Bloom Filters: Tại sao các mạng blockchain lại thường sử dụng nó
Bài đăng này đã không được cập nhật trong 5 năm
Bloom filters là một cấu trúc dữ liệu xác suất, ra đời vào năm 1970 bởi Burton Howard, hiện đang được sử dụng rộng rãi trong lĩnh vực tìm kiếm và lưu trữ thông tin. Bài viết này sẽ trình bày cách thức hoạt động của bloom filters, sau đó giải thích những đánh đổi phụ thuộc vào mục đích riêng và cuối cùng là một vài ứng dụng.

1. Cách Bloom Filters Hoạt Động
1.1. Lưu Trữ
Bloom filters bao gồm một mảng m phần tử nhị phân (giá trị của mỗi phần tử là 0 hoặc 1), và k hàm băm được thiết kế sao cho output là số nguyên trong khoảng 1 -> m.
Note: Các hàm băm không hoạt động ngẫu nhiên, cùng 1 input đi vào thì hàm băm cũng sẽ cho ra cùng 1 output.
Ví dụ một bloom filter với m=16 và k=3:
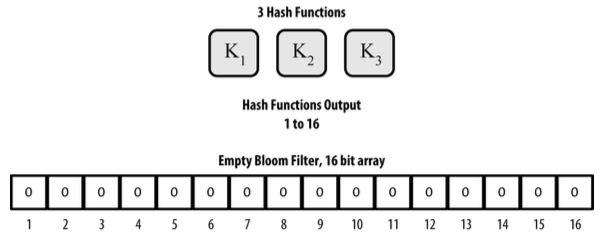
Ban đầu, các phần tử trong mảng có giá trị là 0. Để thêm một bản ghi A vào, A sẽ đi qua hàm băm đầu tiên, và phần tử tương ứng với output của hàm băm (trong khoảng 1->m) sẽ chuyển thành 1. Tương tự, A sẽ đi hết các hàm băm còn lại.
Ví dụ thêm bản ghi A vào bloom filter:
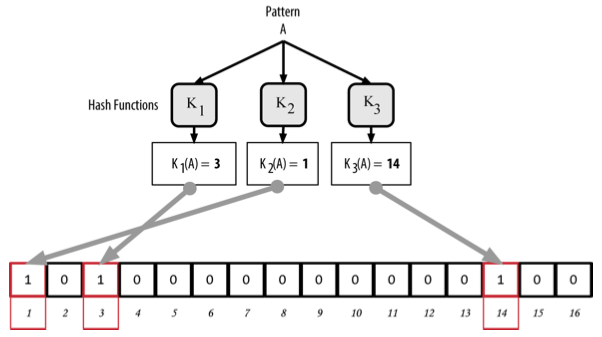
Tương tự với lưu trữ thêm bản ghi B. Điều đáng lưu ý là: nếu hàm băm (khi input B) trả về index của 1 phần tử có giá trị là một, thì giá trị đó vẫn được giữ nguyên . Về bản chất, số bản ghi lưu trữ càng nhiều, khả năng các phần tử trùng nhau càng tăng, khiến độ chính xác của Bloom filter càng giảm (sẽ được bàn luận sau). Đó là lý do tại sao Bloom filters được gọi là cấu trúc dữ liệu xác suất.
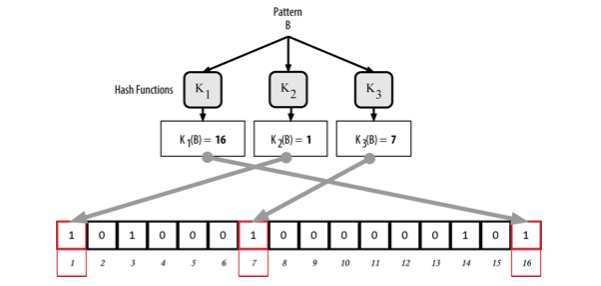
Ví dụ thêm bản ghi B và bị trùng phần tử thứ nhất:
1.2. Tìm Kiếm
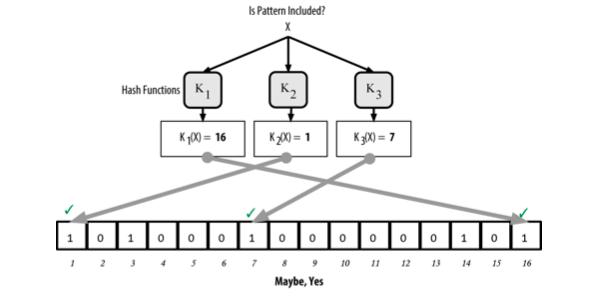
Để kiếm tra xem một bản ghi X có tồn tại trong bloom filters không, nó đi qua từng hàm băm tương tự ở trên. Sau đó, các kết quả được đối chiếu với mảng lưu trữ, nếu toàn bộ các phần tử có giá trị 1 thì bản ghi đó "có lẽ" là đã được lưu trữ. Lý do "có lẽ" là bởi một phần tử trong mảng có giá trị là 1 có thể là kết quả lưu trữ của nhiều bản ghi khác nhau, cấu trả lời vẫn chưa chắc chắn.
