BERT- bước đột phá mới trong công nghệ xử lý ngôn ngữ tự nhiên của Google
Bài đăng này đã không được cập nhật trong 5 năm
Có thể một số bạn quan tâm đã biết, ngày 2/11 vừa qua, trên Blog của Google AI đã công bố một bài viết mới giới thiệu về BERT, một nghiên cứu mới mang tính đột phá của Google trong lĩnh vực xử lý ngôn ngữ tự nhiên.
BERT là viết tắt của Bidirectional Encoder Representations from Transformers được hiểu là một mô hình học sẵn hay còn gọi là pre-train model, học ra các vector đại diện theo ngữ cảnh 2 chiều của từ, được sử dụng để transfer sang các bài toán khác trong lĩnh vực xử lý ngôn ngữ tự nhiên. BERT đã thành công trong việc cải thiện những công việc gần đây trong việc tìm ra đại diện của từ trong không gian số (không gian mà máy tính có thể hiểu được) thông qua ngữ cảnh của nó.
Trong bài viết này, mình sẽ giúp cho các bạn có cái nhìn tổng quan về BERT và những kết quả mà nó đạt được. Bài viết gồm các nội dung chính sau:
- Sự ra đời của BERT
- Điểm khác biệt của BERT so với các mô hình trước đó
- Các kết quả mà BERT đạt được
Bài viết này chỉ mang tính chất giới thiệu về BERT, để hiểu sâu về BERT bạn có thể đọc bài viết tiếp theo của mình tại bài Hiểu sâu về BERT hoặc thực hành với BERT tại bài viết Thực hành với BERT: Áp dụng thế nào cho Tiếng Việt.
Sự ra đời của BERT
Các nhà nghiên cứu làm việc tại Google AI tái khẳng định, sự thiếu hụt dữ liệu đào tạo là một trong những thách thức lớn nhất trong lĩnh vực xử lý ngôn ngữ tự nhiên. Đây là một lĩnh vực rộng lớn và đa dạng với nhiều nhiệm vụ riêng biệt, hầu hết các tập dữ liệu đều chỉ đặc thù cho từng nhiệm vụ. Để thực hiện được tốt những nhiệm vụ này ta cần những bộ dữ liệu lớn chứa hàng triệu thậm chí hàng tỷ ví dụ mẫu. Tuy nhiên, trong thực tế hầu hết các tập dữ liệu hiện giờ chỉ chứa vài nghìn hoặc vài trăm nghìn mẫu được đánh nhãn bằng tay bởi con người(các chuyên gia ngôn ngữ học). Sự thiếu hụt dữ liệu có nhãn chất lượng cao để đào tạo mô hình gây cản trở lớn cho sự phát triển của NLP nói chung.
Để giải quyết thách thức này, các mô hình xử lý ngôn ngữ tự nhiên sử dụng một cơ chế tiền xử lý dữ liệu huấn luyện bằng việc transfer từ một mô hình chung được đào tạo từ một lượng lớn các dữ liệu không được gán nhãn. Ví dụ một số mô hình đã được nghiên cứu trước đây để thực hiện nhiệm vụ này như Word2vec, Glove hay FastText.
Việc nghiên cứu các mô hình này sẽ giúp thu hẹp khoảng cách giữa các tập dữ liệu chuyên biệt cho đào tạo bằng việc xây dựng mô hình tìm ra đại diện chung của ngôn ngữ sử dụng một số lượng lớn các văn bản chưa được gán nhãn lấy từ các trang web.
Các pre-train model khi được tinh chỉnh lại trên các nhiệm vụ khác nhau với các bộ dữ liệu nhỏ như Question Answering, Sentiment Analysis,...sẽ dẫn đến sự cải thiện đáng kể về độ chính xác cho so với các mô hình được huấn luyện trước với các bộ dữ liệu này.
Tuy nhiên, các mô hình kể trên có những yếu điểm riêng của nó, đặc biệt là không thể hiện được sự đại diện theo ngữ cảnh cụ thể của từ trong từng lĩnh vực hay văn cảnh cụ thể.
