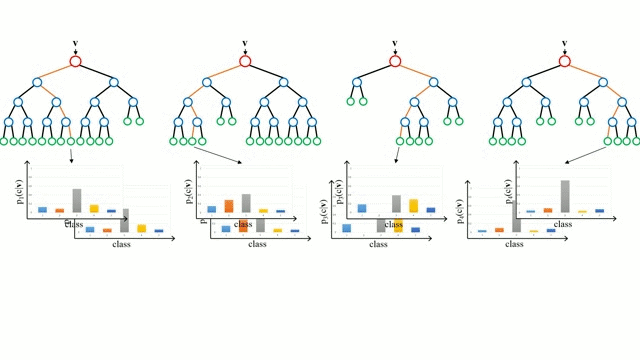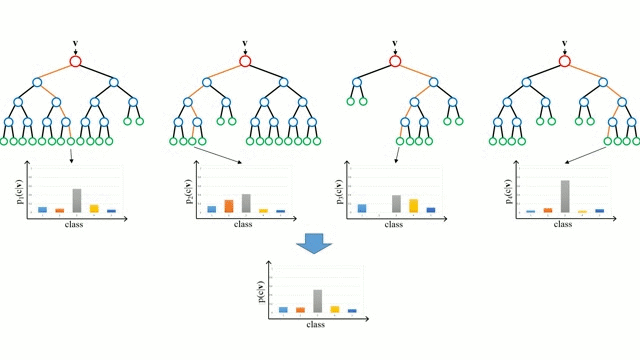
Bắt đầu với trường hợp cơ sở, Cây quyết định là một mô hình trực quan trong đó bằng cách đi qua các nhánh của cây và chọn nhánh tiếp theo để đi xuống dựa trên quyết định tại một nút. Cảm ứng cây là nhiệm vụ lấy một tập hợp các trường hợp đào tạo làm đầu vào, quyết định các thuộc tính nào là tốt nhất để phân tách, tách dữ liệu và định kỳ trên các tập dữ liệu phân tách kết quả cho đến khi tất cả các trường hợp đào tạo được phân loại. Trong khi xây dựng cây, mục tiêu là phân chia các thuộc tính tạo ra các nút con tinh khiết nhất có thể, sẽ giữ tối thiểu số lượng phân tách cần thực hiện để phân loại tất cả các phiên bản trong tập dữ liệu của chúng tôi. Độ tinh khiết được đo lường bằng khái niệm tăng thông tin, liên quan đến mức độ cần biết về một trường hợp chưa từng thấy trước đây để được phân loại chính xác. Trong thực tế, điều này được đo bằng cách so sánh entropy hoặc lượng thông tin cần thiết để phân loại một thể hiện của phân vùng tập dữ liệu hiện tại, với lượng thông tin để phân loại một thể hiện nếu phân vùng dữ liệu hiện tại được phân vùng tiếp theo trên một phân vùng nhất định thuộc tính.
Rừng ngẫu nhiên chỉ đơn giản là một tập hợp các cây quyết định. Vectơ đầu vào được chạy qua nhiều cây quyết định. Đối với hồi quy, giá trị đầu ra của tất cả các cây được tính trung bình; để phân loại một sơ đồ bỏ phiếu được sử dụng để xác định lớp cuối cùng.
Ưu điểm:
-
Tuyệt vời trong việc học các mối quan hệ phức tạp, phi tuyến tính cao. Chúng thường có thể đạt được hiệu suất khá cao, tốt hơn so với hồi quy đa thức và thường ngang bằng với các mạng thần kinh.
-
Rất dễ để giải thích và hiểu. Mặc dù mô hình được đào tạo cuối cùng có thể học các mối quan hệ phức tạp, ranh giới quyết định được xây dựng trong quá trình đào tạo rất dễ hiểu và thực tế.
Nhược điểm:
-
Do tính chất của cây quyết định đào tạo, chúng có thể dễ bị quá tải. Một mô hình cây quyết định hoàn thành có thể quá phức tạp và chứa cấu trúc không cần thiết. Mặc dù điều này đôi khi có thể được giảm bớt bằng cách cắt tỉa cây thích hợp và các quần thể rừng ngẫu nhiên lớn hơn.
-
Sử dụng các nhóm rừng ngẫu nhiên lớn hơn để đạt được hiệu suất cao hơn đi kèm với những hạn chế là chậm hơn và đòi hỏi nhiều bộ nhớ hơn.
Phần kết luận
Bùm! Bạn đã có những ưu và nhược điểm! Trong bài tiếp theo, chúng tôi sẽ xem xét những ưu và nhược điểm của các mô hình phân loại khác nhau. Tôi hy vọng bạn thích bài đăng này và học được điều gì đó mới và hữu ích. Nếu bạn đã làm, vui lòng cho nó một số tiếng vỗ tay.
All rights reserved
