
[Paper Explained] Boostrapping Semantic Segmentation with Regional Contrast (ReCo)
Bài đăng này đã không được cập nhật trong 3 năm
1. Giới thiệu
ReCo (Regional Contrast) là một pixel-level Contrastive framework định nghĩa một làm loss mới giúp cho semantic segmentation không những học từ local context (những pixel lân cận) mà còn học từ global context từ toàn bộ dataset (semantic class relationships). Reco được sử dụng để hỗ trợ cả học giám sát và học không giám sát. Với mỗi class xuất hiện trong 1 mini-batch, ReCo sẽ lấy ra một tập pixel-level representations (queries), và thực hiện kéo chúng gần với trung bình representations của class đó (positive keys) đồng thời đẩy representations của những class khác (negative keys) ra xa.
Đối với pixel-level contrastive learning với ảnh độ phân giải cao thường lấy ra toàn bộ pixel. Với ReCo, một tập thưa số lượng pixel được lấy ra (nhỏ hơn 5%) để làm queries và keys. Negative keys được chọn ra từ phân phối được học dựa trên khoảng cách giữa từng query class với mỗi negative key class. Những query cũng được chọn từ những pixel có độ confidence thấp từ đó ReCo có thể tập chung hơn vào những pixel đang bị confuse.
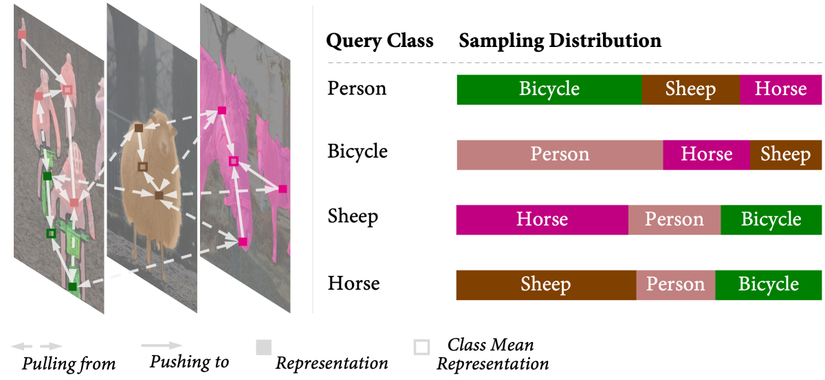 ReCo sẽ cố gắng đẩy representations của 1 class gần với trung bình representation của class đó, đồng thời đẩy representations đó ra xa representations lấy từ những negative class khác. Phân phối của negative class sẽ được adaptive theo mỗi query class. Ví dụ, vì class bicycle và class person có độ tương đồng cao, ReCo sẽ lấy nhiều representation của class bicycle nhiều hơn khi học class person.
ReCo sẽ cố gắng đẩy representations của 1 class gần với trung bình representation của class đó, đồng thời đẩy representations đó ra xa representations lấy từ những negative class khác. Phân phối của negative class sẽ được adaptive theo mỗi query class. Ví dụ, vì class bicycle và class person có độ tương đồng cao, ReCo sẽ lấy nhiều representation của class bicycle nhiều hơn khi học class person.
2. ReCo trong semantic segmentation
Không giống như các contrastive framworks khác như MoCo hay SimCLR, ReCo loss được tính trên pixel representation thay vì global representation. Trong bài toán segmantic segmentation mỗi ảnh thường có cả ngàn hay có thể lên tới trăm ngàn pixel nên việc tính contrastive loss trên từng pixel là không khả thi. Vì vậy mà ReCo sẽ sample một số lượng rất nhỏ hard pixel và sẽ không làm tăng memory quá nhiều. Cũng giống như các contrastive framworks khác, ReCo cũng cần định nghĩa ra query: pixel-level representation của sample. Positive keys: representation tương tự với query; Negative keys : representation khác với query. ReCo định nghĩa chiến thuật sampling mới cho query và negative keys.
Active Query Sampling
Tại mỗi sample query, ReCo sử dụng một predefined threshold và tất cả pixel nhỏ hơn threshhold sẽ được chọn. Bằng cách này thì những query pixel được chọn thường là những object nhỏ hoặc là cạnh của object.

Active Key Sampling
Thông thường mỗi class chỉ bị confused với một vài class khác (ví dụ people vs bicycles, buses vs trains). Tuy nhiên ta không thể học ra những confused classes một cách tự động bởi vì confused classes có thể sẽ khác ở những training stages khác nhau và sự thiên lệch của model cũng khác so với sự thiên lệch của con người. Vì vậy khoảng cách tương đối giữa từng query class với class khác được sử dụng để sample ra negative keys.
ReCo chỉ xét những class mà nó xuất hiện trong mini-batch hiện tại. Với mỗi class khác xuất hiện trong mini-batch, trung bình representation của class đó sẽ được sử dụng để tính khoảng cách tương đối. Nếu khoảng cách nhỏ, thì ta coi class đó đang bị confused với query class hiện tại và ngược lại. Từ khoảng cách vừa tính được ta sẽ tạo ra một phân phối và từ phân phối đó sẽ lấy mẫu ra negative keys.
Với chiến thuật sampling này thì ReCo chỉ cần thực hiện tính contrastive loss trên một lượng nhỏ hơn 5% pixel và không làm tăng memory quá lớn.
3. Experiments & Visualisations
Trước kia, Semi-supervised learning thường được áp dụng cho bài toán image classification. Cụ thể hơn, FixMatch và MixMatch có thể đạt được độ chính xác rất cao khi chỉ sử dụng 10 ground-truth images cho mỗi class (thậm chí là 1 ảnh). Tuy nhiên, semi-supervised semantic segmentation vẫn chưa có cách đánh giá chính thức nào. ReCo cũng đưa ra 2 phương thức benchmark cho bài toán semi-supervised segmentation hướng tới 2 hướng ứng dụng khác nhau.
