
Sử dụng Tensorflow API cho bài toán Object Detection
Bài đăng này đã không được cập nhật trong 5 năm
Chào tất cả mọi người, hôm nay mình sẽ chia sẻ cách trainning model Object Detection đơn giản nhất sử dụng Tensorflow API.
Image classification sử dụng mạng CNN ngày nay khá dễ dàng, đặc biệt có sự hỗ trợ của Keras với TensorFlow back-end. Nhưng khi bạn muốn xác định nhiều hơn một đối tượng trong một hình ảnh thì sao?
Vấn đề này được gọi là “object localization and detection" . Bài toán này khó khăn hơn nhiều so với bài toán phân loại hình ảnh đơn giản.
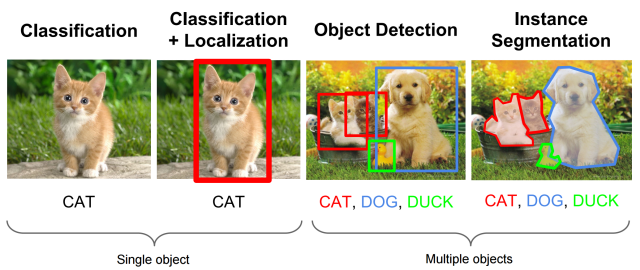 Hình 1: nguồn: CS231n Lecture 8 (2016)
Hình 1: nguồn: CS231n Lecture 8 (2016)
Object Detection
Bài toán Object Detection chắc sẽ không xa lạ với chúng ta, những người đã và đang quan tâm đến lĩnh vực này. Vậy Object Detection là gì? Object Detection là một kỹ thuật máy tính liên quan tới thị giác máy tính (computer vision) và xử lý ảnh liên quan đến việc phát hiện các trường hợp của các đối tượng ngữ nghĩa của một lớp nhất định (như: con người, đồ vật hay xe ô tô, ...) trong các hình ảnh hoặc video. Object Detection được áp dụng trong nhiều lĩnh vực của Computer Vision, bao gồm Image retrieval và video surveillance. Bài toán này đã được sử dụng rộng rãi để phát hiện khuôn mặt, phát hiện xe, đếm số người đi bộ, hệ thống bảo mật và xe không người lái.
Mọi thứ trông rất thú vị và bạn cảm thấy quá khó khăn trong việc code. Đừng lo, đã có TensorFlow API giúp bạn! Mọi công việc nặng nhọc khó khăn đã được thực hiện, việc của chúng ta là chuẩn bị data có cấu trúc giống với đầu vào yêu cầu.
TensorFlow cũng cung cấp pre-trained model, được trained trên bộ MS COCO, Kitti, hoặc tập dữ liệu Open Images.
 Hình 2: ví dụ về Object Detection sử dụng TensorFlow API
Nhưng, nếu bạn muốn detect vật gì mà không có trong danh sách các classs. Thì cùng theo dõi bài viết này nhé. Ở đây sẽ hướng dẫn cho các bạn tạo chương trình phát hiện đối tượng của riêng bạ, sử dụng một ví dụ thú vị của Quidditch từ vũ trụ Harry Potter!
Hình 2: ví dụ về Object Detection sử dụng TensorFlow API
Nhưng, nếu bạn muốn detect vật gì mà không có trong danh sách các classs. Thì cùng theo dõi bài viết này nhé. Ở đây sẽ hướng dẫn cho các bạn tạo chương trình phát hiện đối tượng của riêng bạ, sử dụng một ví dụ thú vị của Quidditch từ vũ trụ Harry Potter!
Bắt đầu nào!
Đầu tiên clone Repo Github này. Sử dụng cái này sẽ đơn giản hơn khi dùng Repo này của TensorFlow. Khi clone xong thì cùng cài đặt theo file requirements.txt:
pip install -r requirements.txt
API này sử dụng Protobufs để cấu hình và train các tham số mô hình. Chúng ta cần compile các thư viện Protobuf trước khi sử dụng:
sudo apt-get install protobuf-compiler
và
protoc object_detection/protos/*.proto --python_out=.
