Mạng nơ-ron tích chập (P1)
Bài đăng này đã không được cập nhật trong 4 năm
Chín trên mười lần khi bạn nghe về việc thuật toán học sâu (deep learning) phá vỡ một rào cản công nghệ mới, thì đều dính dáng tới các Mạng Nơ-ron Tích chập (Convolutional Neural Networks). Còn được gọi là CNNs hay ConvNets, chúng là những hòn đá tảng trong lĩnh vực mạng nơ-ron học sâu. Chúng có thể học được cách phân loại các hình ảnh thậm chí còn tốt hơn con người trong một số trường hợp. Nếu có một phương pháp mà không nói quá lên tí nào, thì đó chính là CNNs.
Cái hay ở đây là nó rất dễ hiểu khi ta chia nó ra thành các thành phần cơ bản. Tôi sẽ hướng dẫn bạn qua về nó.
X và O
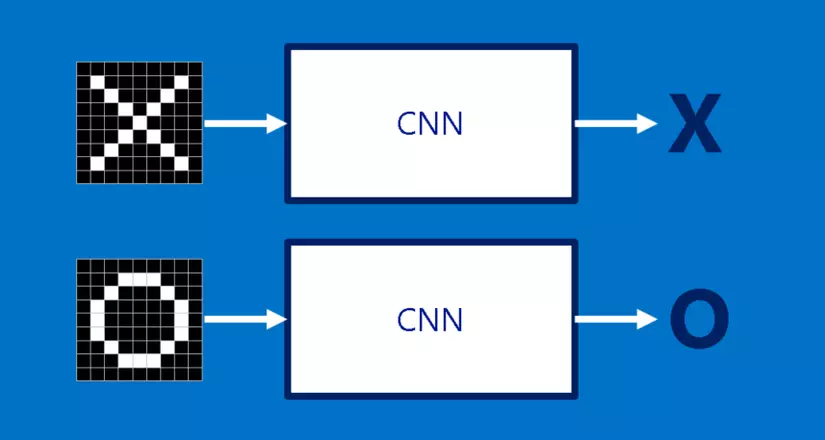
Chúng ta sẽ dùng một ví dụ rất đơn giản: xác định xem hình ảnh là một X hay một O. Ví dụ này là đủ để minh họa các nguyên lý đằng sau CNNs, nhưng vẫn đủ đơn giản để tránh bị sa lầy vào các chi tiết không cần thiết. CNN của chúng ta có một công việc. Mỗi lần chúng ta đưa nó một bức hình, nó phải quyết định xem nó có một X hay một O. Giả sử rằng luôn có một hoặc là cái này hoặc là cái kia.

Một cách tiếp cận ngây thơ để giải quyết vấn đề này là lưu một hình ảnh của một X và của một O, và so sánh mỗi hình ảnh mới với hai hình mẫu đó để xem nó khớp với bên nào hơn. Điều khiến cho công việc này khó khăn là do máy tính chỉ hiểu các con số. Với máy tính, một hình ảnh trông giống như một mảng hai chiều các điểm ảnh (tưởng tượng nó như một bàn cờ khổng lồ) với một số trong mỗi ô. Trong ví dụ của chúng ta một điểm ảnh có giá trị 1 là trắng, và -1 là đen. Khi so sánh hai hình ảnh, nếu có giá trị điểm ảnh không trùng, thì những ảnh đó đối với máy tính là không khớp. Lý tưởng nhất là chúng ta muốn xem liệu chúng thuộc X hay O ngay cả khi chúng bị tịnh tiến, bị co, xoay hoặc biến dạng. Đây là khi ta cần CNNs.
