
[PyTorch Tutorial] #3 - Alignment ảnh chứng minh thư với PyTorch. Hướng dẫn dễ như ăn kẹo
Bài đăng này đã không được cập nhật trong 6 năm
Lời giới thiệu
Xin chào các bạn. Đây là bài hướng dãn thứ 2 về PyTorch mà mình muốn viết cách đặc biệt để chia sẻ cho Cộng đồng PyTorch Việt Nam rất hi vọng chúng ta sẽ có nhiều niềm cảm hứng khi sử dụng với Framework này. Trong bài hôm nay chúng ta sẽ cùng tìm hiểu về cách thực hiện một bước rất quan trọng trong quá trình thực hiện một bài toán số hóa đó chính là Alignment ảnh. Đây là một bước trong phần tiền xử lý ảnh đầu vào trước khi bóc tách các vùng thông tin để đưa vào hệ thống OCR phía sau. Và mình xin nhấn mạnh rằng nó rất quan trọng, ảnh hưởng rất nhiều đến kết quả của mô hình OCR cuối cùng. Phương pháp này cũng có thể áp dụng cho các bài toán OCR mà partern đầu vào có khuôn dạng cố định như chứng minh thư, thẻ căn cước, bằng lái xe .... OK chúng ta bắt đầu nhé
Bài toán nhận diện chứng minh thư
Đây là một bài toán không mới và cũng có khá nhiều bạn coi đây như một dự án để thực hành kĩ năng xử lý với các mô hình Deep Learning. Mình khuyên các bạn nên thực hành bài toán này vì nó sẽ giúp cho các bạn có điều kiện làm quen với nhiều loại mô hình khác nhau trong Deep Learning như Object Detection, Instance Segmentation, Optical Character Recognition. Pipeline cơ bản của nó có thể giải quyết như flow sau đây:

- Cropper hay còn gọi là alignment ảnh nhận đầu vào từ ảnh raw data. Crop vùng chứa chứng minh thư trong ảnh. Sử dụng Geometric Transform để xoay ảnh cho đúng chiều
- Detector được sử dụng để detect các thành phần trong ảnh như họ tên, ngày tháng năm sinh ....
- Reader là một module OCR để đọc nội dung chữ viết từ các thành phần đã được crop.
Cuối cùng tổng hợp và sắp xếp lại ta được một bài toán nhận diện chứng minh thư hoàn chỉnh. OK giờ chúng ta đi vào phần chính sẽ được giải quyết trong ngày hôm nay nhé
Alignment
Là một kĩ thuật phổ biến trong xử lý ảnh Nó chính là quá trình biến đổi các bộ dữ liệu khác nhau về cùng một hệ tọa độ. Các hình ảnh được chụp từ điện thoại, từ cảm biến được chụp bởi các góc độ khác nhau. Có nhiều phương pháp để thực hiện điều này như sử dụng Feature Based hay Template Matching. Tuy nhiên mục đích cuối cùng vẫn là làm sao để thu được một bức ảnh ngay ngắn trong hệ tọa độ để dễ dàng xử lý nhất. Ở đây với bài toán chứng minh thư bạn sẽ cần như trong hình sau:
Một ảnh được chụp từ bất kì tư thế nào cũng sẽ được xoay lại thẳng và ngay ngắn

Vậy làm thế nào để thực hiện được điều này, chúng ta có thể nghĩ ngay đến Geometric Transformations of Images trong xử lý ảnh mà cụ thể đó là Perspective Transformation - mapping 4 tọa độ ở ảnh gốc vào 4 tọa độ ở ảnh đích. Chúng ta có thể thấy ảnh ví dụ kinh điển như sau:

Trong đó bàn cờ đã được trải phẳng trong hệ tọa độ mới giúp chúng ta dễ xử lý hơn. Vậy nếu đã chọn hướng giải quyết là Perspective Transformation rồi thì câu hỏi tiếp theo của chúng ta đó là:
Làm sao để tìm được 4 điểm trên ảnh nguồn. Cụ thể là 4 góc của chứng minh thư?
