
BERT, RoBERTa, PhoBERT, BERTweet: Ứng dụng state-of-the-art pre-trained model cho bài toán phân loại văn bản
Bài đăng này đã không được cập nhật trong 5 năm
Xin chào tất cả mọi người, sau một thời gian rất rất dài im hơi lặng bóng, mình đã quay trở lại với công việc viết lách rồi đây (tara)
Cách đây gần 2 năm, mình bắt đầu biết đến BERT(Bidirectional Encoder Representations from Transformers), một nghiên cứu mới mang đầy tính đột phá, một bước nhảy vọt thực sự của Google trong lĩnh vực xử lý ngôn ngữ tự nhiên. Sự ra đời của pre-trained BERT đã kéo theo sự cải tiến đáng kể cho rất nhiều bài toán như Question Answering, Sentiment Analysis,...
Nếu đến nay các bạn vẫn chưa biết đến BERT là gì, bạn có thể đọc lại 2 bài viết trước đây của mình từ hồi 2018 là BERT- bước đột phá mới trong công nghệ xử lý ngôn ngữ tự nhiên của Google, Hiểu hơn về BERT: Bước nhảy lớn của Google và nhớ upvote cho chúng nếu thấy hữu ích(thực ra đến giờ cũng đã có rất nhiều bloger khác đã viết về BERT các bạn có thể tham khảo đọc). Ngày đó, kế hoạch của mình là sẽ viết về BERT gồm 3 phần với phần cuối cùng là Thực hành với BERT: Áp dụng thế nào cho tiếng Việt. Tuy nhiên, sự ngây thơ ngày đó đã va phải nhiều sự khó khăn dẫn đến việc mình không thể viết nổi phần 3, lý do đó là train BERT cho tiếng Việt không hề đơn giản như mình nghĩ và mình cũng chẳng có đủ điều kiện phần cứng để làm những gì mình nghĩ là khả thi. Và rồi mình nghỉ, xác định chỉ sử dụng pre-trained sẵn cho tiếng Anh với các tác vụ tiếng Anh. Mặc nhiên, mình không bao giờ áp dụng BERT cho các tác vụ tiếng Việt dù cho Google cũng có pre-trained multilingual bao gồm cả tiếng Việt nhưng nó cũng chỉ ổn.
Đã hai năm kể từ ngày đó, BERT vẫn chưa từng nguội đi sức nóng của mình và thực tế BERT ngày càng nóng hơn bao giờ hết. Với các phiên bản cải tiến, biến thể như RoBERTa, ALBERT, DistilBERT,... BERT đã càn quét các tác vụ xử lý ngôn ngữ tự nhiên, trở lên áp đảo trong các nền tảng thi đấu như Kaggle, AIVIVN cũng như shared task của nhiều hội nghị.

Và rồi, một ngày nọ, PhoBERT ra đời.
Pre-trained PhoBERT models are the state-of-the-art language models for Vietnamese (Pho, i.e. "Phở", is a popular food in Vietnam).
Vậy là từ nay mình đã hoàn toàn tự tin trong việc sử dụng một pre-trained BERT cho tiếng Việt, mình đã có thể dùng hàng Việt để giái quyết các bài toán cho tiếng Việt (đúng là ông lớn nhảy vào có khác) =)) =))
PhoBERT khá dễ dùng, nó được build để sử dụng luôn trong các thư viện siêu dễ dùng như FAIRSeq của Facebook hay Transformers của Hugging Face nên giờ đây BERT lại càng phổ biến ngay cả với ngôn ngữ tiếng Việt hay tiếng Anh.
Do vậy, bài viết này của mình sẽ là cái kết cho phần 3 đã hứa hẹn từ cách đây 2 năm trước nhưng theo một cách cực kì đơn giản, dễ dùng, đảm bảo các bạn chưa biết gì về NLP cũng có thể làm theo và sử dụng state-of-the-art này cho công việc của mình(Mình cũng đã thấy nhiều blog khác viết về cách sử dụng BERT, nhưng mình vẫn muốn viết lại xem sao ). Nhưng trước tiên, hãy quay lại một chút với lý thuyết để tìm hiểu xem PhoBERT được xây dựng như thế nào, một chút thông tin bản về nó sẽ kiến ta trở lên ngầu hơn. Sau đó, chúng ta sẽ được tìm hiểu về cách áp dụng các mô hình BERT, RoBERTa, PhoBERT cho nhiệm vụ phân loại văn bản cho cả tiếng Anh và tiếng Việt với sự hỗ trợ của FAIRSeq và Transformers. Nào, bắt đầu với PhoBERT.