Tiếp nối sự thành công nhất định của các mô hình trước đó, Google đã công bố thêm 1 kỹ thuật mới được gọi là Bidirectional Encoder Representations from Transformers(BERT). Với lần công bố này(kèm mã nguồn dự án), Google khẳng định bất kỳ ai trên thế giới đều có thể đào tạo được các hệ thống hỏi đáp(Question Answering) cải tiến hơn cho riêng mình hoặc rất nhiều các mô hình NLP khác chỉ bằng 1 vài giờ GPU duy nhất hoặc chỉ khoảng 30p TPU(có thể bạn chưa biết, Google đã cho phép bạn sử dụng TPU của họ 1 cách miễn phí tại Google Colab).
Một số trích dẫn từ các nhà nghiên cứu của Google AI sẽ cho bạn cái nhìn khái quát hơn:
"BERT is the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus (in this case, Wikipedia),"
"Integrating a bidirectional model supports access to context from both past, future and unsupervised directions of data – it can consume data that has not yet been categorized."
Hiện tại, BERT đã có sẵn trên Github và hiện mới chỉ hỗ trợ tiếng Anh nhưng mục tiêu của Google sẽ là phát hành các mô hình được đào tạo trên nhiều ngôn ngữ khác nhau trong tương lai.
BERT có thể biểu diễn ngữ cảnh 2 chiều
Vậy, điều gì làm cho BERT trở lên khác biệt so với các phương pháp trước đây?
Về mặt lý thuyết, các kỹ thuật khác như Word2vec, FastText hay Glove cũng tìm ra đại diện của từ thông qua ngữ cảnh chung của chúng. Tuy nhiên, những ngữ cảnh này là đa dạng trong dữ liệu tự nhiên. Ví dụ các từ như "con chuột" có ngữ nghĩa khác nhau ở các ngữ cảnh khác nhau như "Con chuột máy tính này thật đẹp!!" và "con chuột này to thật." Trong khi các mô hình như Word2vec, fastText tìm ra 1 vector đại diện cho mỗi từ dựa trên 1 tập ngữ liệu lớn nên không thể hiện được sự đa dạng của ngữ cảnh. Việc tạo ra một biểu diễn của mỗi từ dựa trên các từ khác trong câu sẽ mang lại kết quả ý nghĩa hơn nhiều. Như trong trường hợp trên ý nghĩa của từ con chuột sẽ được biểu diễn cụ thể dựa vào phần trước hoặc sau nó trong câu. Nếu đại diện của từ "con chuột" được xây dựng dựa trên những ngữ cảnh cụ thể này thì ta sẽ có được biểu diễn tốt hơn.
BERT mở rộng khả năng của các phương pháp trước đây bằng cách tạo các biểu diễn theo ngữ cảnh dựa trên các từ trước và sau đó để dẫn đến một mô hình ngôn ngữ với ngữ nghĩa phong phú hơn.
Để hiểu rõ hơn về phương pháp cũng như kiến trúc, bạn có thể đọc bài báo gốc tại đây và một bài viết chi tiết khác tại đây.
Kết quả mà BERT đạt được
Để đánh giá hiệu quả mà BERT đem lại, các kỹ sư thuộc Google AI đã so sánh BERT với các mô hình tốt nhất về NLP trước đây. Điều quan trọng là chúng ta chỉ việc sử dụng BERT thay cho các pre-train model trước đây mà không cần thực hiện bất kỳ thay đổi nào trong kiến trúc mạng neural sâu.
Kết quả là, trên SQUAD v1.1, BERT đạt được kết quả F1_score = 93.2%, vượt kết quả tốt nhất trước đó là 91.6% và hiệu năng mà con người đạt được là 91.2%.