Để trao lời cho câu hỏi trên thì chúng ta có nhiều cách tuy nhiên cách mình thấy đơn giản nhất đó là xây dựng một mô hình Deep Leanring để học được vị trí của 4 góc. Đó chính là mô hình Detection Object mà đã có rất nhiều bài viết về vấn đề này các bạn có thể tham khảo trên Organization của Sun* AI Research Team nhé. Vậy để thực hiện được điều đó thì chúng ta cần phải có dữ liệu chứ phải không. Bây giờ chúng ta sẽ tìm hiểu cách để làm dữ liệu nhé.
Chuẩn bị dữ liệu
Crawl data
Các bạn có thể tiến hành crawl data từ các nguồn như Google Images hoặc ảnh trên FB. Gợi ý cho các bạn có thể search các từ khóa như tìm đồ lạc, rơi giấy tờ ... hoặc vào các trang cầm đồ, cho vay tín dụng để có thể crawl được nhiều dữ liệu hơn. Sau khi chuẩn bị được một lượng nhỏ dữ liệu các bạn lưu nó vào cùng một thư mục như sau
Bước tiếp theo chúng ta cần gán nhãn cho dữ liệu nhé.
Gán nhãn dữ liệu
Chúng ta sử dụng tool LabelImg để tiến hành annotate dữ liệu. Trên trang chủ của nó đã có hướng dẫn sử dụng khá chi tiết rồi các bạn chỉ cần cài đặt theo thôi nhé. Mở thư mục hiện tại và tiến hành annotate nhé.

Ở đây chúng ta cần annotate 4 góc theo 4 class tương ứng như sau:
['top_left', 'top_right', 'bottom_left', 'bottom_right']
Các bạn chịu khó gán nhãn càng nhiều thì tay sẽ càng to và tất nhiên là quả ngọt cũng sẽ đến vì mô hình sẽ có độ chính xác tốt hơn nếu dữ liệu đủ đa dạng và đủ nhiều. Còn nếu bạn lười thì mình xin chia sẻ sẵn một data demo đã được gán nhãn sẵn (150 ảnh thôi) các bạn có thể tải về dùng luôn tại đây. Tất nhiên là vì tập nhỏ nên chỉ để demo thôi các bạn nhé còn muốn tốt hơn thì phải lao động thôi. Có làm thì mới có ăn hihi.