Partial Dataset Full Labels: Mô hình sẽ được huấn luyện với một tập con ảnh với full ground-truth labels (labeled set), và phần còn lại là unlabelled. Tập dữ liệu có nhãn (labeled set) phải thỏa mãn 2 điều kiện: 1) Mỗi ảnh được sample phải chứa một số lượng class nhất định (số class được định nghĩa trước). 2) Mỗi ảnh được sample phải chứa một trong những class được sample ít nhất ở lần sample trước đó. Điều này giúp cho việc evaluate trên một lượng sample nhỏ mà không cần lo lắng rằng một số class ít xuất hiện sẽ không được evaluate.
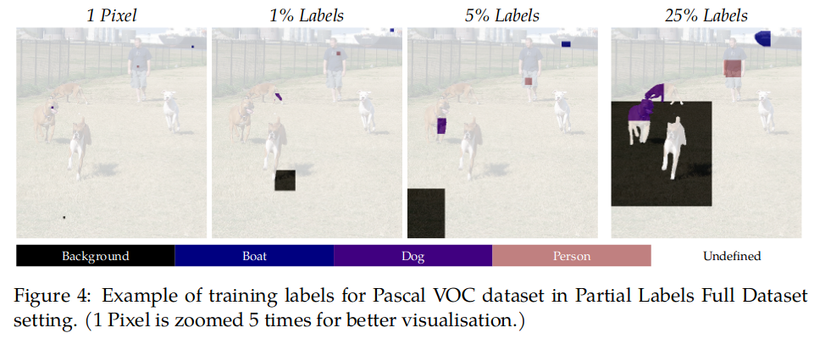
Partial Labels Full Dataset: Giống như fully-supervised, toàn hộ ảnh sẽ được chọn nhưng mỗi ảnh sẽ chỉ có một lượng pixels nhất định có nhãn cho mỗi class.
Kết quả trên Partial Dataset Full Labels benchmark
ReCo sẽ được so sánh với 3 phương pháp semi-supervise khác là: CutOut, CutMix và ClassMix, ReCo sẽ được áp dụng cùng với ClassMix.
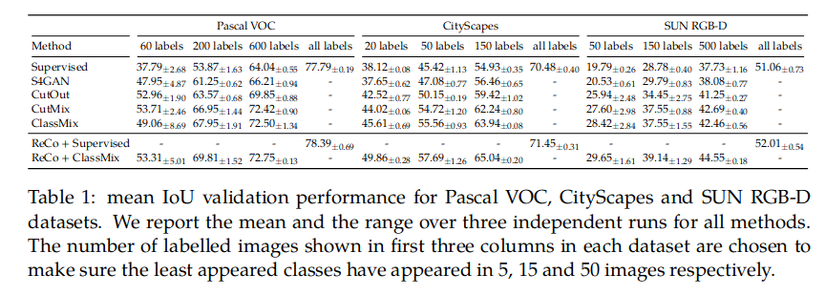 Với những cài đặt sử dụng ít label khi áp dụng ReCo cùng với ClassMix đã cải thiện từ 5-10% mIOU
Với những cài đặt sử dụng ít label khi áp dụng ReCo cùng với ClassMix đã cải thiện từ 5-10% mIOU
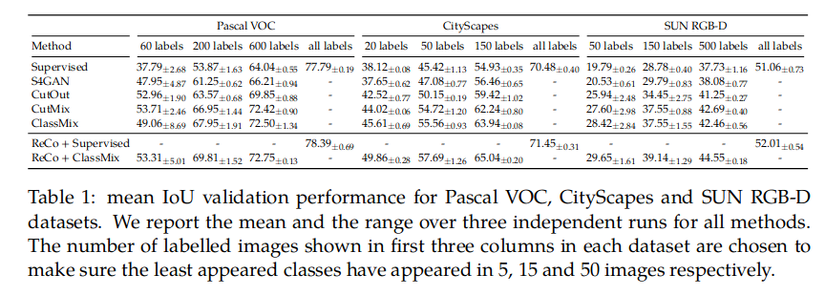
Kết quả trên Full Dataset Partial Labels benchmark
Reco được so sánh với CutMix và ClassMix
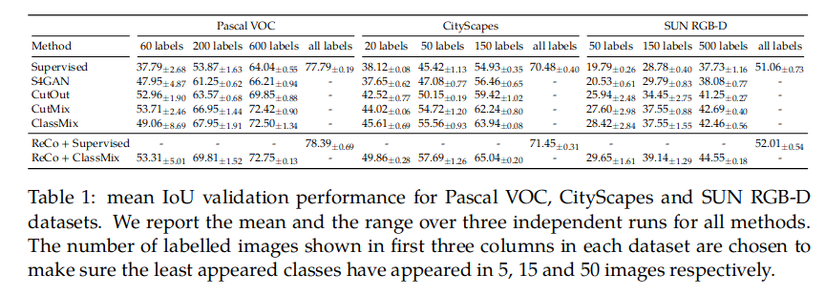 ReCo imporve khoảng 1-5% không được như benchmark full label.
ReCo imporve khoảng 1-5% không được như benchmark full label.

4. References
- Bootstrapping Semantic Segmentation with Regional Contrast (https://arxiv.org/abs/2104.04465)
- Regional Contrast (https://shikun.io/projects/regional-contrast)
- Liu Shikun blogs (https://zhuanlan.zhihu.com/p/364651534)
All rights reserved