PhoBERT là gì thế? Quá là sến!
(Cái này là mình mượn câu nói của 1 rick kid mới nổi thôi, không ý gì bảo các bác sến đâu, cơ mà sến thật)
Mình có đọc qua paper này ngay từ lúc PhoBERT mới được publish là hồi tháng 03/2020, tóm lại, PhoBERT có một số điểm chính như sau:
- Đây là một pre-trained được huấn luyện monolingual language, tức là chỉ huấn luyện dành riêng cho tiếng Việt. Việc huấn luyện dựa trên kiến trúc và cách tiếp cận giống RoBERTa của Facebook được Facebook giới thiệu giữa năm 2019. Đây là một cái tiến so với BERT trước đây. Còn cụ thể RoBERTa khác BERT như nào bạn có thể đọc ở paper của RoBERTa luôn nhé. Đây là một paper khá dễ đọc và mình cũng không muốn bài viết dài nên sẽ mặc định bỏ qua, RoBERTa: A Robustly Optimized BERT Pretraining Approach.
- Tương tự như BERT, PhoBERT cũng có 2 phiên bản là với 12 transformers block và với 24 transformers block.
- PhoBERT được train trên khoảng 20GB dữ liệu bao gồm khoảng 1GB Vietnamese Wikipedia corpus và 19GB còn lại lấy từ Vietnamese news corpus. Đây là một lượng dữ liệu khả ổn để train một mô hình như BERT.
- PhoBERT sử dụng RDRSegmenter của VnCoreNLP để tách từ cho dữ liệu đầu vào trước khi qua BPE encoder.
- Như đã nói ở trên, do tiếp cận theo tư tưởng của RoBERTa, PhoBERT chỉ sử dụng task Masked Language Model để train, bỏ đi task Next Sentence Prediction.
Tương tự PhoBERT, một phiên bản thứ 2 cũng được cùng nhóm tác giả của PhoBERT công bố hồi cuối tháng 05/2020 là BERTweet: A pre-trained language model for English Tweets, cái mà lát nữa chúng ta cũng sẽ sử dụng. Đây cũng là một pre-trained khá tương tự với PhoBERT, có lẽ khác nhau duy nhất là dữ liệu huấn luyện.
Nào, giờ chúng ta hãy bắt tay vào thực hành với BERT, PhoBERT và BERTweet. Cảm ơn sự tài trợ của FAIRSeq (Facebook) và Transformers (Hugging Face) đã giúp cho công việc dưới đây đơn giản và dễ dàng hơn rất nhiều. Mình cũng cảm ơn Việt Anh đã giới thiệu tới mình Simple Transformers mặc dù mình cũng không thích cái này lắm cơ mà okay, nó nhanh và đơn giản. Many thanks.
Thực hành với BERT
Để thực hành với BERT, PhoBERT và BERTweet, chúng ta sẽ cùng thử nghiệm với 2 bài toán phân loại văn bản. Bài toán đầu tiên là Phân loại sắc thái bình luận được tổ chức bởi AIVIVN và bài thứ hai là Identification of informative COVID-19 English Tweets là một shared task thuộc W-NUT 2020 đang diễn ra. Hai bài toán cần giải quyết đều là các bài toán phân loại nhị phân, tức là mỗi sample cần được mô hình gán 1 trong 2 nhãn tương ứng. Tuy nhiên, bài toán đầu tiên cần giải quyết là cho tiếng Việt, do đó PhoBERT được ưu tiên sử dụng trong khi task thứ 2 là tiếng Anh do vậy ngoài BERTweet chúng ta cũng có thể sử dụng nhiều mô hình pre-trained BERT khác.
Okie, chúng ta bắt đầu với bài toán đầu tiên, Phân loại sắc thái bình luận .
Phân tích sắc thái bình luận với PhoBERT
Đầu tiên, trước khi đọc và làm theo tất cả những điều bên dưới thì chúng ta sẽ cần phải cài các thư viện cần thiết đã.
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
Bạn cũng có thể cài đặt thư viện transformers bằng câu lệnh pip install transformers, tuy nhiên, riêng thư viện này mình ưu tiên cài đặt từ source như ở trên. Kế tiếp, chúng ta cài đặt fastBPE và FAIRSeq. Việc sử dụng thư viện FAIRSeq hay transformers để load pre-trained BERT và tune lại với bài toán của bạn là đơn giản như nhau, nên bạn cố thể chọn một trong 2 để thực hiện công việc của mình. Mình thì thấy việc sử dụng transformers thích hơn và nó có nhiều thứ hơn không chỉ là BERT, do vậy mình ưu tiên dùng thư viện này.
pip install fastBPE
pip install fairseq
Cuối cùng là cài đặt vncorenlp, một thư viện tách từ được publish bởi chính tác giả của PhoBERT.