Sau khi gán nhãn xong bạn sẽ thu được một thư mục với các file XML tương ứng như sau:
Training mô hình với Detecto
Detecto là một thư viện được viết trên nền của PyTorch và rất dễ sử dụng với mục đích để các bạn lười code, tốn ít code nhất vẫn có thể training được mô hình object detect. Detecto hỗ trợ các bạn Transfer Learning với custom dataset giống như dataset chứng minh thư của chúng ta. Thư viện này có thể chạy inference trên cả image và video. Các bạn có thể thấy ảnh minh họa
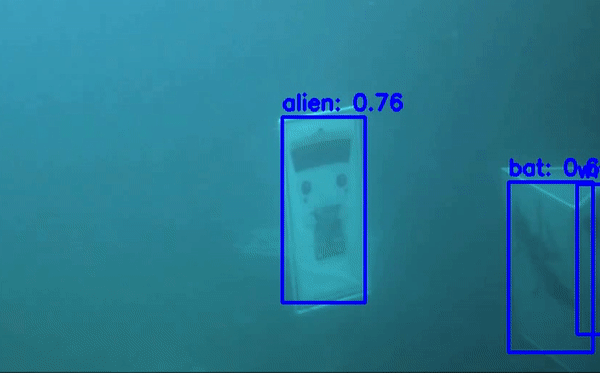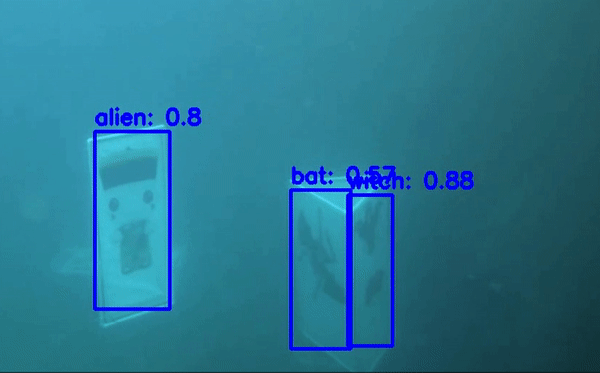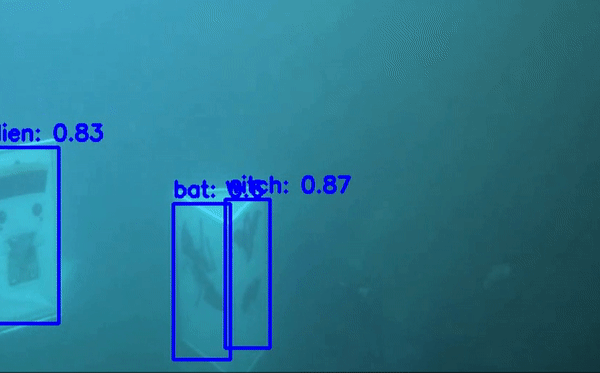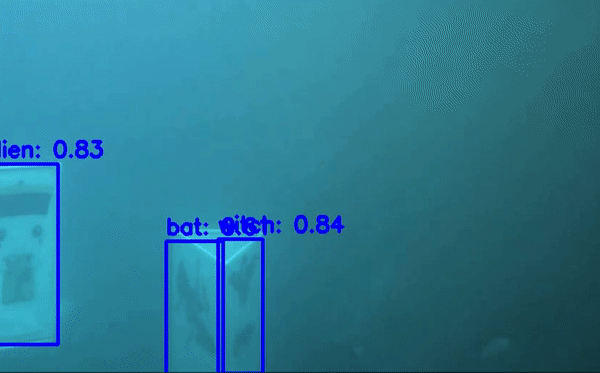
Các bạn thấy hay có thể star cho tác giả tại đây . Giờ thì bắt đầu vào bước training nhé
Import thư viện
Rất đơn giản các bạn chỉ thực hiện như sau
from detecto import core, utils, visualize
Định nghĩa dataset và classes
Cũng vô cùng đơn giản luôn. Các bạn chỉ cần khai báo đường dẫn thư mục của mình đồng thời khai báo các classses được sử dụng trong bước annoate trước đó.
dataset = core.Dataset('.data/sample')
model = core.Model([
'top_left', 'top_right', 'bottom_left', 'bottom_right'
])
Như vậy là bước định nghĩa và load dataset đã được thư viện Detecto giải quyết giúp chúng ta rồi. Các bạn không cần phải quan tâm đến format của file label hay các phần transform dữ liệu nữa. Giờ chúng ta sẽ đi vào training mô hình thôi
Training mô hình
Rất đơn giản chỉ với 1 dòng code.
losses = model.fit(dataset, epochs=500, verbose=True, learning_rate=0.001)
Việc tiếp theo là ngồi đợi thôi
Epoch 1 of 500
Epoch 2 of 500
Epoch 3 of 500
Epoch 4 of 500
Epoch 5 of 500
Epoch 6 of 500
Epoch 7 of 500
Epoch 8 of 500
Epoch 9 of 500
Please waiting ...
