Paper reading | ACTION-Net: Multipath Excitation for Action Recognition
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Trong các bài toán liên quan tới video, thông tin cần nắm bắt không chỉ là thông tin về mặt không gian (spatial information) giống như hình ảnh mà còn là thông tin về thời gian (temporal information) và sự phụ thuộc của chúng. Ví dụ, cho 2 video thực hiện hành động như sau, video 1 là video mà một người xoay nắm đấm cửa theo chiều kim đồng hồ, video 2 là video mà một người xoay nắm đấm cửa ngược chiều kim đồng hồ. Về mặt không gian, 2 video mang đặc trưng tương tự nhau, nhưng về mặt thời gian thì hoàn toàn ngược lại. Do đó, để thiết kế một mô hình hiệu quả cho việc training video thì bắt buộc cần phải mô hình phải biểu diễn được mối quan hệ của 2 loại thông tin này.
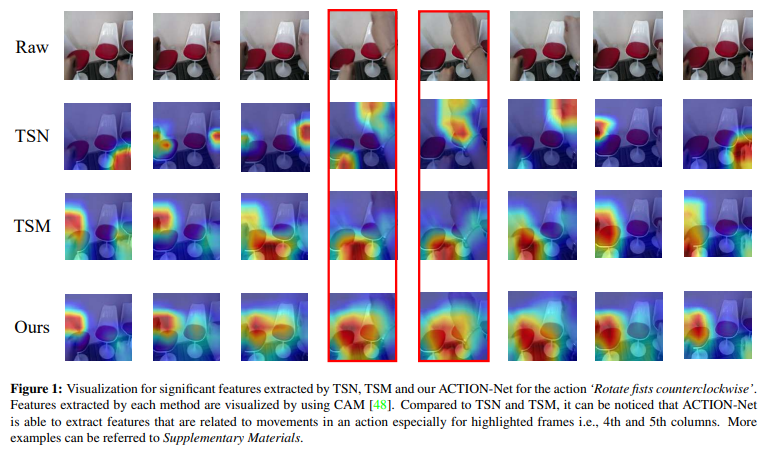
Các mô hình 3D CNN hiện tại mặc dù mô hình hóa được thông tin spatio-temporal nhưng vẫn mang một số nhược điểm sau:
- Thông tin spatio-temporal được capture không đầy đủ.
- Bổ sung thêm luồng optical flow làm tăng đáng kể hiệu suất nhưng tài nguyên tính toán sử dụng là lớn, tốc độ inference chậm nên sẽ ảnh hưởng khi sử dụng vào các ứng dụng thực tế.
Bài báo đề xuất một module giúp training video hiệu quả có tên là ACTION (spAtio-temporal, Channel and moTion excitatION) xử lý nhiều loại thông tin trong một mạng duy nhất. ACTION thực hiện mô hình hóa chuyển động dựa trên feature level thay vì tạo một loại input khác (ví dụ như optical flow) cho model. ACTION thực hiện trích xuất hiệu quả các thông tin: spatio-temporal pattern, channel-wise feature và thông tin chuyển động (motion information) dùng cho việc nhận dạng hành động (action recognition).
Phương pháp
Mô hình ACTION gồm có 3 module:
- Spatio-Temporal Excitation (STE)
- Channel Excitation (CE)
- Motion Excitation (ME)
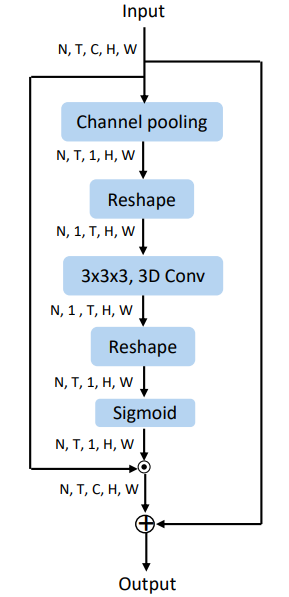
Spatio-Temporal Excitation (STE)
Module STE được thiết kế để capture thông tin spatio-temporal sử dụng 3D convolution. Sơ đồ của module được thể hiện trong hình dưới đây.
Cụ thể, cho đầu vào là , trong đó:
- là batch size
- là số frame trong một segment
- là channel
- là height
- là width
Đầu tiên, ta sẽ thực hiện tính trung bình input tensor theo chiều channel (đi qua channel pooling) để nhận một global spatio-temporal tensor . Sau đó ta sẽ reshape thành để đưa vào layer 3D convolutional với kernel size là , được công thức hóa như sau:
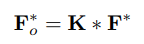
Sau đó, ta sẽ reshape quay trở lại thành shape cũ và đưa vào 1 hàm sigmoid để thu được mask được biểu diễn như sau:
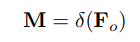
Output cuối cùng thu được như sau:
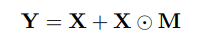
So với 3D convolution thông thường, STE thể hiện sự hiệu quả tính toán hơn do feature được tính trung bình theo chiều channel.
