Hỏi mày phát.
Field target_type trong table medias điền gì vào mậy?
"posts" or "videos" hay "post" or "video" ?
Cảm ơn mày, bài viết khá hay. Để tao note lại.
Đồng quan điểm với tác giả.
Nói là "quan điểm" cũng chưa hẳn, vì bản thân mình đã trải qua những giai đoạn này rồi.
Công ty đầu tiên mình làm là một công ty quy mô không lớn. Không có người cầm tay chỉ việc, không có chế độ đãi ngộ tốt, tuy nhiên điều kiện làm việc không đến nổi tệ. Chỉ là các dự án đưa xuống đều phải tự tìm hiểu, tự học hỏi, tự đưa ra hướng giải quyết chính thay vì hỏi người này, chờ người kia chỉ đạo, giao task.
Sau hơn 1 năm 6 tháng làm việc, kĩ năng của mình lên rất nhanh. Cả về cách tự quản lý công việc, khả năng làm việc nhóm cùng những người khác và kĩ năng chuyên môn.
Trong khi đó, khá nhiều bạn học cùng khóa ra trường xin vào được các công ty lớn.
Khi vào, chỉ là một thành viên của team. Làm việc bằng lời chỉ đạo. Giao task nào hoàn thành task nấy rồi thôi. Không có va vấp nhiều với công việc. Không học được các kĩ năng quản lý dự án một cách độc lập và làm việc độc lập. Chỉ đảm nhận 1 khâu của toàn bộ quy trình.
Kết quả sau 1 năm 6 tháng: Hầu như có thể viết một vài module nhưng không thể tự xây dựng hoàn chỉnh một trang web cơ bản (lập trình web) ở mức mà một sinh viên đáng lẽ có thể làm được.
Không phải 1 mà là khá nhiều bạn đồng trang lứa của mình gặp vấn đề tương tự.
Nói đến một vấn đề nhạy cảm nữa, đó là mức lương.
Công ty nhỏ nên mức lương căn bản mình nhận được lúc vào là ~6tr. Trong khi bạn bè apply vào công ty lớn với mức lương 7 triệu.
Sau 1 năm 6 tháng, mình rời công ty cũ và apply vào một công ty khác với mức lương hiện tại của mình là 16 triệu. Với các bạn ấy là 8 triệu 5, được đo bằng kỹ năng và chuyên môn.
Thế mới nói, quan điểm "Công ty càng lớn, lương càng cao, môi trường phát triển càng tốt" đôi khi không đúng với đa phần các lập trình viên bọn mình.
Bài này mình viết cũng lâu rồi. Bây giờ sử dụng ckeditor upload ảnh lên không cần phải trả về view nữa mà chỉ cần trả về chuỗi json là xong dạng:
['url'=>'file.jpg','uploaded'=>1,];
Ví dụ một hàm trong controller thực hiện việc upload:
publicfunctionuploadImage(ImageRequest$request){try{// Đoạn này là đoạn lưu file, file sẽ nằm trong param có tên là 'upload'$image=ImageUploader::withFile($request->file('upload'))->save();returnresponse()->json(['fileName'=>basename($image),'uploaded'=>1,'url'=>Storage::disk('public')->url($image),]);}catch(Exception$e){returnresponse()->json(['uploaded'=>0,'error'=>['message'=>$e->getMessage(),],]);}}