Sau khi training các bạn lưu lại mô hình để sử dụng tiếp nhé. Rất đơn giản với 1 câu lệnh
model.save('id_card_4_corner.pth')
Nếu các bạn cũng lười training nốt thì đây là mô hình demo được save ở tại epoch thứ 30 nhé. Tất nhiên là kết quả chưa thể tốt được do mới training được 1 số epoch ngắn và tập dữ liệu nhỏ.
Kiểm tra thử kết quả
Sau khi lưu mô hình chúng ta tiến hành kiểm tra lại kết quả với một file khác được down từ trên mạng về (không nằm trên tập train nhé). Giả sử như file này chẳng hạn.

Chúng ta tiến hành đọc file
fname = 'data/CMT_0106321395.JPG'
image = utils.read_image(fname)
và predict thử xem kết quả của mô hình như thế nào
labels, boxes, scores = model.predict(image)
Đầu ra của mô hình sẽ trả về danh sách cách labels, vị trí của các boxes và confident tương ứng trong scores. In thử các giá trị này chúng ta sẽ thấy nó trả ra khá nhiều box khác nhau
print(labels)
['bottom_left', 'bottom_right', 'top_left', 'top_right', 'bottom_left']
tương ứng với các boxes
priont(boxes)
tensor([[ 16.1044, 647.4228, 83.3507, 711.1550],
[894.2018, 636.8340, 956.9724, 701.6462],
[ 11.0550, 87.7889, 79.4745, 149.2691],
[892.7690, 80.5926, 953.7268, 139.2006],
[ 15.8271, 83.0950, 82.5982, 147.1947]])
Chúng ta vẫn có thể vẽ thử vị trí của các boxes này
import cv2
for i, bbox in enumerate(boxes):
bbox = list(map(int, bbox))
x_min, y_min, x_max, y_max = bbox
cv2.rectangle(image,(x_min,y_min),(x_max,y_max),(0,255,0),2)
cv2.putText(image, labels[i], (x_min, y_min), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0))
Thu được kết quả như sau:

Nhận xét kết quả
Có thể thấy rằng mô hình vẫn còn bị bắt nhầm khá nhiều. Tuy vẫn ra đủ 4 loại labels. Chúng ta có các cách xử lý như sau:
- Tạo thêm dữ liệu để training cho thêm đa dạng
- Training mô hình lâu hơn. 30 Epoch là khá ít
- Hậu xử lý dữ liệu với
non_max_suppression
Ở đây chúng ta sẽ thạm khảo cách thứ 3 còn hai cách trên thì tùy thuộc vào độ to tay của các bạn nhé. Chúng ta sẽ bàn tiếp phần này trong phần tiếp theo
Hậu xử lý kết quả
Như đã thấy ở bên trên chúng ta cần phải hậu xử lý lại kết quả thì output mới ngon được. Cách đầu tiên chúng ta có thể nghĩ đến đó là gộp những boxes có vị trí tương đối overlap với nhau và gộp chúng và cùng 1 class. Với bài toán này các boxes thường ở cách nhau khá xa nên hầu như hai boxes có tọa độ tương đối gần nhau thì thường cùng classs. Nếu không cùng thì nên xem lại dữ liệu có chỗ nào bị gán nhãn sai không. 