Channel Excitation (CE)
Module CE được thiết kế như hình dưới.
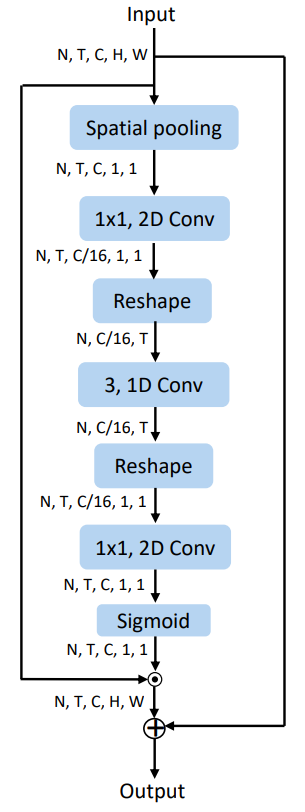
Cụ thể, cho input ta sẽ cho qua layer spatial average pooling như sau:
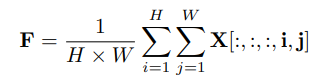
trong đó . Ta thực hiện giảm số channel của với một tỉ lệ như sau:
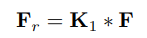
trong đó là layer 2D convolution và . Sau đó ta sẽ reshape thành . Sau đó ta thực hiện:
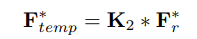
trong đó . là layer convolution với kernel size là 3.
Sau đó được reshape thành và được đi qua 2D convolutional layer . Cuối cùng output sẽ được đưa vào một hàm sigmoid. Công thức được mô tả như sau:
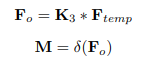
trong đó và .
Output cuối cùng được tính giống như output cuối cùng của module CE nhưng sử dụng mask khác 
Motion Excitation (ME)
Module ME được mô tả trong hình dưới:
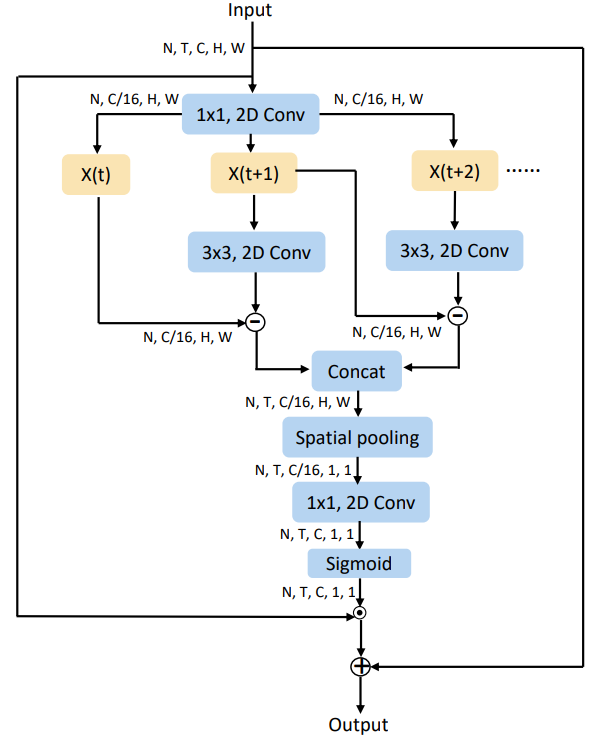
Thông tin chuyển động (motion information) được mô hình bởi các frame kề nhau (như trong hình trên). Ta thực hiện các chiến lược squeeze và unsqueeze như module CE. Cho feature được tạo sau khi thực hiện squeeze, motion feature được biểu diễn như sau
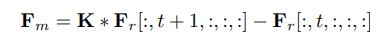
trong đó là 2D convolutional layer và .
Motion feature sau đó được concat với nhau theo chiều temporal và được pad 0 với phần tử cuối như sau: . được đưa qua spatial average pooling. Feature output và mask sẽ được tính giống như trong module CE.