Feature (Đặc điểm)
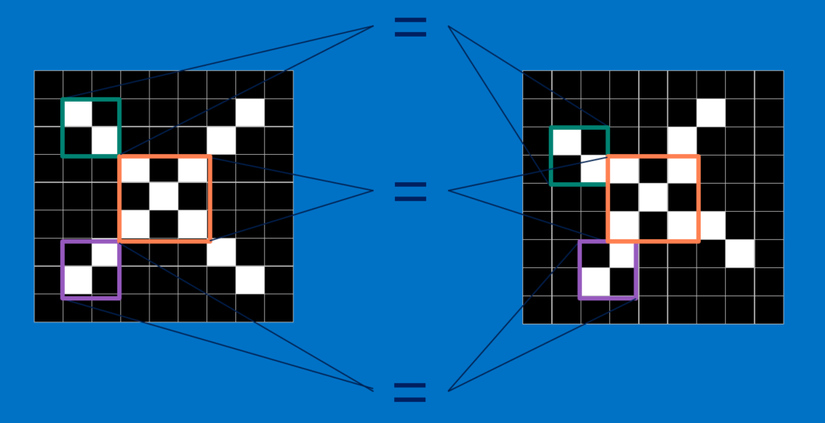
CNNs so sánh hình ảnh theo từng mảnh. Các mảnh mà nó tìm được gọi là các feature. Bằng cách tìm ở mức thô các feature khớp nhau ở cùng vị trí trong hai hình ảnh, CNNs nhìn ra sự tương đồng tốt hơn nhiều so với việc khớp toàn bộ bức ảnh.
Mỗi feature giống như một hình ảnh mini - một mảng hai chiều nhỏ. Các feature khớp với các khía cạnh chung của các bức ảnh. Trong trường hợp các hình ảnh X, các feature bao gồm các đường chéo và hình chữ thập, sẽ nắm bắt tất cả những đặc điểm quan trọng của hầu hết các hình ảnh X. Những feature này có lẽ sẽ khớp với phần cánh và phần trung tâm của bất kỳ hình ảnh một X nào.
Tích chập (Convolution)
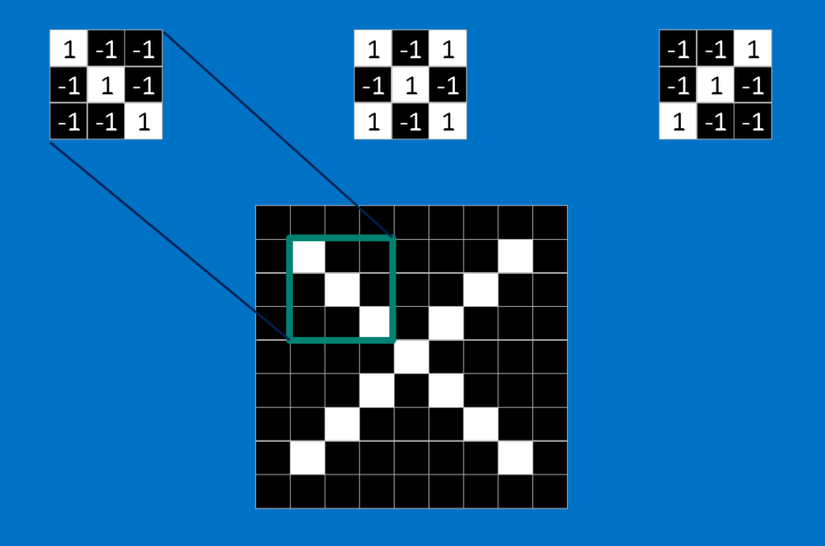
Khi xem một hình ảnh mới, CNN không biết chính xác nơi các feature này sẽ khớp nên nó sẽ thử chúng khắp mọi nơi, ở mọi vị trí có thể. Khi tính toán sự khớp của một feature trên toàn bộ ảnh, chúng ta làm thành một filter (bộ lọc). Phần toán ta sử dụng để làm điều này được gọi là tích chập, từ đó mà Mạng Nơ-ron Tích chập (Convolutional Neural Networks) có tên là như vậy.
