
[Paper Explain]Sinh ảnh cùng với MixNMatch: độ chân thực đến đáng gờm
Bài đăng này đã không được cập nhật trong 3 năm
Tổng quan

Dạo một vòng mấy trang chia sẻ kiên thức để chống lười, đập vào mắt mình một bài viết với tiêu đề khá giật tít, mà kiểu nó sẽ áp dụng được trong rất nhiều bài toán. Vì vậy mạn phép đọc bài viết của tác giả sau đó dịch theo ý hiểu để diễn giải cho mọi người cùng thảo luận (Chứ cái này mình không có tự nghĩ ra :v) Bài viết giới thiệu về 1 kỹ thuật mang tên MixNMatch có nguồn gốc từ 1 paper có tên MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation (https://arxiv.org/pdf/1911.11758.pdf ). Vậy nó có gì đặc biệt và có tính ứng dụng cao như vậy, cùng mình tìm hiểu nhé
MixNMatch là một kỹ thuật có khả năng kết hợp những phần khác nhau của nhiều bức ảnh thực để sinh ra một bức ảnh tổng hợp, sẽ mang các đặc trưng mà ta đưa vào. Nhìn vào bức ảnh trên, bức ảnh gen ra sẽ có những đặc trưng như sau: nền như bức ảnh đầu tiên, ngữ nghĩa (con chim) của bức ảnh 2, kích thước của bức ảnh 3 và vị trí của bức ảnh 4. Thật chứ nhìn đến đấy thôi là mình đã phải tò mò đọc tiếp và muốn viết một bài về cái này rồi
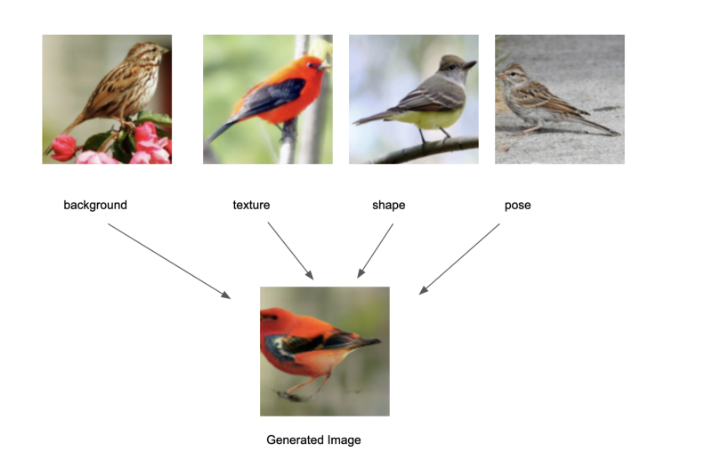
Nhắc tới sinh dữ liệu, chắc hẳn nhiều người nghĩ ngay tới GAN, mình cũng thế :v và nó đúng là như vậy thật. MixNMatch là một kỹ thuật sinh ảnh có điều kiện sử dụng Generative Adversarial Network (GAN). Theo bài báo, MixNMatch chỉ cần 1 bounding box quanh đối tượng nền chứ không cần hộp cho tư thế, hình dạng, kết cấu của đối tượng (Nghe hơi vô lý nhưng đọc tiếp xem sao).
Gét gô!