# Install the vncorenlp python wrapper
pip install vncorenlp
# Download VnCoreNLP-1.1.1.jar & its word segmentation component (i.e. RDRSegmenter)
mkdir -p vncorenlp/models/wordsegmenter
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/VnCoreNLP-1.1.1.jar
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/vi-vocab
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/wordsegmenter.rdr
mv VnCoreNLP-1.1.1.jar vncorenlp/
mv vi-vocab vncorenlp/models/wordsegmenter/
mv wordsegmenter.rdr vncorenlp/models/wordsegmenter/
Hướng dẫn cài đặt cho VnCoreNLP này mình lấy từ repo gốc PhoBERT, yêu cầu máy bạn phải được cài trước java vì đây là một python wrapper cho java.
Để chắc chắn cài đặt thành công, bạn có thể thử sử dụng nó để tách từ cho một câu đơn giản theo cách dưới đây.
from vncorenlp import VnCoreNLP
rdrsegmenter = VnCoreNLP("/Absolute-path-to/vncorenlp/VnCoreNLP-1.1.1.jar", annotators="wseg", max_heap_size='-Xmx500m')
# rdrsegmenter = VnCoreNLP("/content/drive/My Drive/BERT/SA/vncorenlp/VnCoreNLP-1.1.1.jar", annotators="wseg", max_heap_size='-Xmx500m')
text = "Đại học Bách Khoa Hà Nội."
word_segmented_text = rdrsegmenter.tokenize(text)
print(word_segmented_text)
kết quả thu được là:
[['Đại_học', 'Bách_Khoa', 'Hà_Nội', '.']]
Sau khi cài đặt các thứ xong xuôi, mình tiến hành tải về bộ dữ liệu huấn luyện từ trang chủ cuộc thi của AIVIVN và pre-trained của PhoBERT xong tiến hành giải nén. Khi tải về pre-trained BERT, tùy vào việc bạn sử dụng thư viện nào để load model thì bạn sẽ cần phải tải về pre-trained tương ứng(PhoBERT_base_fairseq hay PhoBERT_base_transformers).
wget https://public.vinai.io/PhoBERT_base_fairseq.tar.gz
tar -xzvf PhoBERT_base_fairseq.tar.gz
wget https://public.vinai.io/PhoBERT_base_transformers.tar.gz
tar -xzvf PhoBERT_base_transformers.tar.gz
Khi giải nén PhoBERT base transformers, bạn sẽ thấy thư mục này gồm 4 file nhỏ bao gồm config.json chứa config của model, model.bin lưu trữ pre-trained weight của model, bpe.codes và dict.txt chứ từ điển sẵn có của PhoBERT. Tương tự, trong PhoBERT base FAIRSeq bạn cũng sẽ thấy 3 file model.pt, dict.txt và bpe.codes.
Bạn có thể load model và bpe này lên theo hướng dẫn của PhoBERT.
from fairseq.data.encoders.fastbpe import fastBPE
from fairseq.data import Dictionary
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--bpe-codes',
default="/content/drive/My Drive/BERT/SA/PhoBERT_base_transformers/bpe.codes",
required=False,
type=str,
help='path to fastBPE BPE'
)
args, unknown = parser.parse_known_args()
bpe = fastBPE(args)
# Load the dictionary
vocab = Dictionary()
vocab.add_from_file("/content/drive/My Drive/BERT/SA/PhoBERT_base_transformers/dict.txt")
Giờ đây, bạn có thể sử dụng bpe để encode 1 câu hay một đoạn văn bản thành một list các subword, vocab giúp bạn ánh xạ ngược từ subword về id của nó trong bộ tự vựng được cung cấp sẵn.
bpe.encode('Hôm_nay trời nóng quá nên tôi ở nhà viết Viblo!')
>>> Output: 'Hôm_nay trời nóng quá nên tôi ở nhà viết Vi@@ blo@@ !'
vocab.encode_line('<s> ' + 'Hôm_nay trời nóng quá nên tôi ở nhà viết Vi@@ blo@@ !' + ' </s>')
>>> Output: tensor([0, 3791, 1027, 898, 204, 77, 70, 25, 69, 467, 3696, 16856, 381, 2, 2], dtype=torch.int32)
Ở đây, với mỗi câu mình phải thêm <s> là token đặc biệt để đánh dấu vị trí đầu câu và </s> để đánh dấu vị trí cuối mỗi câu.
