Example Fuzzy Full Text Search
Bài đăng này đã không được cập nhật trong 7 năm
Fuzzy Seach (tìm kiếm "mờ"), hay còn hay được gọi là Approximate Search (tìm kiếm "xấp xỉ") là khái niệm để chỉ kỹ thuật để tìm kiếm một xâu "gần giống" (thay vì "giống hệt") so với một xâu cho trước.
By: Thang Tran Duc
Đây là câu mở đầu của bài viết Simple Fuzzy Search Đọc đến đây chắc các bạn cũng biết rằng bài này mình sẽ viết về Fuzzy Search. Tại lâu quá không viết bài nào nên mình cũng không biết nên mở đầu ra sao nữa. Mong các bạn thông cảm  .
.
Nếu bạn chưa biết về Fuzzy Seach có thể đọc bài viết ở link trên. Tuy không hẳn là đầy đủ nhưng vẫn giúp phần nào cho việc tìm hiểu. Trong bài viết này mình sẽ thử tự tạo Fuzzy Seach áp dụng thuật toán Khoảng cách Levenshtein với khoảng cách tối thiểu là 1 và sẽ kết hợp với full text search để tìm kiếm tương đối chính xác những thứ mình mong muốn.
Mở bài
Khi làm việc nhiều với Sql và gần đây là mysql mình tự hỏi một điều rằng:
Tại sao các hệ quản trị không thêm những thuật toán tìm kiếm để giúp đỡ cho những culi của làng code như mình nhỉ. Nghĩ đến đây mình đành ngậm ngùi tự nhủ à thì có mà dùng là được rồi, được voi đòi tiên mà để làm gì.
Chắc hẳn các bạn biết rằng trong Sql có 1 function là SOUNDEX() Công dụng của nó như sau:
- Soundex là một thuật toán ngữ âm để liệt kê các từ theo âm sắc, theo cách phát âm của tiếng Anh.
- Mục đích là mã hóa những từ có cùng cách phát âm qua những đặc trưng giống nhau, từ đó người ta có thể tìm được một từ nào đó dù có sai sót nhỏ trong chính tả từ đó
Vậy ta có thể sử dụng SOUNDEX kết hợp với full text search một cách dễ dàng mình sẽ làm ví dụ trong một bài viết gần nhất  .
.
Nhưng đây chắc chắn không phải là những gì mình muốn chương trình của mình thực hiện. Mình muốn có một thuật toán thật sịn sò và nếu được thì kết hợp luôn cả Levenshtein. Qua tìm tòi thì mình thấy mysql không có những tính năng này mà muốn sử dụng thì ta cần phải sử dụng những máy chủ tìm kiếm khác như SOLR hoặc Elaticsearch. Việc sử dụng 1 chương trình tìm kiếm thứ 3 làm cho phần mềm không cool ngầu Nên mình quyết định tự tạo một phương pháp cho bản thân mình =)). Nếu bạn đã đọc bài viết về Fuzzy Seach của anh Thắng thì sẽ biết rằng trong PHP có 1 hàm mang tên levenshtein nhưng trong ngôn ngữ khác thì hoàn toàn không. Do vậy mình sẽ làm từ đầu hết tất cả các công đoạn.
Thân bài
B1: Khoảng cách Levenshtein là gì
The Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other.
By: wikipedia.org
Để hiểu thêm xin mời tham khảo ví dụ này: Link
B2: Ý tưởng cho bài toán
Vởi khoảng cách tối thiểu là 1 ta sẽ dùng 3 phép biến đổi của Levenshtein để tạo ra những từ như sau. VD: Từ "Fuzzy", với một " _ " tương ứng là 1 ký tự hoặc cụm ký tự.