ACTION-Net
Tổng quan của ACTION module được thể hiện trong hình dưới:
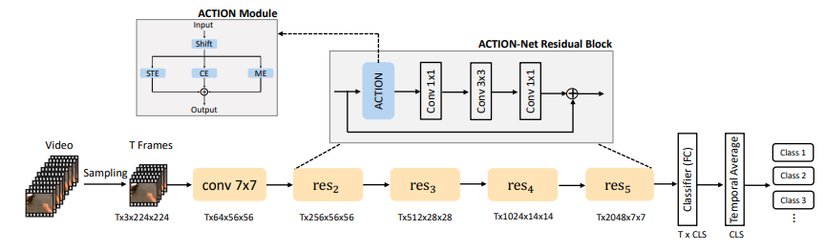
Nhận thấy rằng ACTION module nhận đầu vào là các output feature của 3 module ta đã tìm hiểu ở trên và thực hiện phép cộng element-wise. Bằng cách này, output của ACTION module sẽ có thông tin spatio-temporal, sự phụ thuộc giữa các channel và motion. Module ACTION trong hình trên được tích hợp vào kiến trúc ResNet-50.
Coding
Ta sẽ cài đặt module ACTION như sau:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import pdb
class Action(nn.Module):
def __init__(self, net, n_segment=3, shift_div=8):
super(Action, self).__init__()
self.net = net
self.n_segment = n_segment
self.in_channels = self.net.in_channels
self.out_channels = self.net.out_channels
self.kernel_size = self.net.kernel_size
self.stride = self.net.stride
self.padding = self.net.padding
self.reduced_channels = self.in_channels//16
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.fold = self.in_channels // shift_div
# shifting
self.action_shift = nn.Conv1d(
self.in_channels, self.in_channels,
kernel_size=3, padding=1, groups=self.in_channels,
bias=False)
self.action_shift.weight.requires_grad = True
self.action_shift.weight.data.zero_()
self.action_shift.weight.data[:self.fold, 0, 2] = 1 # shift left
self.action_shift.weight.data[self.fold: 2 * self.fold, 0, 0] = 1 # shift right
if 2*self.fold < self.in_channels:
self.action_shift.weight.data[2 * self.fold:, 0, 1] = 1 # fixed
# # spatial temporal excitation
self.action_p1_conv1 = nn.Conv3d(1, 1, kernel_size=(3, 3, 3),
stride=(1, 1 ,1), bias=False, padding=(1, 1, 1))
# # channel excitation
self.action_p2_squeeze = nn.Conv2d(self.in_channels, self.reduced_channels, kernel_size=(1, 1), stride=(1 ,1), bias=False, padding=(0, 0))
self.action_p2_conv1 = nn.Conv1d(self.reduced_channels, self.reduced_channels, kernel_size=3, stride=1, bias=False, padding=1,
groups=1)
self.action_p2_expand = nn.Conv2d(self.reduced_channels, self.in_channels, kernel_size=(1, 1), stride=(1 ,1), bias=False, padding=(0, 0))
# motion excitation
self.pad = (0,0,0,0,0,0,0,1)
self.action_p3_squeeze = nn.Conv2d(self.in_channels, self.reduced_channels, kernel_size=(1, 1), stride=(1 ,1), bias=False, padding=(0, 0))
self.action_p3_bn1 = nn.BatchNorm2d(self.reduced_channels)
self.action_p3_conv1 = nn.Conv2d(self.reduced_channels, self.reduced_channels, kernel_size=(3, 3),
stride=(1 ,1), bias=False, padding=(1, 1), groups=self.reduced_channels)
self.action_p3_expand = nn.Conv2d(self.reduced_channels, self.in_channels, kernel_size=(1, 1), stride=(1 ,1), bias=False, padding=(0, 0))
print('=> Using ACTION')
def forward(self, x):
nt, c, h, w = x.size()
n_batch = nt // self.n_segment
x_shift = x.view(n_batch, self.n_segment, c, h, w)
x_shift = x_shift.permute([0, 3, 4, 2, 1]) # (n_batch, h, w, c, n_segment)