Tương tự, khi bạn tải về dữ liệu của cuộc thi Phân tích sắc thái bình luận bạn sẽ thấy 3 file bao gồm sample_submission.csv, test.crash và train.crash là file test mẫu, dữ liệu test và dữ liệu train cho cuộc thi.
Trước tiên, ta tiến hành đọc dữ liệu huấn luyện và dữ liệu test, tiền xử lý chúng đơn giản bằng cách sử dụng wordsegmenter.
Lưu ý:
In case the input texts are raw, i.e. without word segmentation, a word segmenter must be applied to produce word-segmented texts before feeding to PhoBERT. As PhoBERT employed the RDRSegmenter from VnCoreNLP to pre-process the pre-training data, it is recommended to also use the same word segmenter for PhoBERT-based downstream applications w.r.t. the input raw texts.
import re
train_path = '/content/drive/My Drive/BERT/SA/train.crash'
test_path = '/content/drive/My Drive/BERT/SA/test.crash'
train_id, train_text, train_label = [], [], []
test_id, test_text = [], []
with open(train_path, 'r') as f_r:
data = f_r.read().strip()
data = re.findall('train_[\s\S]+?\"\n[01]\n\n', data)
for sample in data:
splits = sample.strip().split('\n')
id = splits[0]
label = int(splits[-1])
text = ' '.join(splits[1:-1])[1:-1]
text = rdrsegmenter.tokenize(text)
text = ' '.join([' '.join(x) for x in text])
train_id.append(id)
train_text.append(text)
train_label.append(label)
with open(test_path, 'r') as f_r:
data = f_r.read().strip()
data = re.findall('train_[\s\S]+?\"\n[01]\n\n', data)
for sample in data:
splits = sample.strip().split('\n')
id = splits[0]
text = ' '.join(splits[1:])[1:-1]
text = rdrsegmenter.tokenize(text)
text = ' '.join([' '.join(x) for x in text])
test_id.append(id)
test_text.append(text)
Okay, giờ chúng ta đã có một list chứa các dữ liệu đã qua tách từ, ứng với list label của chúng là các nhãn 0 và 1. Coi như việc tách từ là tiền xử lý duy nhất của chúng ta.
train_text của chúng ta bây giờ sẽ như thế này.
['Dung dc sp tot cam on shop Đóng_gói sản_phẩm rất đẹp và chắc_chắn Chất_lượng sản_phẩm tuyệt_vời',
'Chất_lượng sản_phẩm tuyệt_vời . _Son mịn nhưng khi đánh lên không như màu trên ảnh',
'Chất_lượng sản_phẩm tuyệt_vời nhưng k có hộp k có dây giày đen k có tất',
': ( ( Mình hơi thất_vọng 1 chút vì mình đã kỳ_vọng cuốn sách khá nhiều hi_vọng nó sẽ nói về việc học_tập của cách sinh_viên trường Harvard ra sao những nỗ_lực của họ như_thế_nào 4h sáng ? tại_sao họ lại phải thức dậy vào thời_khắc đấy ? sau đó là cả một câu_chuyện ra sao . Cái mình thực_sự cần ở đây là câu_chuyện ẩn dấu trong đó để tự bản_thân mỗi người cảm_nhận và đi_sâu vào lòng người hơn . Còn cuốn sách này chỉ đơn_thuần là cuốn sách dạy kĩ_năng mà hầu_như sách nào cũng đã có . BUồn ...',
'Lần trước mình mua áo_gió màu hồng rất ok mà đợt này lại giao 2 cái áo_gió chất khác như vải mưa ý : ( (']
Mình tách dữ liệu ra thành 2 tập train và validation theo tỉ lệ 90:10.
from sklearn.model_selection import train_test_split
train_sents, val_sents, train_labels, val_labels = train_test_split(train_text, train_labels, test_size=0.1)
Tiếp theo, từ dữ liệu thô này, chúng ta sử dụng bpe đã load ở trên để đưa text đầu vào dưới dạng subword và ánh xạ các subword này về dạng index trong từ điển:
from tensorflow.keras.preprocessing.sequence import pad_sequences
MAX_LEN = 125
train_ids = []
for sent in train_sents:
subwords = '<s> ' + bpe.encode(sent) + ' </s>'
encoded_sent = vocab.encode_line(subwords, append_eos=True, add_if_not_exist=False).long().tolist()
train_ids.append(encoded_sent)
val_ids = []
for sent in val_sents:
subwords = '<s> ' + bpe.encode(sent) + ' </s>'
encoded_sent = vocab.encode_line(subwords, append_eos=True, add_if_not_exist=False).long().tolist()
val_ids.append(encoded_sent)
train_ids = pad_sequences(train_ids, maxlen=MAX_LEN, dtype="long", value=0, truncating="post", padding="post")
val_ids = pad_sequences(val_ids, maxlen=MAX_LEN, dtype="long", value=0, truncating="post", padding="post")
train_ids bây giờ đã trở thành một list dữ liệu mẫu trong đó mỗi mẫu là một list id của các subword có trong từ điển. Các câu ngắn hơn 125 subword được padding 0 ở cuối, những câu dài hơn được cắt đi cho đủ 125.