Ý tưởng chính
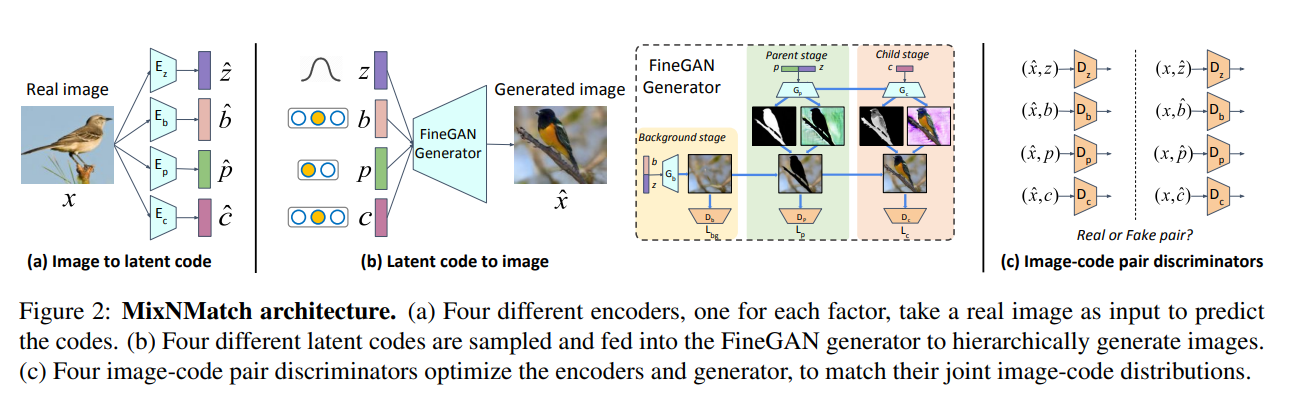
Như đã đề cập, sẽ có sự xuất hiện của GAN ở đây. MixNMatch học cách tách rời các phần và mã hóa (encode) nền (background), tư thế đối tượng (pose), hình dạng (shape) và kết cấu (texture) khỏi các bức ảnh thực với mức giám sát ít nhất (ý mình hiểu giám sát ít nhất ở đây tức là chúng ta có dùng ít dữ liệu có nhãn nhất có thể). Để đạt được đièu này, tác giả của paper đề xuất một khuôn khổ cho phép đồng thời học 1 bộ mã hóa (Encoder) các yếu tố tiềm ẩn từ hình ảnh thực thành một không gian mã tiềm ẩn không được xáo trộn và một trình sinh (Generator) để lấy các yếu tố tiềm ẩn từ không gian mã bị xáo trộn để tạo hình ảnh
- Bức ảnh đầu vào sẽ được đưa quan Encoder để tạo ra các latent codes. ở đây sẽ có 4 latent codes khác nhau, tương ứng là background, pose, shape, texture.
- 4 latent codes khác nhau sẽ được đưa vào FineGAN generator để sinh ra ảnh
FineGAN
MixNMatch dựa trên FineGAN, vậy ta cùng xem qua cách FineGAN hoạt động
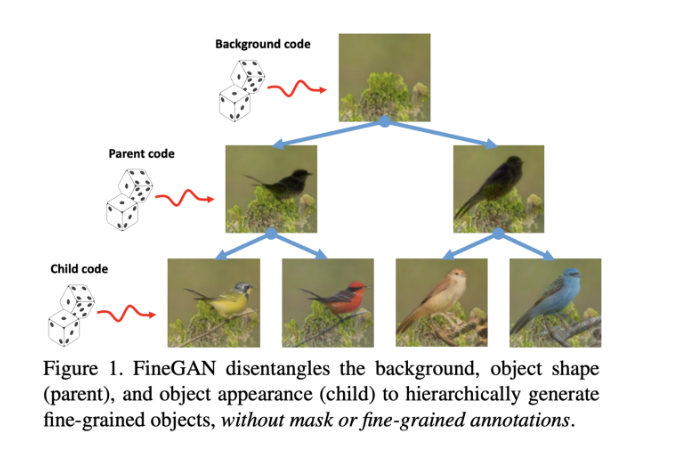
Như đã nói ở trên, input của FineGAN sẽ bao gồm 4 đặc trưng ngẫu nhiên khác loại nhau (ở đây là 4 latent code), gọi là (x, b, c, p). Cách hoạt động của FineGAN sẽ gồm 3 khối
- Background stage: Ở giai đoạn này, mô hình chỉ sinh ra nền, được điều chỉnh dựa trên latent one-hot background code b (chính là latent code của background)
- Parent stage:giai đoạn chính trong đó mô hình tạo ra hình dạng (shape) và tạo dáng (pose) của đối tượng dựa trên latent one-hot parent code p và z, và ghép nó vào background đang có
- Child stage:giai đoạn con, mô hình lấp đầy kết cấu của đối tượng (texture), được điều chỉnh dựa trên latent one-hot child code
Ở cả giải đoạn parent và child, FineGAN đều tạo ra mặt nạ của đối tượng để ghi lại hình dạng và kết cấu mà không cần giám sát
Trong quá trình training, FineGAN thực hiện với 2 ràng buộc
- Nhóm các mã con (child codes) thành 1 tập hợp rời rạc để mỗi tập hợp chứa cùng 1 mã cha (parent code). Ràng buộc này ràng buộc rằng các spices of ducks (gia vị của vịt???) khác nhau sẽ có hình dạng giống nhau nhưng kết cấu khác nhau
- Đối với mỗi hình ảnh được tạo ra, cặp mã con (child code) và mã nền (background code) luôn giống nhau, ngĩa là một con vịt sẽ luôn có nền là nước
Để tách nền, FIneGAN dựa vào hộp giới hạn của đối tượng (object’s bounding box)
Để gỡ rối các yếu tố khác, FineGAN dựa trên lý thuyết thông tin như trong InfoGAN (Phần này do chưa có nhiều thời gian nên mình chưa đọc) và áp đặt các ràng buộc giữa mối quan hệ của các latent code.