Non Max Suppression
Chúng ta sẽ thực hiện gộp các boxes có độ overlap nhất định đồng thời gán lại các labels tương ứng với các box đã được gộp đó. Chúng ta thực hiện chúng với hàm sau:
import numpy as np
def non_max_suppression_fast(boxes, labels, overlapThresh):
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# if the bounding boxes integers, convert them to floats --
# this is important since we'll be doing a bunch of divisions
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")
#
# initialize the list of picked indexes
pick = []
# grab the coordinates of the bounding boxes
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
# compute the area of the bounding boxes and sort the bounding
# boxes by the bottom-right y-coordinate of the bounding box
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(y2)
# keep looping while some indexes still remain in the indexes
# list
while len(idxs) > 0:
# grab the last index in the indexes list and add the
# index value to the list of picked indexes
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
# find the largest (x, y) coordinates for the start of
# the bounding box and the smallest (x, y) coordinates
# for the end of the bounding box
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
# compute the ratio of overlap
overlap = (w * h) / area[idxs[:last]]
# delete all indexes from the index list that have
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlapThresh)[0])))
# return only the bounding boxes that were picked using the
# integer data type
final_labels = [labels[idx] for idx in pick]
final_boxes = boxes[pick].astype("int")
return final_boxes, final_labels
Chúng ta thử xử lý dữ liệu với với boxes và labels phía trên:
final_boxes, final_labels = non_max_suppression_fast(boxes.numpy(), labels, 0.15)
Chúng ta sẽ thu được kết quả như sau:
final_boxes
>>>
array([[ 16, 647, 83, 711],
[894, 636, 956, 701],
[ 11, 87, 79, 149],
[892, 80, 953, 139]])
final_labels
>>>
['bottom_left', 'bottom_right', 'top_left', 'top_right']
Lúc này các boxes đã được gộp lại với chỉ 4 label. Chạy thử lại đoạn code để sinh ra ảnh output chúng ta thu được

OK giờ là phần cuối cùng. Chúng ta sẽ thực hiện Perspective Transformation để tiến hành crop chứng minh thư sang hệ tọa độ mới
Perspective Transform
Xác định tọa độ các điểm nguồn
Trước tiên chúng ta cần xác định được tọa độ các điểm nguồn dựa vào vị trí của các bxoes đã detect được. Chúng ta đơn giản hóa quá trình này bằng cách lấy điểm chính giữa của từng box thành điểm nguồn. Sử dụng hàm sau
def get_center_point(box):
xmin, ymin, xmax, ymax = box
return (xmin + xmax) // 2, (ymin + ymax) // 2
Tiếp theo chúng ta tiến hành tạo list final_points từ tập hợp các boxes thu được phía trên
final_points = list(map(get_center_point, final_boxes))
Và để thuận tiện cho bước tiếp theo chúng ta tiến hành tạo một dictionary để map label và box tương ứng
label_boxes = dict(zip(final_labels, final_points))
>>>
{'bottom_left': (49, 679),
'bottom_right': (925, 668),
'top_left': (45, 118),
'top_right': (922, 109)}
Transform sang tọa độ đích
Chúng ta định nghĩa hàm này như sau
def perspective_transoform(image, source_points):
dest_points = np.float32([[0,0], [500,0], [500,300], [0,300]])
M = cv2.getPerspectiveTransform(source_points, dest_points)
dst = cv2.warpPerspective(image, M, (500, 300))
return dst
Ở đây fix cứng tọa độ đích là ảnh 500x300 cho gần với kích thước của chứng minh thư. Bạn đọc có thể thay đổi nó. Tiếp theo chúng ta tiến hành transform
source_points = np.float32([
label_boxes['top_left'], label_boxes['top_right'], label_boxes['bottom_right'], label_boxes['bottom_left']
])
# Transform
crop = perspective_transoform(image, source_points)
Ta thu được kết quả như sau

Như các bạn thấy thì kết quả này đã dễ dàng xử lý hơn rồi phải không nào. Các bạn có thể thử nghiệm nhiều với các ảnh mới hơn nhé
Kết luận
Bài này khá đơn giản với mong muốn các bạn có thể hiểu đại khái các bước xử lý Alignment cho ảnh chứng minh thư như thế nào. Bằng việc sử dụng thư viện Detecto giúp cho việc training mô hình rất đơn giản và dần dần khiến chúng ta có cảm giác việc sử dụng Deep Learning cũng là một công cụ giúp chúng ta lập trình và giải quyết bài toán tốt hơn chứ không phải một cái gì đó khủng khiếp như người ta từng nghĩ cả. Chúc các bạn vui vẻ và hẹn gặp lại trong những bài viết sau
All rights reserved