Tiếp theo, mình tạo một mask gồm các giá trị 0, 1 để làm đầu vào cho thư viện transformers, mask này cho biết các giá trị nào của chuỗi đã được padding.
train_masks = []
for sent in train_ids:
mask = [int(token_id > 0) for token_id in sent]
train_masks.append(mask)
val_masks = []
for sent in val_ids:
mask = [int(token_id > 0) for token_id in sent]
val_masks.append(mask)
Và giờ, dữ liệu đầu vào cho mô hình đã gần như chuẩn bị xong, chỉ cần chuyển về tensor và sử dụng DataLoader của torch để tạo dataloader nữa thôi.
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
import torch
train_inputs = torch.tensor(train_ids)
val_inputs = torch.tensor(val_ids)
train_labels = torch.tensor(train_labels)
val_labels = torch.tensor(val_labels)
train_masks = torch.tensor(train_masks)
val_masks = torch.tensor(val_masks)
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = SequentialSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=32)
val_data = TensorDataset(val_inputs, val_masks, val_labels)
val_sampler = SequentialSampler(val_data)
val_dataloader = DataLoader(val_data, sampler=val_sampler, batch_size=32)
Cuối cùng, việc chuẩn bị dữ liệu cũng đã xong. Chúng ta quay lại với việc load model PhoBERT. Như đã đề cập ở trên, PhoBERT cho chúng ta 2 lựa chọn là Fairseq và Transformers, tùy vào việc bạn thích hay quen với việc sử dụng thư viện nào, mình thì chọn Transformers của Hugging Face.
from transformers import RobertaForSequenceClassification, RobertaConfig, AdamW
config = RobertaConfig.from_pretrained(
"/content/drive/My Drive/BERT/SA/PhoBERT_base_transformers/config.json", from_tf=False, num_labels = 2, output_hidden_states=False,
)
BERT_SA = BertForSequenceClassification.from_pretrained(
"/content/drive/My Drive/BERT/SA/PhoBERT_base_transformers/model.bin",
config=config
)
BERT_SA.cuda()
BertForSequenceClassification sẽ nhận đầu vào là input_ids và input_mask, đầu ra trả về luôn loss cho classification task và phân phối xác xuất do mô hình dự đoán đầu ra. Chi tiết bạn có thể xem ở docs BertForSequenceClassification .
View lên nhìn xem mô hình này được thiết như nào, có gì khác biệt so với PhoBERT.
RobertaForSequenceClassification(
(roberta): RobertaModel(
(embeddings): RobertaEmbeddings(
(word_embeddings): Embedding(64001, 768, padding_idx=0)
(position_embeddings): Embedding(258, 768, padding_idx=0)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(classifier): RobertaClassificationHead(
(dense): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(out_proj): Linear(in_features=768, out_features=2, bias=True)
)
)
Thực ra nó vẫn là PhoBERT hay RoBERTa, chỉ khác là phần head của model đã được thêm 2 layers Dense và Dropout với droprate = 0.1.
Dưới đây là phần code hoàn thiện cho phần training mô hình. Bạn có thể để ý thì phần này không khác gì so với việc bạn train các mô hình khác sử dụng Pytorch chỉ khác việc giờ đây chúng ta đang sử dụng model được load bởi transformers.
import random
from tqdm import tqdm_notebook
device = 'cuda'
epochs = 10
param_optimizer = list(BERT_SA.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-5, correct_bias=False)
for epoch_i in range(0, epochs):
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
total_loss = 0
BERT_SA.train()
train_accuracy = 0
nb_train_steps = 0
train_f1 = 0
for step, batch in tqdm_notebook(enumerate(train_dataloader)):
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
BERT_SA.zero_grad()
outputs = BERT_SA(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = outputs[0]
total_loss += loss.item()
logits = outputs[1].detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_train_accuracy, tmp_train_f1 = flat_accuracy(logits, label_ids)
train_accuracy += tmp_train_accuracy
train_f1 += tmp_train_f1
nb_train_steps += 1
loss.backward()
torch.nn.utils.clip_grad_norm_(BERT_SA.parameters(), 1.0)
optimizer.step()
avg_train_loss = total_loss / len(train_dataloader)
print(" Accuracy: {0:.4f}".format(train_accuracy/nb_train_steps))
print(" F1 score: {0:.4f}".format(train_f1/nb_train_steps))
print(" Average training loss: {0:.4f}".format(avg_train_loss))
print("Running Validation...")