Tuy nhiên FineGAN chỉ được điều chỉnh dựa trên các latent code được lấy mẫu, và không thể điều chỉnh trực tiếp trên hình ảnh thực tế để tạo ảnh. Do đó tác giả đề xuất một cách để trích xuất các latent codes kiểm soát nền, tư thế, hình dạng, kết cấu từ hỉnh ảnh thực, trong khi vẫn bảo toàn các thuộc tính phân chia thứ bậc của FineGAN. Có 2 cách tiếp cận
- Phần mở rộng của FineGAN: ý nghĩa là đọa tạo 1 bộ mã hóa để ảnh xạ 1 hình ảnh giả mạo sang latent code. Tuy nhiên điều này theo tác giả là không hoạt động vì khoảng cách miền giữa hình ảnh thật và giả
- Thực hiện học đối nghịch, theo đó phân phối chung của hình ảnh thực và latent code tương ứng của chúng, cùng với phân phối chung giữa latent code và hình ảnh được tạo tương ứng từ generator được học sao cho khong thể phân biệt được, từ đó ảnh sinh ra sẽ gần với ảnh thật hơn (Cùng nghĩ lại kiến thức về mạng GAN với bài toán kinh điển: Generator cố gắng in ra tiền giả còn Discriminator cố gắng phân biệt tiền giả, song mục tiêu của chúng ta là tiền giả giống thật để Discriminator không nhận ra)
Ưu điểm của phương pháp học đối nghịch ở đây là gì
- Bằng cách thực thi các phân phối mã hình ảnh phù hợp, trình Encoder học cách tạo ra các latent code phù hợp với việc phân phối các sampled codes với các thuộc tính tách rời mong muốn, trong khi trình Generator cố gắng tạo ra hình ảnh thực tế
- Cụ thể, với mỗi hình ảnh thực đầu vào x, tác giả đề xuất 4 bộ mã riêng biệt để trích xuất: z, b, p ,c. Tuy nhiên nhưng mã này sẽ không đặt trực tiếp vào Generator để tái tạo ảnh (Điều này quá đơn thuần và thủ công). Tác giá tận dụng các ý tưởng từ ALI và BiGAN để giúp các bộ mã hóa tìm hiểu ảnh xạ nghịch đảo, tức là 1 phép chiếu từ hình ảnh thực vào không gian mã, theo cách duy trì các thuộc tính tách rời mong muốn
Tổng kết
Bài báo này để tìm hiểu sâu cũng như code thì cũng mất tương đối nhiều thời gian, vì vậy trong phạm vi bài viết này mình chỉ giới thiệu về ý tưởng chung của bài báo bởi tính ứng dụng của nó là vô cùng cao, nhất là trong việc sinh dữ liệu cho các bài toán.
À dạo này mình có bị 1,2 cái Down vote, mình rất mong mn nếu thấy có vấn đề gì trong bài viết của mình có thể ngoài việc down vote ra kèm theo một vài nhận xét để mình có thể tiến bộ hơn trong việc chia sẻ kiến thức. Cảm ơn mọi người đã đọc bài viết.
Tài liệu tham khảo
All rights reserved