THẢO LUẬN
Tại sao em bị lỗi không thể chạy được eureka server ngay từ đâu vậy ?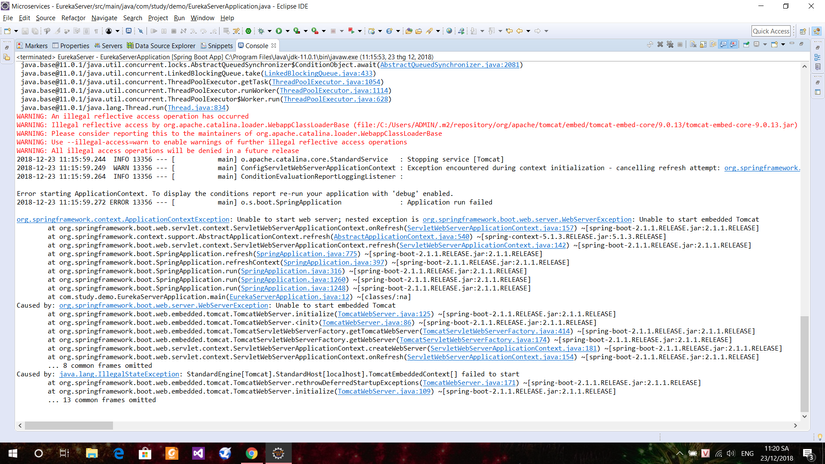
oke thanks bạn nhiều, để mình tham khảo.
Cảm ơn bạn, bài viết đã cho mình cái nhìn tổng quan về apache spark
Bài viết rất hay. Mình đã phải tạo account để cmt. Thanks!
Hỏi mày phát. Field target_type trong table medias điền gì vào mậy? "posts" or "videos" hay "post" or "video" ? Cảm ơn mày, bài viết khá hay. Để tao note lại.
Đồng quan điểm với tác giả. Nói là "quan điểm" cũng chưa hẳn, vì bản thân mình đã trải qua những giai đoạn này rồi. Công ty đầu tiên mình làm là một công ty quy mô không lớn. Không có người cầm tay chỉ việc, không có chế độ đãi ngộ tốt, tuy nhiên điều kiện làm việc không đến nổi tệ. Chỉ là các dự án đưa xuống đều phải tự tìm hiểu, tự học hỏi, tự đưa ra hướng giải quyết chính thay vì hỏi người này, chờ người kia chỉ đạo, giao task. Sau hơn 1 năm 6 tháng làm việc, kĩ năng của mình lên rất nhanh. Cả về cách tự quản lý công việc, khả năng làm việc nhóm cùng những người khác và kĩ năng chuyên môn. Trong khi đó, khá nhiều bạn học cùng khóa ra trường xin vào được các công ty lớn. Khi vào, chỉ là một thành viên của team. Làm việc bằng lời chỉ đạo. Giao task nào hoàn thành task nấy rồi thôi. Không có va vấp nhiều với công việc. Không học được các kĩ năng quản lý dự án một cách độc lập và làm việc độc lập. Chỉ đảm nhận 1 khâu của toàn bộ quy trình. Kết quả sau 1 năm 6 tháng: Hầu như có thể viết một vài module nhưng không thể tự xây dựng hoàn chỉnh một trang web cơ bản (lập trình web) ở mức mà một sinh viên đáng lẽ có thể làm được. Không phải 1 mà là khá nhiều bạn đồng trang lứa của mình gặp vấn đề tương tự. Nói đến một vấn đề nhạy cảm nữa, đó là mức lương. Công ty nhỏ nên mức lương căn bản mình nhận được lúc vào là ~6tr. Trong khi bạn bè apply vào công ty lớn với mức lương 7 triệu. Sau 1 năm 6 tháng, mình rời công ty cũ và apply vào một công ty khác với mức lương hiện tại của mình là 16 triệu. Với các bạn ấy là 8 triệu 5, được đo bằng kỹ năng và chuyên môn. Thế mới nói, quan điểm "Công ty càng lớn, lương càng cao, môi trường phát triển càng tốt" đôi khi không đúng với đa phần các lập trình viên bọn mình.
sao ko thấy link dow của bác nhỉ
quá hay với người chưa hề biết gì về linux/unix ạ cảm ơn nhiều nhiều tác giả
cảm ơn nhiều nhiều tác giả 

You can find me on FB: https://www.facebook.com/sreang.rathanak
@doan.van.toan đều trả về đúng view hết anh ạ
@devil_boom_129 vậy thì em thử kiểm tra xem trong hàm onCreateView đã return về view như em mong muốn trong xml chưa? Khả năng là lỗi ở đây
@doan.van.toan hay thậm chí cái fragment thứ 2 có mỗi 1 cái textView cũng không hiển thị nốt
@doan.van.toan hiện giờ em hết crash rồi cơ mà lại có lỗi hiện thị là search_view em thiết kế nó lại không hiển thị ở tab anh ạ
Bài này mình viết cũng lâu rồi. Bây giờ sử dụng ckeditor upload ảnh lên không cần phải trả về view nữa mà chỉ cần trả về chuỗi json là xong dạng:
Ví dụ một hàm trong controller thực hiện việc upload:
Còn trên phần hiển thị em chỉ cần thêm:
Các textarea cần thêm ckeditor thì chỉ cần cho class 'ckeditor' vào là xong. Còn việc upload lên flickr thì bạn tham khảo bài này: https://viblo.asia/p/upload-anh-len-flickr-bang-laravel-MVpeKylQvKd
tạm thời mình sửa được lỗi trên rồi đó )
còn bug crash thì phải đọc log ròi tạo ticket khác thoai
)
còn bug crash thì phải đọc log ròi tạo ticket khác thoai 

anh ơi xong app em crash anh ạ
Còn rất nhiều các life circle như: ComponentWillMount , ComponentWillReceiveProps,... bài viết sao thiếu nhiều nhỉ
thanks bạn
Rất hay!