x_shift = x_shift.contiguous().view(n_batch*h*w, c, self.n_segment)
x_shift = self.action_shift(x_shift) # (n_batch*h*w, c, n_segment)
x_shift = x_shift.view(n_batch, h, w, c, self.n_segment)
x_shift = x_shift.permute([0, 4, 3, 1, 2]) # (n_batch, n_segment, c, h, w)
x_shift = x_shift.contiguous().view(nt, c, h, w)
# 3D convolution: c*T*h*w, spatial temporal excitation
nt, c, h, w = x_shift.size()
x_p1 = x_shift.view(n_batch, self.n_segment, c, h, w).transpose(2,1).contiguous()
x_p1 = x_p1.mean(1, keepdim=True)
x_p1 = self.action_p1_conv1(x_p1)
x_p1 = x_p1.transpose(2,1).contiguous().view(nt, 1, h, w)
x_p1 = self.sigmoid(x_p1)
x_p1 = x_shift * x_p1 + x_shift
# 2D convolution: c*T*1*1, channel excitation
x_p2 = self.avg_pool(x_shift)
x_p2 = self.action_p2_squeeze(x_p2)
nt, c, h, w = x_p2.size()
x_p2 = x_p2.view(n_batch, self.n_segment, c, 1, 1).squeeze(-1).squeeze(-1).transpose(2,1).contiguous()
x_p2 = self.action_p2_conv1(x_p2)
x_p2 = self.relu(x_p2)
x_p2 = x_p2.transpose(2,1).contiguous().view(-1, c, 1, 1)
x_p2 = self.action_p2_expand(x_p2)
x_p2 = self.sigmoid(x_p2)
x_p2 = x_shift * x_p2 + x_shift
# # 2D convolution: motion excitation
x3 = self.action_p3_squeeze(x_shift)
x3 = self.action_p3_bn1(x3)
nt, c, h, w = x3.size()
x3_plus0, _ = x3.view(n_batch, self.n_segment, c, h, w).split([self.n_segment-1, 1], dim=1)
x3_plus1 = self.action_p3_conv1(x3)
_ , x3_plus1 = x3_plus1.view(n_batch, self.n_segment, c, h, w).split([1, self.n_segment-1], dim=1)
x_p3 = x3_plus1 - x3_plus0
x_p3 = F.pad(x_p3, self.pad, mode="constant", value=0)
x_p3 = self.avg_pool(x_p3.view(nt, c, h, w))
x_p3 = self.action_p3_expand(x_p3)
x_p3 = self.sigmoid(x_p3)
x_p3 = x_shift * x_p3 + x_shift
out = self.net(x_p1 + x_p2 + x_p3)
return out
Thực nghiệm
ACTION-Net luôn vượt trội so với các model 2D trên ba bộ dữ liệu đại diện. Tất cả các phương pháp đều sử dụng ResNet-50 là backbone và 8 frame input để so sánh được công bằng hơn.
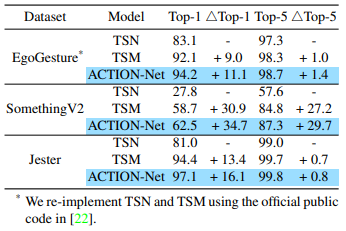
So sánh các model SOTA trên tập dữ liệu Something-Something V2.
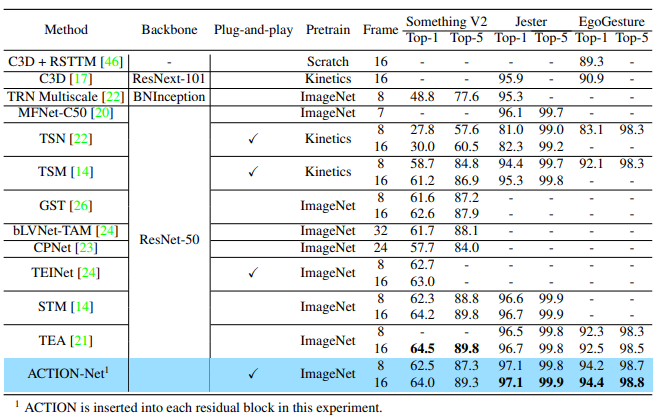
Độ chính xác và độ phức tạp của mô hình trên bộ dữ liệu EgoGesture. Ba module STE, CE, ME được so sánh với TSM và TSN. Tất cả các phương pháp đều sử dụng ResNet-50 làm backbone và input gồm 8 frame để đảm bảo sự so sánh công bằng. So sánh FLOPs/ΔFLOPs/Param được thể hiện trong bảng sau:
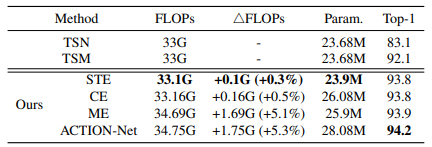
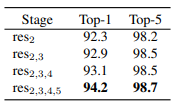
Nghiên cứu về việc sử dụng ACTION trong các block của Resnet-50.
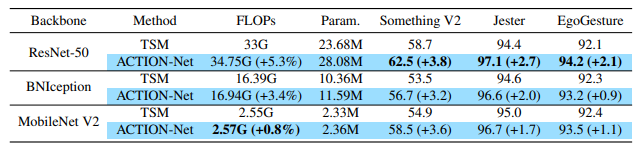
ACTION thể hiện khả năng tổng quát hóa tốt với các backbone và dataset khác nhau.
Tài liệu tham khảo
[1] ACTION-Net: Multipath Excitation for Action Recognition
[2] https://github.com/V-Sense/ACTION-Net
[3] Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
All rights reserved