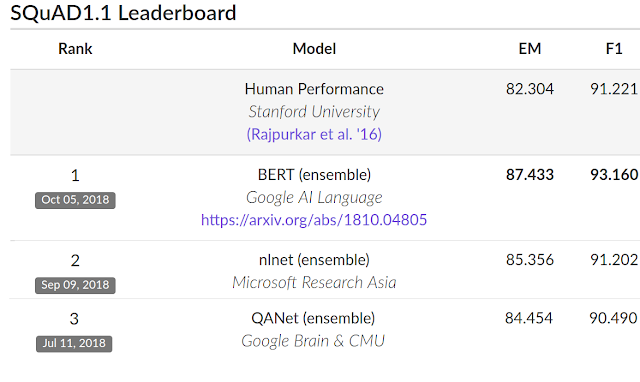
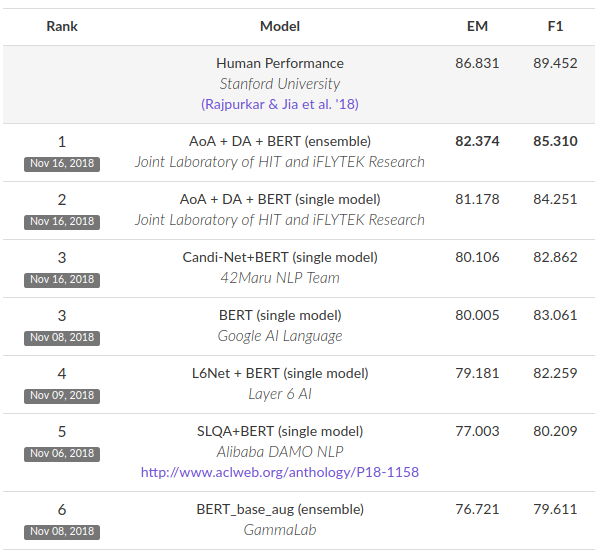
Trên SQUAD v2.0, Top 6 kết quả tốt nhất hiện giờ toàn bộ là của BERT.
BERT cũng cải thiện được hiệu năng tốt nhất trong thách thức GLUE benchmark, một bộ 9 nhiệm vụ Natural Language Understanding (NLU).
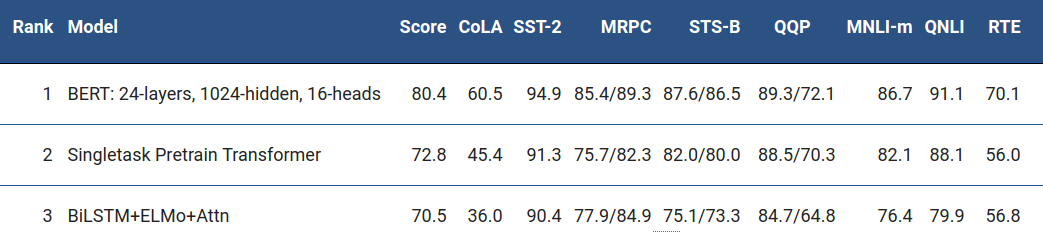
Sau 1 vài tuần ra mắt, BERT gần như đã chiếm top tất cả các nhiệm vụ của xử lý ngôn ngữ tự nhiên từ trước đến nay như 1 lần nữa khẳng định lại sức mạnh của mình. Đây có thể coi là 1 bước nhảy vượt bậc của Google trong lĩnh vực xử lý ngôn ngữ tự nhiên và mình cũng tự hỏi phải chăng đây cũng là 1 cú hích lớn để cải tiến các bài toán trong xử lí ngôn ngữ tự nhiên cho tiếng Việt.
Để hiểu sâu hơn về BERT bạn có thể đọc bài viết tiếp theo của mình tại bài Hiểu sâu về BERT hoặc nếu không muốn quá nhiều với lý thuyết bạn có thể thực hành ngay với BERT tại bài viết Thực hành với BERT: Áp dụng thế nào cho Tiếng Việt.
Hiện tại BERT đã được cài đặt trên Keras, Pytorch và bản gốc sử dụng Tensorflow.
Hy vọng bài viết này đã cho bạn cái nhìn khái quát nhất về BERT, biết được BERT là gì và để làm gì. Cảm ơn các bạn đã đọc bài.
Tổng hợp các tài liệu liên quan
All rights reserved