BERT_SA.eval()
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
eval_f1 = 0
for batch in tqdm_notebook(val_dataloader):
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
with torch.no_grad():
outputs = BERT_SA(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
logits = outputs[0]
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_eval_accuracy, tmp_eval_f1 = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
eval_f1 += tmp_eval_f1
nb_eval_steps += 1
print(" Accuracy: {0:.4f}".format(eval_accuracy/nb_eval_steps))
print(" F1 score: {0:.4f}".format(eval_f1/nb_eval_steps))
print("Training complete!")
Với bộ dữ liệu này, sẽ mất khoảng 5p để train xong 1 epoch. Và đây là kết quả.
======== Epoch 1 / 10 ========
Training...
Accuracy: 0.8370
F1 score: 0.8262
Average training loss: 0.3511
Running Validation...
Accuracy: 0.9118
F1 score: 0.9087
======== Epoch 2 / 10 ========
Training...
Accuracy: 0.9071
F1 score: 0.9025
Average training loss: 0.2348
Running Validation...
Accuracy: 0.9167
F1 score: 0.9131
======== Epoch 3 / 10 ========
Training...
Accuracy: 0.9261
F1 score: 0.9223
Average training loss: 0.1954
Running Validation...
Accuracy: 0.9148
F1 score: 0.9113
======== Epoch 4 / 10 ========
Training...
Accuracy: 0.9390
F1 score: 0.9358
Average training loss: 0.1662
Running Validation...
Accuracy: 0.9167
F1 score: 0.9138
======== Epoch 5 / 10 ========
Training...
Accuracy: 0.9510
F1 score: 0.9482
Average training loss: 0.1443
Running Validation...
Accuracy: 0.9148
F1 score: 0.9113
======== Epoch 6 / 10 ========
Training...
Accuracy: 0.9587
F1 score: 0.9566
Average training loss: 0.1271
Running Validation...
Accuracy: 0.9167
F1 score: 0.9127
======== Epoch 7 / 10 ========
Training...
Accuracy: 0.9645
F1 score: 0.9625
Average training loss: 0.1099
Running Validation...
Accuracy: 0.9142
F1 score: 0.9103
Sau khi train 10 epochs, mình thấy độ chính xác của mô hình đã khá tốt. F1 score trên tập validation do mình tự chia đã đạt ~0.9(thực ra đến epochs thứ 2 F1 đã đạt ~0.9), không biết submit lên trên AIVIVN thì kết quả thế nào. Nhưng có vẻ việc sử dụng PhoBERT cho task này khá tốt. Bạn có thể sử dụng full source code trong bài tại ĐÂY.
Đó, đó là toàn bộ những việc phải làm khi sử dụng PhoBERT cho task phân loại văn bản cho tiếng Việt. Việc test với dữ liệu test khá dễ dàng nên mình sẽ không viết nữa mà đó là bài tập về nhà cho các bạn.
Tiếp theo, chúng ta sẽ làm việc với task Identification of informative COVID-19 English Tweets.
Identification of informative COVID-19 English Tweets
Thực ra task này cũng không khác task bên trên là mấy, chỉ khác là giờ ta làm việc với tiếng Anh. Việc sử dụng BERTweet cũng khá đơn giản, giống hoàn toàn với những gì bên trên chúng ta đã làm. (chỉ khác là sẽ phải tiền xử lý khác, tách từ khác và load mô hình BERTweet thay vì PhoBERT). Việc sử dụng BERTweet là tương tự nên đúng ra mình sẽ không viết tiếp mà cho các bạn tự xử(coi như bài tập về nhà). Tuy nhiên, vì đây là bài toán cho tiếng Anh nên lại được rất nhiều thư viện hỗ trợ và bạn có thể sử dụng các pre-trained khác như BERT của Google, RoBERTa của Facebook, etc.
Và đó chính là lý do chúng ta vẫn có phần này. Giải quyết bài toán Identification of informative COVID-19 English Tweets với BERT và RoBERTa với chỉ với vài chục dòng code,
BERT và RoBERTa chỉ với vài chục dòng code?
