@nhat-nguyen Số lượt view khi chưa login và đã login là khác nhau do phía Viblo đọc nội dung trang từ cache ra khi người dùng chưa đăng nhập. Sau khi login thành công thì không đọc nội dung trang từ cache nữa nên bạn sẽ thấy hai con số khác nhau chút xíu.
error during connect: In the default daemon configuration on Windows, the docker client must be run with elevated privileges to connect.: Get "http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.24/containers/json?all=1&filters=%7B%22label%22%3A%7B%22com.docker.compose.project%3Dchatgpt_telegram_bot-main%22%3Atrue%7D%7D&limit=0": open //./pipe/docker_engine: The system cannot find the file specified.
@maitrungduc1410 Dạ vâng, mình sẽ chạy composer update ở đâu vậy anh nhỉ, xin lỗi anh do em cũng mới học tập về mảng này nên cũng chưa rành lắm ạ, có gì nhờ anh chỉ chi tiết dùm em 1 tí, em cảm ơn
Haha cũng đúng, những project như vậy quy trình tuyển dụng gắt nên gà mờ thì khó mà vô được, mà vô nhưng toxic, không chịu theo process thì cũng out sớm.

THẢO LUẬN
@nhat-nguyen Số lượt view khi chưa login và đã login là khác nhau do phía Viblo đọc nội dung trang từ cache ra khi người dùng chưa đăng nhập. Sau khi login thành công thì không đọc nội dung trang từ cache nữa nên bạn sẽ thấy hai con số khác nhau chút xíu.
Vỗ tay... Vỗ tay... 👋👋👋
@quanlh cái này là lỗi do docker, bạn fix lỗi docker là được nhé
trông giống như là 1 bài so sánh dựa trên cơ sở cách đây vài năm vậy
Cảm ơn bạn nhé, mình sẽ sớm ra các tập tiếp theo của series 🤩
Cảm ơn bạn. Bạn kết nối mình qua FB nhé ^^ Nhân tiện mình cũng đang tham gia sự kiện viết bài đầu năm của Viblo, bạn cho mình xin 1 like và 1 comment nhé ^^ Cảm ơn bạn rất nhiều https://www.facebook.com/groups/viblo.community.official/posts/1597904074006555/
bài viết thú vị
Bị lỗi vậy là sao ạ xin chỉ giáo ạ
mình đã thêm hàm surrogate. Cảm ơn đóng góp của bạn nhé.
Cảm ơn bài viết của bạn nhé. Mình đã làm thành công
Cảm ơn ad đã chia sẻ
Cảm ơn những các bài viết và chia sẻ của bác nha, em sẽ đọc và học hỏi dần. Mà mong bác ra thêm serie phỏng vấn Fresher Dev nhé, đọc part 1 hay quá.
quá xịn chủ thớt ơiiiiiii
ngon ngon, thanks bro nhieeuf nha
Hóng series dành cho newbie 😃 cám ơn bạn vì bài viết ☺️
Hay quá. Cảm ơn bạn nhiều nhé. Mình đã làm theo và thành công rồi
@maitrungduc1410 Dạ vâng, mình sẽ chạy composer update ở đâu vậy anh nhỉ, xin lỗi anh do em cũng mới học tập về mảng này nên cũng chưa rành lắm ạ, có gì nhờ anh chỉ chi tiết dùm em 1 tí, em cảm ơn
Haha cũng đúng, những project như vậy quy trình tuyển dụng gắt nên gà mờ thì khó mà vô được, mà vô nhưng toxic, không chịu theo process thì cũng out sớm.
@KyThinh Chuẩn đó bạn. Giống như Viblo, mỗi bài viết sau khi publish đều được thêm URL vào trong sitemap: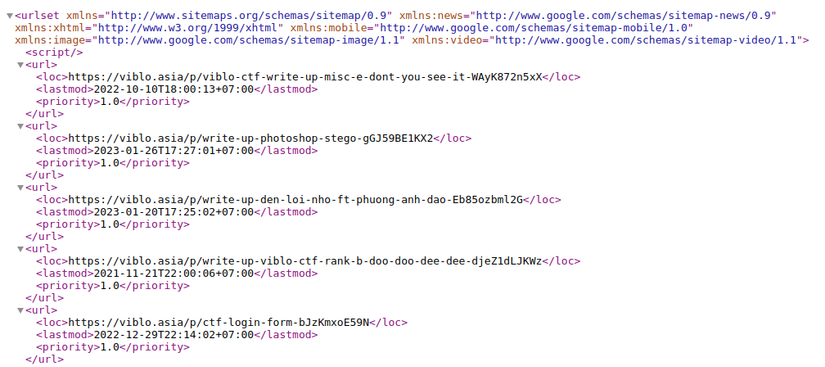
@tinhtn89 cho mình xem chỗ view child_category bạn viết như thế nào được không ạ