1, Thêm một ký tự
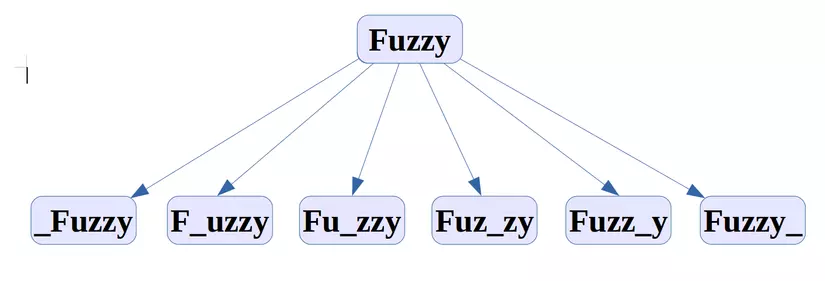
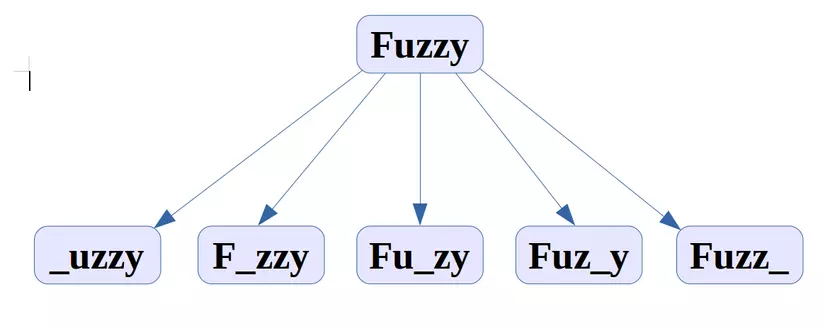
2, Bớt một ký tự
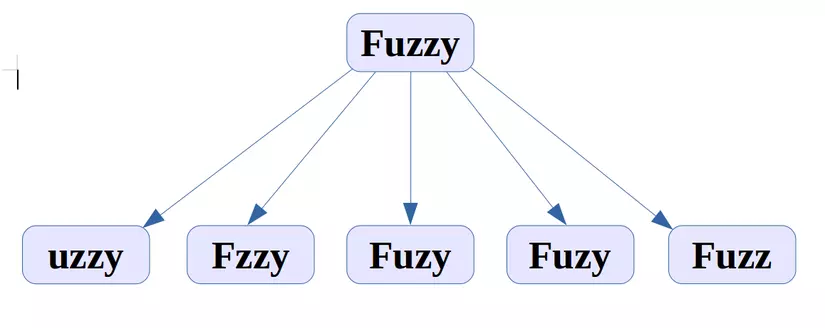
3, Thay đổi một ký tự
Vậy tổng cộng ta có 16 cụm từ cần phải tìm kiếm để kết quả chính xác nhất với mong muốn. Từ đây ta có thể viết được 1 câu query như sau.
SELECT * FROM table_name WHERE
`name` LIKE '%_fuzzy%' OR
`name` LIKE '%f_uzzy%' OR
`name` LIKE '%fu_zzy%' OR
`name` LIKE '%fuz_zy%' OR
`name` LIKE '%fuzz_y%' OR
`name` LIKE '%fuzzy_%' OR
`name` LIKE '%uzzy%' OR
`name` LIKE '%fzzy%' OR
`name` LIKE '%fuzy%' OR
`name` LIKE '%fuzz%' OR
`name` LIKE '%_uzzy%' OR
`name` LIKE '%f_zzy%' OR
`name` LIKE '%fu_zy%' OR
`name` LIKE '%fuz_y%' OR
`name` LIKE '%fuzz_%'
Khi nhìn số từ cần tìm kiếm ta có thể thấy ngay chúng ta cần (3 * n) + 1 từ so sánh (với n là độ dài của từ cần tìm kiếm). Đó là trong trường hợp ta dùng khoảng cách tối thiểu. Còn nếu gọi khoảng cách ta dùng là d thì ta phải có ít nhất là từ.
Đó là một con số rất lớn, Từ đây mình nhận ra rằng việc mình đang làm thật sự là ngu ngốc và ngây thơ  . Thôi kệ làm tiếp vậy.
. Thôi kệ làm tiếp vậy.
Từ câu Sql ở bên trên  bạn thấy việc tìm kiếm này tổng qua hơn hẳn việc chỉ sử dụng câu truy vấn thông thường như sau.
bạn thấy việc tìm kiếm này tổng qua hơn hẳn việc chỉ sử dụng câu truy vấn thông thường như sau.
SELECT * FROM table_name WHERE `name` LIKE '%fuzzy%'
Vậy làm sao để tạo ra một câu querry dài ngoằng như trên  Hãy cùng suy nghĩ nào.
Hãy cùng suy nghĩ nào.
B3: Suy nghĩ tiếp
Chỗ này mình viết giả code bằng js để hiển thị màu mè cho dễ nhìn .
Ở B2 ta đã xác định câu truy vấn cần tạo ra. Nhìn vào câu này ta có thể dễ dàng nghĩ đến giải pháp cộng chuỗi để tạo ra nó như sau:
var list_regex = ["_fuzzy", "f_uzzy",..., "fuzz_"];
var sql = "SELECT * FROM table_name WHERE ";
list_regex.forEach( function(el) {
if (el == list_regex.pop())
sql += `name LIKE '% ${el} %'`;
else
sql += `name LIKE '% ${el} %' OR`;
}
Đó ta có 1 đoạn giả code thật là .... Đến đây nếu bạn để ý ta đã có 1 thuật toán tím kiếm và tự đánh index cho dữ liệu rất chi là xịn sò trong Sql đó là Full text search. Có thể tóm tắt là nếu bạn tìm kiếm 1 cụm từ bằng full text search thì nó sẽ sinh ra cho bạn 1 câu query tương tự như trên. Từ đây công việc của chúng ta dễ hơn vài phần.
