[Tháng mới paper mới] Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning
Bài đăng này đã không được cập nhật trong 4 năm
Không riêng gì môi trường học thuật, việc đọc và tìm hiểu các báo cáo nghiên cứu đã được công bố hay thường được gọi tắt là paper là một công việc hết sức quan trọng, nhất là khi bạn cần hiểu sau về một phương pháp hoặc lĩnh vực nào đó. Tuy vậy, đối với mỗi chúng ta, việc tìm đọc các paper có chất lượng tốt cũng như có mức độ liên quan nhất định đến công việc cũng như thiên hướng nghiên cứu của bản thân trong hàng ngàn công trình nghiên cứu được công bố hàng ngày cũng không phải là công việc dễ dàng gì. Bài viết này giới thiệu về paper Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning được đề xuất trong bài viết Four Deep Learning Papers to Read in September 2021 cũng như trình bày một cách ngắn gọn nhất các nội dung được trình bày trong các paper đó. Hi vọng rằng bài viết này sẽ cung cấp cho các bạn các thông tin hữu ích để phát triển hướng nghiên cứu của mình.
Tác giả: Matthias Feurer, Katharina Eggensperger , Stefan Falkner, Marius Lindauer, Frank Hutter
Source code: GitHub - automl/auto-sklearn: Automated Machine Learning with scikit-learn
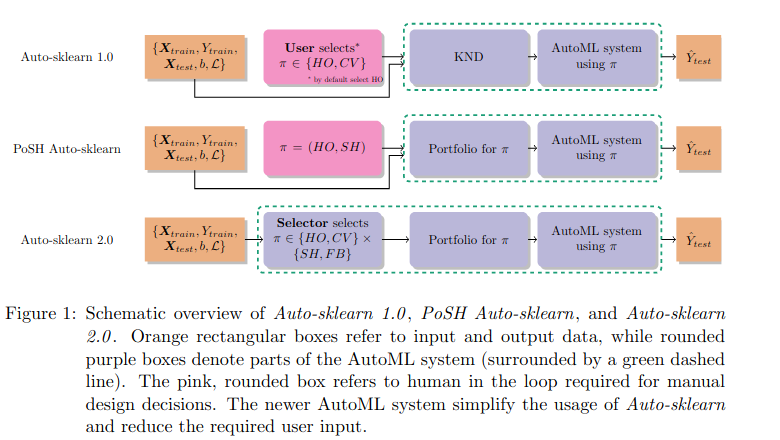
Giới thiệu chung
Nhắc đến Scikit-learn, chúng ta đều phải công nhận rằng, đây là một trong những thư viện mạnh mẽ nhất và được sử dụng rộng rãi để xử lý lý các tác vụ liên quan đến các thuật toán học máy. Tuy vậy, có một sự thật rằng, việc điều chỉnh thủ công các siêu tham số cũng như lựa chọn mô hình khi sử dụng thư viện có thể nói rằng vo cùng tẻ nhạt. Để giải quyết vấn đề này, các phương pháp dựa trên AutoML (Automated Machine Learning - Học máy tự động hóa) đã xuất hiện và thường được sử dụng để hỗ trợ các học viên và nhà nghiên cứu nhằm thực hiện nhiệm vụ tẻ nhạt là thiết kế pipeline học máy và đã đạt được thành tựu đáng kể trong thời gian gần đây.
Phát biểu vấn đề
Gọi là một phân phối của các tập dữ liệu mà từ đó chúng ta có thể lấy mẫu phân phối của một tập dữ liệu riêng lẻ . Vấn đề AutoML mà ta đang xem xét là tạo ra mộ tpipeline được huấn luyện , được siêu tham số hóa bởi , tự động tạo ra các dự đoán cho các mẫu từ phân phối và cực tiểu hóa sai số tổng quát dự kiến:
Vì một tập dữ liệu chỉ có thể được quan sát thông qua một tập gồm n quan sát độc lập nên , chúng ta chỉ có thể ước lượng gần đúng theo kinh nghiệm của sai số tổng quát hóa trên dữ liệu mẫu:
Trong thực tế, ta thường sẽ chỉ có thể sử dụng hai mẫu hữu hạn, rời rạc mà có thể ký hiệu là và ( và trong trường hợp ta tham chiếu một tập dữ liệu cụ thể được rút ra từ ). Để tìm kiếm pipeline ML tốt nhất, ta thường chỉ sử dụng tập để huấn luyện và hiệu suất cuối cùng được ước tính trên .