Ví dụ kiểm tra xem bản ghi X có nằm trong bloom filter, kết quả trả về "Có lẽ"
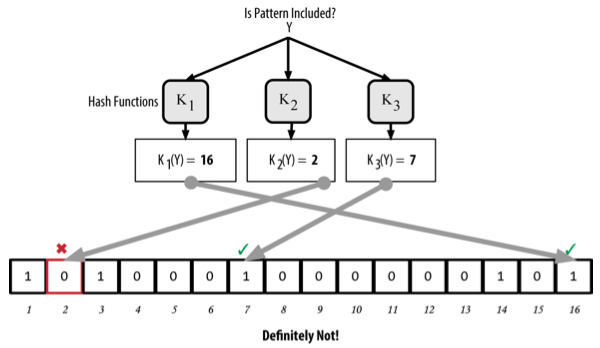
Ngược lại, nếu bất cứ phần tử nào từ output của hàm băm có giá trị 0, điều đó chứng minh bản ghi đó "Chắc chắn không" nằm trong bloom filters.
Ví dụ kiểm tra xem bản ghi Y có nằm trong bloom filter, kết quả trả về "Chắc chắn không"
2. Trade-off
Có thể khẳng định rằng: độ chính xác phụ thuộc vào số lượng bản ghi, kích thước mảng lưu trữ (m) và số hàm băm (k). Nói chung, càng tăng kích thước mảng và số hàm băm lên, bloom filters có thể lưu trữ càng nhiều bản ghi với độ chính xác cao hơn, tuy nhiên sẽ có những đánh đổi nhất định. Ta thử xem sét các trường hợp sau:
- Khi m quá nhỏ, số phần từ có giá trị 1 sẽ chiếm tỷ lệ lớn, dẫn đến kết quả false positive khi tìm kiếm thông tin. Vì vậy việc tăng kích thước mảng lên có thể giảm thiểu rủi ro này, nhưng sẽ tốn nhiều không gian lưu trữ hơn.
- Còn khi k quá nhỏ cũng khiến tỷ lệ kết quả false positive cao. Nhưng nếu k quá lớn lại dẫn đến chậm, do một bản ghi phải đi qua quá nhiều hàm băm (độ phức tạp về thời gian o(k)).
Đánh giá thực nghiệm khi đưa 10 triệu bản ghi vào lưu trữ:

Có thể thấy ở biểu đồ, khi giá trị của k và m lớn thì p (sác xuất kết quả false positive) sẽ nhỏ, tuy nhiên việc này làm Bloom filter chậm. Vì vậy, phương án tốt nhất ở đây là chọn m=100M và k=5, vì nó đã tối thiểu được độ phức tạp về không gian và thời gian.
3. Ứng dụng
- Google Bigtable, Apache HBase, Apache Cassandra và Postgresql sử dụng bloom filters trong quá trình tìm kiếm để nhanh chóng xác định một bản là không tồn tại. Qua đó, giảm được chi phí và tăng hiệu năng.
- Google Chrome dùng Bloom Filter để xác định các URL độc hại. Bất cứ URL nào đều phải kiểm tra thông qua Bloom filter ở nội bộ, và chỉ những cái có kết quả positive mới được " full check" (và nếu nó positive thật thì sẽ gửi cảnh báo cho người dùng).
- Medium thì sử dụng trong hệ gợi ý để kiểm tra xem một bài viết đã được đọc hay chưa bởi một người dùng.
Reference
All rights reserved