Vâng, đó là sự thật vì giờ đây là đã có thể sử dụng BERT Tokenizer thay vì những thứ lằng nhằng như trước. Và do những cái này đã trở thành 1 pipeline quá cơ bản nên cũng đã có những thư viện được viết ở mức high api hơn, giúp chúng ta có thể sử dụng BERT theo pipeline một cách dễ dàng hơn, ít công sức hơn. Và đó chính là cái tới đây mình sẽ sử dụng Simple Transformers.
Về cơ bản, đây là một thư viện được viết dựa trên Transformers của Hugging Face nhưng đơn giản hơn, tự động hóa theo pipeline nhiều task như:
- Sequence Classification
- Token Classification (NER)
- Question Answering
- Language Model Fine-Tuning
- Language Model Training
- Language Generation
- T5 Model
- Seq2Seq Tasks
- Multi-Modal Classification
- Conversational AI.
- Text Representation Generation.
This library is based on the Transformers library by HuggingFace. Simple Transformers lets you quickly train and evaluate Transformer models. Only 3 lines of code are needed to initialize a model, train the model, and evaluate a model.
Mình không thích nó lắm, nhưng nó nhanh nên mình sẽ giới thiệu cho các bạn. Đúng như mô tả, bạn chỉ cần 3 dòng code là có thể xây dựng, train và đánh giá một mô hình với BERT. Chi tiết bạn cứ đọc ở documents của nó.
Quay lại với task Identification of informative COVID-19 English Tweets, đây vẫn là một bài toán phân loại nhị phân với 2 class là information và non-information. Chi tiết bạn có thể xem ở đây. Vẫn là hàng của Vin, với 2 file dữ liệu rất chuẩn chỉnh là train.tsv và valid.tsv. Mình sẽ sử dụng Simple để thử nghiệm bài toán này vì thư viện này nhận đầu vào là các file csv, tsv luôn.
Nhưng trước tiên, chúng ta hãy quay lại tiền xử lý bộ dữ liệu này một chút. Code tiền xử lý mình sử dụng luôn ở trong repo BERTweet được cung cấp bởi team BERTweet luôn.
from nltk.tokenize import TweetTokenizer
from emoji import demojize
import re
tokenizer = TweetTokenizer()
def normalizeToken(token):
lowercased_token = token.lower()
if token.startswith("@"):
return "@USER"
elif lowercased_token.startswith("http") or lowercased_token.startswith("www"):
return "HTTPURL"
elif len(token) == 1:
return demojize(token)
else:
if token == "’":
return "'"
elif token == "…":
return "..."
else:
return token
def normalizeTweet(tweet):
tokens = tokenizer.tokenize(tweet.replace("’", "'").replace("…", "..."))
normTweet = " ".join([normalizeToken(token) for token in tokens])
normTweet = normTweet.replace("cannot ", "can not ").replace("n't ", " n't ").replace("n 't ", " n't ").replace("ca n't", "can't").replace("ai n't", "ain't")
normTweet = normTweet.replace("'m ", " 'm ").replace("'re ", " 're ").replace("'s ", " 's ").replace("'ll ", " 'll ").replace("'d ", " 'd ").replace("'ve ", " 've ")
normTweet = normTweet.replace(" p . m .", " p.m.") .replace(" p . m ", " p.m ").replace(" a . m .", " a.m.").replace(" a . m ", " a.m ")
normTweet = re.sub(r",([0-9]{2,4}) , ([0-9]{2,4})", r",\1,\2", normTweet)
normTweet = re.sub(r"([0-9]{1,3}) / ([0-9]{2,4})", r"\1/\2", normTweet)
normTweet = re.sub(r"([0-9]{1,3})- ([0-9]{2,4})", r"\1-\2", normTweet)
return " ".join(normTweet.split())
Đọc dữ liệu và tiền xử lý nào:
import pandas as pd
train_df = pd.read_csv('/content/drive/My Drive/BERT/COVID19Tweet/train.tsv', sep='\t', header=0)
train_df.loc[:,"Text"] = train_df['Text'].apply(lambda x: normalizeTweet(x))
train_df.loc[:,"Label"] = train_df['Label'].apply(lambda x: 1 if x == 'INFORMATIVE' else 0)
train_df = train_df.drop(columns='Id')
train_df.columns = ["text", "labels"]
val_df = pd.read_csv('/content/drive/My Drive/BERT/COVID19Tweet/valid.tsv', sep='\t', header=0)
val_df.loc[:,"Text"] = val_df['Text'].apply(lambda x: normalizeTweet(x))
val_df.loc[:,"Label"] = val_df['Label'].apply(lambda x: 1 if x == 'INFORMATIVE' else 0)
val_df = val_df.drop(columns='Id')
val_df.columns = ["text", "labels"]
Cài đặt simple transformers:
pip install simpletransformers
Khởi tạo, huấn luyện và đánh giá mô hình với dữ liệu vừa xử lý:
from simpletransformers.classification import ClassificationModel
model = ClassificationModel("roberta", "roberta-base")
model.train_model(train_df)
result, model_outputs, wrong_predictions = model.eval_model(val_df)
Và đây là kết quả:
{'eval_loss': 0.47565516966581345,
'fn': 30,
'fp': 71,
'mcc': 0.8009832811950492,
'tn': 457,
'tp': 442}
F1 score ~89.75 chỉ với 1 epochs và đống params mặc định. Quá là chất.