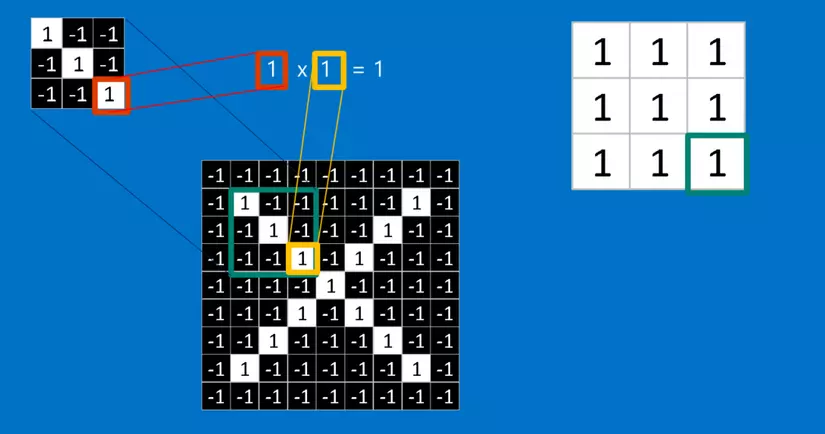
Toán tích chập này học sinh lớp sáu cũng có thể làm. Để tính toán sự khớp của một feature đối với một mảnh của hình ảnh, ta chỉ cần nhân mỗi điểm ảnh trong feature với giá trị của điểm ảnh tương ứng trong mảnh hình ảnh. Sau đó cộng tổng lại và chia cho số lượng điểm ảnh trong feature. Nếu cả hai điểm ảnh màu trắng (giá trị 1) thì 1 x 1 = 1. Nếu cả hai đều là màu đen, thì ( -1 ) x ( -1 ) = 1. Dù bằng cách nào, mỗi điểm ảnh mà khớp thì đều cho ra kết quả 1. Tương tự như vậy, bất kỳ cái nào không khớp đều ra -1. Nếu tất cả các điểm ảnh trong feature đều khớp, thì cộng tổng lại rồi chia cho số điểm ảnh thì sẽ ra là 1. Tương tự, nếu không có điểm ảnh nào trong feature khớp với mảnh hình ảnh, thì kết quả là -1.
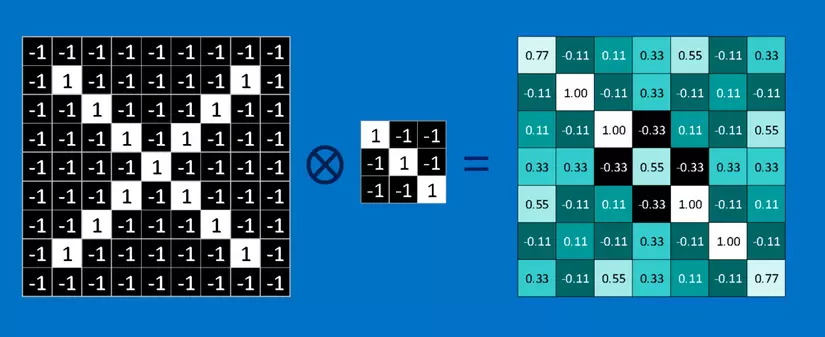
Để hoàn tất tích chập, chúng ta lặp lại quá trình này, xếp các feature với mọi mảnh hình ảnh có thể. Ta có thể lấy kết quả từ mỗi tích chập và tạo một mảng hai chiều mới từ đó, dựa vào vị trí của mỗi mảnh nằm trong hình ảnh. Bản đồ các phần khớp nhau này cũng là một phiên bản đã được lọc từ hình ảnh gốc. Nó là một bản đồ thể hiện nơi tìm thấy feature trong hình ảnh. Các giá trị gần 1 cho thấy sự khớp mạnh, các giá trị gần -1 cho thấy sự khớp mạnh với âm bản của feature, và các giá trị gần bằng 0 cho thấy không khớp với bất kỳ loại nào.

Bước tiếp theo là lặp lại toàn bộ quá trình chập cho từng feature khác. Kết quả là một tập hợp các hình ảnh đã được lọc, mỗi cái ứng với mỗi filter của chúng ta. Sẽ thuận tiện khi nhìn toàn bộ các thao tác tích chập như là một bước xử lý duy nhất. Trong CNNs cái này được gọi là một layer (lớp) tích chập, cho thấy gián tiếp rằng sẽ sớm có các layer khác được thêm vào.
Dễ hiểu vì sao mà CNNs có cái tiếng là những con lợn tính toán. Mặc dù chúng ta có thể phác họa CNN trên mặt sau của một chiếc khăn ăn, số lượng phép tính cộng, nhân, chia có thể tăng lên nhanh chóng. Toán học mà nói, chúng sẽ scale (phình ra) một cách tuyến tính với số lượng điểm ảnh trong hình ảnh, với số lượng điểm ảnh trong mỗi feature và với số lượng các feature. Với rất nhiều yếu tố, thật dễ để làm cho bài toán này lớn lên nhiều triệu lần. Có thể hiểu vì sao mà các nhà sản xuất vi mạch đang làm các con chip chuyên dụng trong nỗ lực theo kịp với nhu cầu của CNNs.