Để thực hiện điều đó, các hệ thống AutoML thường sử dụng để tự động tìm kiếm tốt nhất:
và ước tính , ví dụ: bằng xác thực chéo a K-fold :
trong đó biểu thị rằng được huấn luyện trên phần tách huấn luyện của tập thứ k là tập con của , và sau đó nó được đánh giá trên phần tách xác thực của lần thứ k là tập con của . Giả sử rằng, thông qua λ, một hệ thống AutoML có thể chọn cả hai, một thuật toán và cài đặt siêu tham số của nó, định nghĩa này sử dụng tương đương với định nghĩa của bài toán CASH (LC ombined Algorithm Selection and H yperparameter optimization)
AutoML với thời gian giới hạn
Trong thực tế, người dùng không chỉ quan tâm đến việc cuối cùng có được một pipeline tối ưu , mà còn bị ràng buộc về thời gian và tài nguyên tính toán mà họ sẵn sàng đầu tư. Ta có thể biểu thị thời gian cần thiết để đánh giá là và ngân sách tối ưu hóa tổng thể bằng T. Mục tiêu của ta là tìm
trong đó tổng trên tất cả các pipeline được đánh giá , thể hiện rõ ràng ngân sách tối ưu hóa T.
AutoML tổng quan hóa
Cuối cùng, hệ thống AutoML cần không chỉ hoạt động tốt trên một tập dữ liệu đơn lẻ mà trên toàn bộ phân phối trên tập dữ liệu . Do đó, vấn đề meta của AutoML có thể được tổng quan hóa thành việc giảm thiểu lỗi tổng quát hóa đối với phân phối tập dữ liệu:
thứ mà với mỗi lượt, nó chỉ có thể được ước lượng một lần nữa bởi một tập hợp hữu hạn các tập dữ liệu meta-train (mỗi tập có một tập hợp các quan sát hữu hạn):
Bằng cách phát biểu như trên, nhóm tác giả đã cố gắng làm rõ mục tiêu mà mình hướng tới và để giải quyết các vấn đề được lựa chọn, thay vì sử dụng một hệ thống AutoML A cố định duy nhất, nhóm tác giả sẽ giới thiệu các chính sách tối ưu hóa , là sự kết hợp của các siêu tham số của hệ thống AutoML và các thành phần cụ thể sẽ được sử dụng trong một lần chạy, có thể được sử dụng để định cấu hình hệ thống AutoML cho các trường hợp sử dụng cụ thể.
Ngoài ra, thay vì chọn giữa nhiều chính sách của một hệ thống AutoML, phương pháp được trình bày có thể được áp dụng để chọn giữa các AutoML khác nhau mà không cần điều chỉnh. Tuy nhiên, hướng tiếp cận của nhóm tác giả là cải thiện các hệ thống AutoML đơn lẻ để làm cho chúng dễ sử dụng hơn thay vì tối đa hóa hiệu suất bằng cách gọi nhiều hệ thống AutoML, do đó cách giải quyết được đưa ra có thể sẽ làm tăng độ phức tạp.
Phương pháp giải quyết
Để thực hiện mục tiêu của mình, Auto-Sklearn 2.0 giới thiệu 2 sửa đổi như sau:
- Thay vì sử dụng các meta-features, họ đề xuất sử dụng các meta-learned portfolio trong pipeline khởi đầu. Các portfolio ứng cử viên sẽ được đánh giá để khởi động vòng lặp bên trong Tối ưu hóa Bayes
- Thứ hai, họ giới thiệu một công cụ chọn chính sách được học qua kiến thức tổng hợp, quy định chiến lược lựa chọn mô hình (ví dụ: xác thực chéo so với đánh giá giữ lại đơn giản) và chiến lược phân bổ ngân sách (ngân sách đầy đủ so với giảm một nửa liên tiếp tích cực hơn) dựa trên số lượng mẫu và tính năng trong tập dữ liệu được xem xét.
Từ việc thực hiện các sửa đổi đã được đề xuất đó, các cải tiến được nhóm tác giả liệt kê cụ thể như sau:
Cải tiến chiến lược lựa chọn mô hình
Có thể thấy rằng, việc tìm kiếm một mô hình hoạt động tốt phụ thuộc vào không gian của các mô hình được xem xét để tìm kiếm, nhưng mặt khác, việc sử dụng một chiến lược tốt cũng rất quan trọng để quyết định mô hình nào là tốt nhất. Trong quá trình tối ưu hóa, nhóm tác giả đánh giá nhiều pipeline ML nhằm giảm thiểu lỗi tổng quát hóa. Điều này đi kèm với hai thách thức:
- Cách tính gần đúng sai số tổng quát
- Làm thế nào để phân bổ các nguồn lực sẵn có trên tất cả các đánh giá.