Biến mảng từ cần tìm thành 1 câu
var list_regex = ["_fuzzy", "f_uzzy",..., "fuzz_"];
var text_search = list_regex.join(' ');
Sau đó dùng full text search ta có 1 câu query như sau.
SELECT name FROM table_name WHERE MATCH (name) AGAINST (text_search IN BOOLEAN MODE);
Đó từ đây bạn không cần phải suy nghĩ để viết ra câu query dài kia làm gì. Cái gì khó có thể sử dụng mấy cái có sẵn cho đời thêm vui  .
.
B4: Viết function ngốc nghếch tạo ra cụm từ cần tìm kiếm
Đây là bước mất công suy nghĩ nhất của cái bài viết này. 
function my_Levenshtein_level_one(word, key) {
var list_regex = [];
var lg = word.length;
for (var i = 0; i < lg; i++) {
// Thêm một ký tự (insertions)
list_regex.push(word.substring(0, i) + key + word.substring(i, lg));
// Bớt một ký tự (deletions)
list_regex.push(word.substring(0, i) + word.substring(i+1, lg));
// Thay đổi một ký tự (substitutions)
list_regex.push(word.substring(0, i) + key + word.substring(i+1, lg));
}
// last insertion
list_regex.push(word + key);
return list_regex.join(' ');
}
Xong Thế là mình đã tự tạo được 1 stupid function để sử dụng. Và cuối cùng chúng ta cùng thử nghiệm chút nhé.
B5: Ngồi rung đùi và chờ kết quả
Kiểm tra dữ liệu xem như nào.
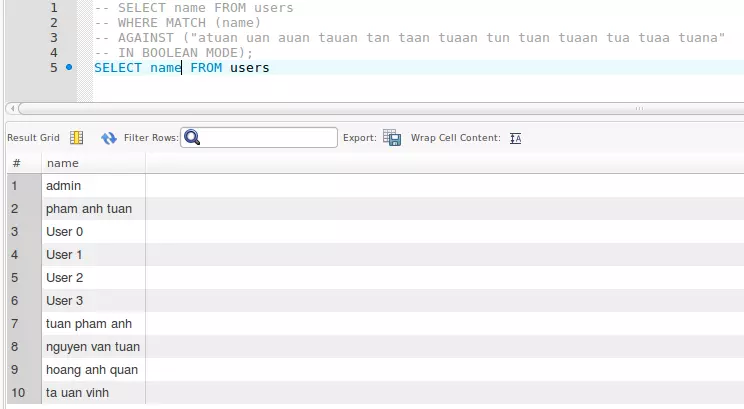
Kết quả khi dùng hàm my_Levenshtein_level_one('tuan', 'a');
my_Levenshtein_level_one('tuan', 'a');
// result "atuan uan auan tauan tan taan tuaan tun tuan tuaan tua tuaa tuana"
Kêt quả khi dùng Full text search
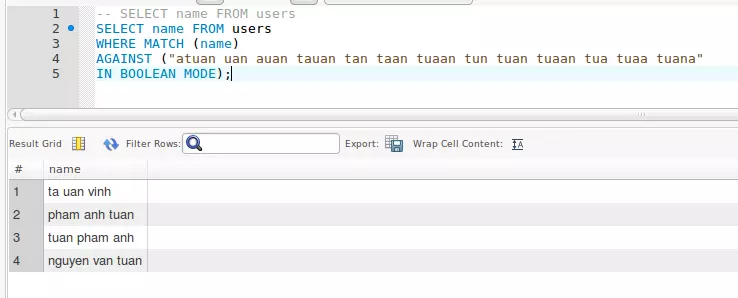
Yeah!!!. Kết quả đúng như mong muốn .
Kết luận
Mình không biết việc giành thời gian ra để suy nghĩ và tạo ra những vấn đề này không biết rằng có thực tế không. Bởi mình thấy khi các bạn làm việc bất chợt có một điều gì mới lạ trong task thì việc đầu tiên chúng ta thường nghĩ xem có thư viện gì làm việc này không nhỉ ?.
Nên việc rành thời gian ra để nghiên cứu tìm tòi những vấn đề này có vẻ là không thiết thực. Nhưng không sao vui vẻ với những cái mình đang làm là được rồi.
Cảm ơn các bạn đã đọc bài viết này. Nếu có ý kiến hay câu hỏi gì xin góp ý ở dưới nhé.
All rights reserved