Ở đây mình đang để các params là hoàn toàn mặc định, để thu được kết quả tốt hơn thì bạn phải thay đổi, tối ưu nhiều param trong quá trình huấn luyện như learning rate, số epochs, optimizer, loss weight với trường hợp dữ liệu bị imbalance. Tất cả bạn có thể đọc tại docs của Simple Transformes. Binary Classification
Ngoài ra, bạn cũng có thể thay mô hình pre-trained RoBERTa bằng các pre-trained khác như BERT, ALBER, CamemBERT, DistilBERT, etc đơn giản bằng cách thay param ở class ClassificationModel.
Và sau một thời gian tối ưu, thay đổi tham số, đây là kết quả của mình.
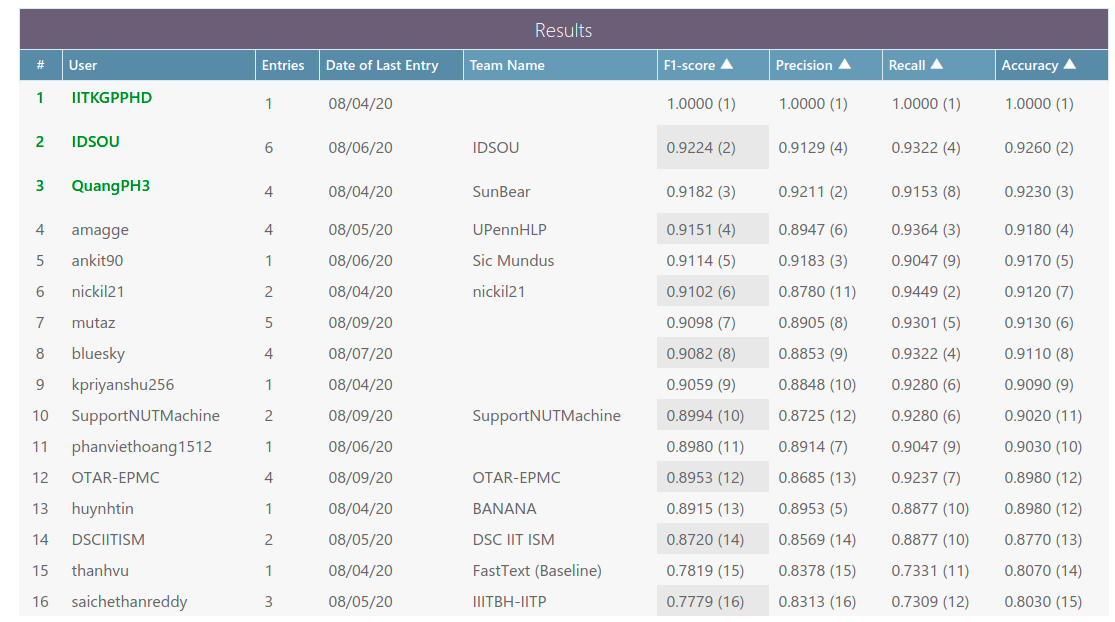
Trên đây là bài giới thiệu của mình về cách sử dụng mô hình pre-trained BERT, RoBERTa, PhoBERT và BERTweet trong nhiệm vụ phân loại văn bản bằng cách sử dụng 2 thư viện là Transformers của Hugging Face và Simple transformers một thư viện đơn giản để sử dụng với chỉ vài dòng code.
Nếu bài viết này hữu ích cho bạn thì tiếc gì một like.
Cảm ơn các bạn đã đọc bài. Có gì cần góp ý xin hãy để lại bình luận phía dưới đây. Xin cảm ơn.
All rights reserved