Sau đó nhớ copy đường dẫn vào nữa nha:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
Chuẩn bị dữ liệu đầu vào
Chúng ta cùng chuẩn bị file label_map.pbtxt. Trong file này chứa tất cả các tên của label mà mong muốn là đầu ra cũng như IB cho mỗi label. Chú ý rằng nên đánh ID cho mỗi label bắt đầu từ 1. Ví dụ nếu như 3 label của bạn là "snitch, quaffle và bludger" thì sẽ được đánh label như dưới đây nhé:
item { id: 1 name: 'snitch'}
item { id: 2 name: 'quaffle'}
item { id: 3 name: 'bludger'}
Nếu các bạn có tập data và các nhãn khác thì chỉ cần thay đổi ở file label_map.pbtxt là ok nhé. Ở đây tác giả sử dụng tập ảnh được lấy từ video phim Harry Potter dùng OpenCv để lấy các frame trong video này. Sau khi đã xong tác giả lấy ngẫu nhiên 300 bức ảnh được lấy ngẫu nhiên. Mình đã thử với dữ liệu để detect "head" và những cái khác head tuy nhiên vì máy mình hiện giờ đang sử dụng hơi gà nên mình dùng luôn tập data của tác giả nhé mn  .
.
Annotations
Tiếp theo đến bước Annotations nào:
Mỗi bức ảnh đều phải được annotate và lưu dưới dạng file XML với 4 tọa độ biểu diễn vị trí của khung bao quanh một đối tượng và label của nó. File XML được lưu theo cấu trúc như dưới đây hoặc bạn có thể tham khảo ở đây:
<annotation> <filename>182.jpg</filename> <size> <width>1280</width> <height>586</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>bludger</name> <bndbox> <xmin>581</xmin> <ymin>106</ymin> <xmax>618</xmax> <ymax>142</ymax> </bndbox> </object> <object> <name>quaffle</name> <bndbox> <xmin>127</xmin> <ymin>406</ymin> <xmax>239</xmax> <ymax>526</ymax> </bndbox> </object></annotation>
Mọi người có thể sử dụng LabelImg để annotate data đơn giản hơn nhé hoặc tham khảo các Tool annotations ở đây nhé.Nếu có khó khăn trong việc tạo file XML có thể ib cho mình nhé. Sau đó tạo file text có tên là trainval. File này có chứa tất cả tên ảnh/ tên file xml. Ví dụ: nếu bạn có img1.jpg, img2.jpg và img1.xml, img2.xml trong tập dữ liệu, thì file trainval.txt sẽ có dạng như sau:
img1img2
Chia dataset thành 2 folders: images và annotations. Annotation chứ file label_map.pbtxt, trainval.txt và folder xmls chứ các file XML. API chấp nhận đầu vào dạng TFRecords. Sau khi đã có dataset thì bắt đầu tạo file dựa theo fomart yêu cầu bằng cách sử dụng file create_tf_record.py trong repo theo dòng lệnh sau:
python create_tf_record.py \ --data_dir=`pwd` \ --output_dir=`pwd`
Chúng ta sẽ tạo được 2 files: train.record và val.record sau khi kết thúc dòng lệnh trên. Data được chia thành 70% cho tập train và 30% cho validation.
Training model
Đầu tiên chúng ta sẽ tải model pre-trained tại đây
 Hình: một số model pre-trained
Hình: một số model pre-trained
Ở đây mn nên sử dụng ssd_mobilenet_v1_coco nhé vì các version khác chưa được updated (nhắc trước không mất công fixed lỗi ) hoặc dùng Resnet như trong link gốc, tùy bài toán chúng ta sử dụng nhé.