Thách thức đầu tiên thường được tiếp cận bằng cách sử dụng xác thực chéo, nhưng điều này có thể không phải lúc nào cũng khả thi (hoặc thậm chí là mong muốn) vì vậy chiến lược holdout đơn giản sẽ thích hợp hơn. Thách thức thứ hai có thể được giải quyết bằng những tiến bộ gần đây trong tối ưu hóa đa độ trung thực, nhưng một lần nữa nó vẫn phụ thuộc vào tập dữ liệu hiện có và nguồn lực của nhóm tác giả.
Xây dựng các bộ profolio
Meta-learning luôn là một ý tưởng hay để tăng tốc độ tối ưu hóa và hóa ra lại là một thành phần quan trọng giúp Auto-sklearn 2.0 chiến thắng các thử thách AutoML. Thay vì sử dụng các meta-features, họ đề xuất sử dụng các meta-learned portfThay vì sử dụng các meta-features, họ đề xuất sử dụng các meta-learned portfolio trong pipeline khởi đầu. Các portfolio ứng cử viên sẽ được đánh giá để khởi động vòng lặp bên trong Tối ưu hóa Bayesolio trong pipeline khởi đầu. Các portfolio ứng cử viên sẽ được đánh giá để khởi động vòng lặp bên trong Tối ưu hóa Bayes.
Lựa chọn chính sách tự động
Khác với 2 cải tiến trên khi nhóm tác giả chỉ bổ sung tính linh hoạt và các tính năng để đáp ứng một số lượng lớn các trường hợp sử dụng nhưng vẫn yêu cầu người dùng phải cấu hình hệ thống AutoML, nhóm tác giả cũng đã tự động hóa auto-sklearn ở cấp độ này bằng cách chọn chiến lược lựa chọn mô hình tốt nhất cho tập dữ liệu mới dựa trên dữ liệu đã thấy trước đó.
Kết quả thu được
Kết quả thử nghiệm với AutoML benchmark được nhóm tác giả cung cấp trong bảng dưới đây. Đối với mỗi tập dữ liệu,nhóm tác giả cung cấp hiệu suất trung bình của hệ thống AutoML với 10-folds và 5-folds cũng như tô đậm phần có lỗi thấp nhất. Kết quả trong đó cho thấy rằng không có hệ thống AutoML nào là tốt nhất trên tất cả các tập dữ liệu và ngay cả TunedRF cũng hoạt động tốt nhất trên một số tập dữ liệu.
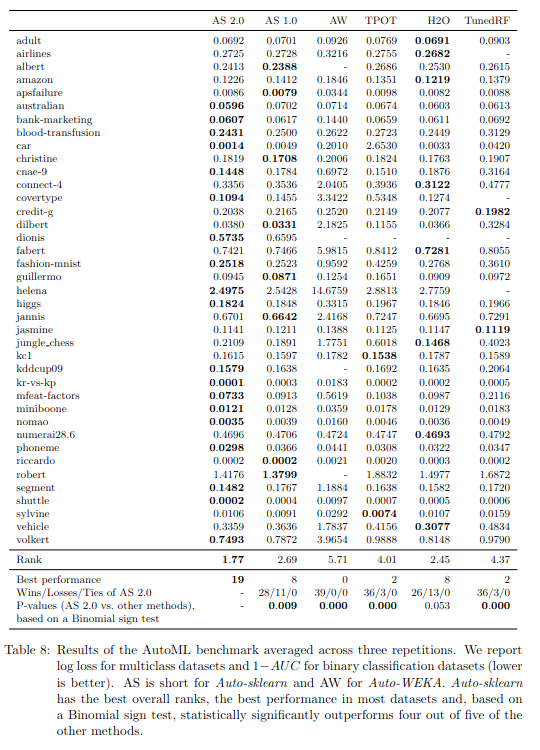
Tuy nhiên, chúng ta cũng có thể thấy rằng Auto-sklearn 2.0 được đề xuất có thứ hạng trung bình thấp nhất. Tiếp theo là H2O AutoML và Auto-sklearn 1.0 thực hiện gần như ngang bằng với điểm xếp hạng và số lần họ là người chiến thắng trên tập dữ liệu. Theo cả hai chỉ số tổng hợp, TunedRF, Auto-WEKA và TPOTđều bị bỏ lại khá xa trong khi cả hai phiên bản của Auto-sklearn dường như khá mạnh mẽ vì chúng cung cấp kết quả một cách đáng tin cậy trên tất cả các tập dữ liệu, bao gồm cả những tập dữ liệu lớn nhất mà một số phương pháp khác không thành công
Tổng kết
Bài viết này giới thiệu về paper Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning cũng như trình bày một cách ngắn gọn nhất các nội dung được trình bày trong các paper đó. Cảm ơn các bạn đã dành thời gian đọc và hi vọng rằng bài viết này sẽ cung cấp cho các bạn các thông tin hữu ích cho mọi người.
All rights reserved
