@chungminhtu bài check email hợp lệ anh làm vậy là ko đúng rồi, theo em thì case ABC.ABC.ABC.ABC0046@domain.com.com.com ko có gì sai cả, nếu bắt như anh thì mấy mail vn hay bất kì mail nào có nhiều dấu . sau @ đều ko nhận hết.
đơn cử như 4 email đầu
HELP!!!!!!!
em gửi cho fb thì thi thoảng fb lại đổi chính sách lằng ngoằng quá, bác có thể bỏ chút thời gian hướng dẫn với zalo không ạ?
tại chatwork không có bong bóng chat, e muốn thông báo có bong bóng chat tiện hơn mà mày mò code cho zalo trên này thì được mà nhúng vào google script không được
) useMemo chính là PureComp nhé. Cảm thấy ai lao vào học hook ngay thật sự k hình dung được luồng hoạt động và sâu về react. Khuyến cáo vẫn nên biết class trước khi dùng hook để nắm đc bản chất.
anh cho em hỏi là chỗ train_dir với val_dir kia là đường dẫn đến file chứa data train và data validation đúng không ạ, với cả em không thấy bước nào để resize lại ảnh ạ

THẢO LUẬN
đúng rồi
Đỉnh. Viết bài này chắc cũng hết 1 buổi tối ấy anh nhỉ :>
Thật tuyệt!
Thích những bài viết cụ thể như thế này. Tks
@chungminhtu bài check email hợp lệ anh làm vậy là ko đúng rồi, theo em thì case ABC.ABC.ABC.ABC0046@domain.com.com.com ko có gì sai cả, nếu bắt như anh thì mấy mail vn hay bất kì mail nào có nhiều dấu . sau @ đều ko nhận hết. đơn cử như 4 email đầu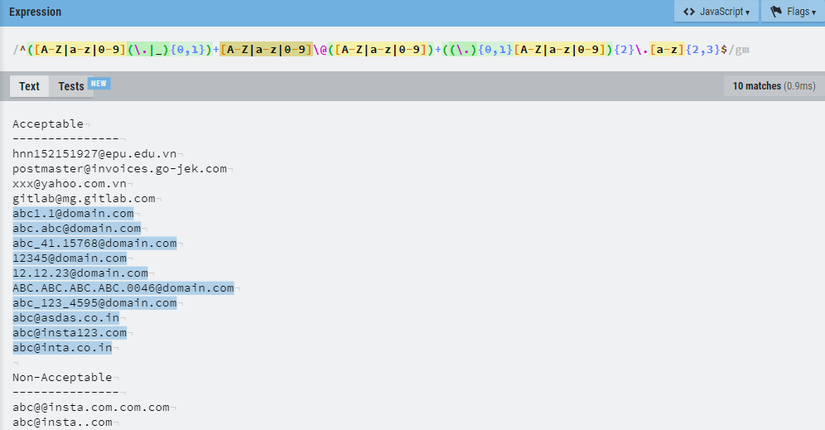
em làm như này anh cho nhận xét với ạ https://regex101.com/r/81Xacf/1
HELP!!!!!!! em gửi cho fb thì thi thoảng fb lại đổi chính sách lằng ngoằng quá, bác có thể bỏ chút thời gian hướng dẫn với zalo không ạ? tại chatwork không có bong bóng chat, e muốn thông báo có bong bóng chat tiện hơn mà mày mò code cho zalo trên này thì được mà nhúng vào google script không được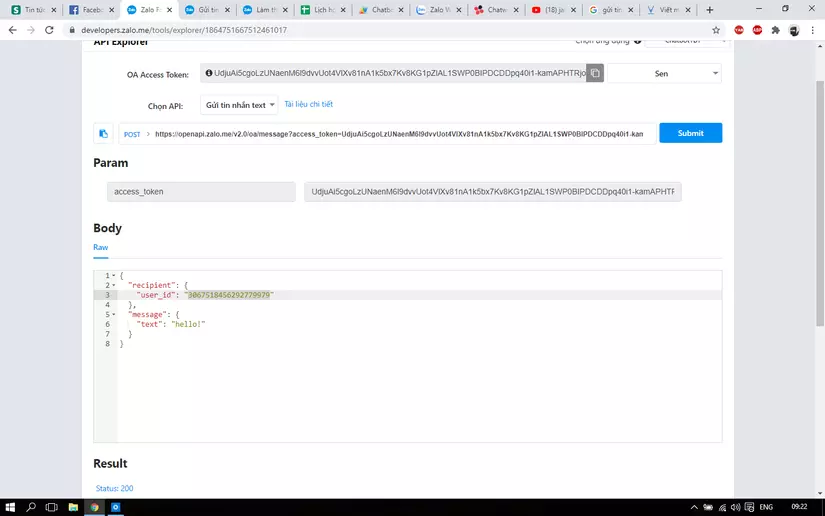
train_dir + val_dir là đúng rồi bạn. Còn ảnh thì mình đã resize trước đó rồi, nên bước này chỉ việc ném ảnh vào thôi
@hungpv em tạo bảng nhanh không để ý nó bác à
cám ơn bạn đã theo dõi
THanks
Cảm ơn bạn đã chia sẻ, phải nói là quá hay và mới mẻ.
Thanks bác đã hiểu hơn về cách dùng user trong docker
admin cho hỏi là khi kết nối mình kết nối con nào của replica sets, mongodb nói vầy mongodb://mongodb0.example.com:27017,mongodb1.example.com:27017,mongodb2.example.com:27017/?replicaSet=myRepl. Monh nhận phản hồi sớm từ bạn
dạ, em cảm ơn anh ah
thanks you bác.
anh cho em hỏi là chỗ train_dir với val_dir kia là đường dẫn đến file chứa data train và data validation đúng không ạ, với cả em không thấy bước nào để resize lại ảnh ạ
hay lắm ku. ngưỡng mộ