Sau khi đã Download xong model bạn phải xác định được việc cần training ở file pipeline.config và đặt ở bên trong thư mục. (bạn chỉ cần thay thế từ các dòng dưới đây vào file config thôi nhé
gradient_clipping_by_norm: 10.0 fine_tune_checkpoint: "model.ckpt" from_detection_checkpoint: true num_steps: 200000}train_input_reader { label_map_path: "annotations/label_map.pbtxt" tf_record_input_reader { input_path: "train.record" }}eval_config { num_examples: 8000 max_evals: 10 use_moving_averages: false}eval_input_reader { label_map_path: "annotations/label_map.pbtxt" shuffle: false num_epochs: 1 num_readers: 1 tf_record_input_reader { input_path: "val.record" }}
Tiếp theo thực hiện dòng sau để training model
python object_detection/train.py \--logtostderr \--pipeline_config_path=pipeline.config \--train_dir=train
Exporting model
Ở đây bạn có thể sử dụng/export_inference_graph.py để export ra một model frozen graph
python object_detection/export_inference_graph.py \--input_type=image_tensor \--pipeline_config_path=pipeline.config \--trained_checkpoint_prefix=train/model.ckpt-xxxxx \--output_directory=output
Khi kết thúc dòng lệnh bạn sẽ thu được file frozen+inference_graph.pb. Tiếp theo chúng ta sẽ sử dụng file reference.py ở Github repo để test hoặc chạy module object detection.
python object_detection/inference.py \--input_dir={PATH} \--output_dir={PATH} \--label_map={PATH} \--frozen_graph={PATH} \--num_output_classes={NUM}
Chỉ cần thay thế đúng đường dẫn là okie nhé. Nếu thấy khó khăn khi dùng file Inference.py bạn có thể sử dụng đoạn code dưới đây để predict nhé.
import tensorflow as tf
import cv2
import numpy as np
import imutils
class Detector(object):
def __init__(self, base_path):
self.session = tf.Session()
saver = tf.train.import_meta_graph(base_path + '/output/' + "model.ckpt.meta")
saver.restore(self.session, base_path + '/output/' + "model.ckpt")
ops = self.session.graph.get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
self.tensor_dict = {}
for key in ['num_detections', 'detection_boxes', 'detection_scores', 'detection_classes']:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
self.tensor_dict[key] = self.session.graph.get_tensor_by_name(tensor_name)
self.image_tensor = self.session.graph.get_tensor_by_name('image_tensor:0')
def predict(self, image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
output_dict = self.session.run(self.tensor_dict, feed_dict={self.image_tensor: np.expand_dims(image, 0)})
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict['detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
bnbbox = output_dict['detection_boxes']
classes = output_dict['detection_classes']
scores = output_dict['detection_scores']
# print(scores)
# print(classes)
return scores, classes, bnbbox
def img_draw(img, index):
h, w, _ = img.shape
x1, y1, x2, y2 = int(bnbbox[index][1] * w), int(bnbbox[index][0] * h), int(bnbbox[index][3] * w), int(bnbbox[index][2] * h)
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
text_detector = Detector('/home/pham.hoang.anh/prj/cmnd_detect/text_annotated')
# index = 0
# for image in tqdm(images):
wraped = cv2.imread(image)
h, w, _ = wraped.shape
texted = wraped.copy()
scores, classes, bnbbox = text_detector.predict(wraped)
while scores[j] > 0.6:
img_draw(wraped, j)
cv2.imshow('image', wraped)
cv2.waitKey(0)
Hình ảnh thu được:

Results
Cuối cùng mình xin cảm ơn mọi người đã theo dõi bài viết của mình. Ở bài viết này mục đích giới thiệu cho mọi người cách sử dụng TensorFlow API cho bài toán này trở nên đơn giản hơn. Và mình cũng viết bài trên tư tưởng của bài viết gốc nếu có gì đó không đúng hoặc khó hiểu mong được mọi người góp ý.
Reference
All rights reserved