Pooling (để chung)
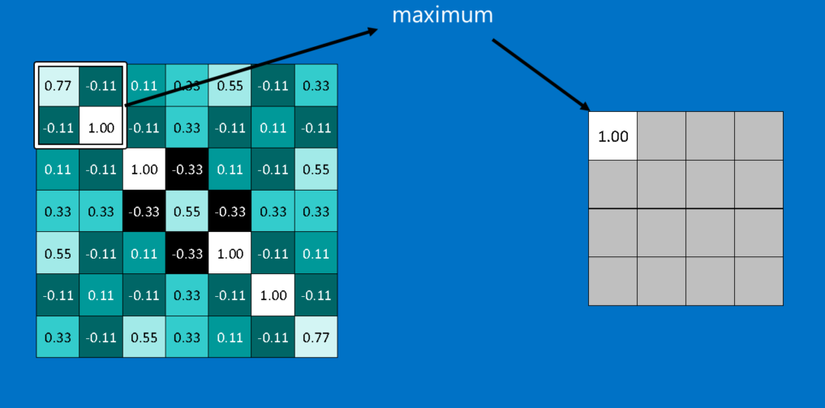
Một công cụ mạnh mẽ khác mà CNNs sử dụng được gọi là pooling. Pooling là một cách lấy những hình ảnh lớn và làm co chúng lại trong khi vẫn giữ các thông tin quan trọng nhất trong đó. Pooling chỉ dùng kiến thức toán của lớp hai. Nó bao gồm việc duyệt bước một ô vuông cửa sổ nhỏ dọc trên một hình ảnh và lấy giá trị lớn nhất từ cửa sổ ở mỗi bước. Trong thực tế, một cửa sổ có cạnh 2 hoặc 3 điểm ảnh và duyệt bước mỗi 2 điểm ảnh là được.
Sau khi pooling, một hình ảnh sẽ có khoảng một phần tư số điểm ảnh so với lúc bắt đầu. Vì nó giữ các giá trị lớn nhất từ mỗi cửa sổ, nó sẽ bảo toàn tính khớp của mỗi feature bên trong cửa sổ. Nghĩa là nó không quan tâm quá nhiều về vị trí chính xác nơi feature khớp, miễn là nó khớp ở chỗ nào đó trong cửa sổ. Kết quả là CNNs có thể tìm xem liệu một feature có nằm trong hình ảnh mà không cần lo nó nằm ở đâu. Điều này giúp giải quyết vấn đề của máy tính là quá trực nghĩa.
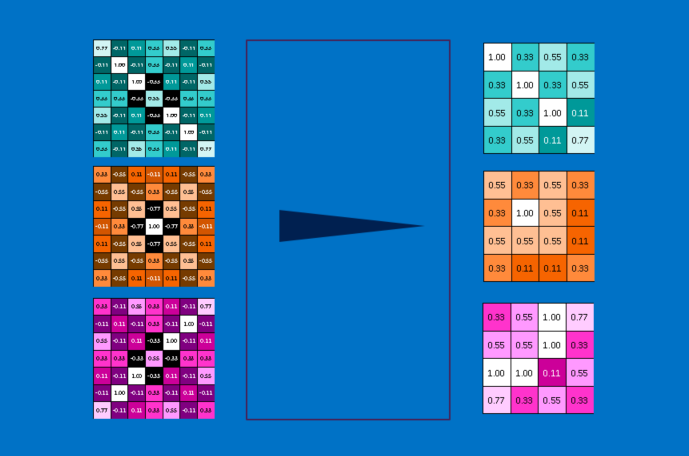
Một layer pooling là hoạt động thực hiện pooling trên một hình ảnh hoặc một tập các hình ảnh. Đầu ra sẽ có cùng số lượng hình ảnh, nhưng mỗi cái sẽ có điểm ảnh ít hơn. Điều này cũng rất hữu ích trong việc quản lý tải trọng tính toán. Hạ một tấm ảnh 8 megapixel xuống còn 2 megapixel sẽ giúp mọi xử lý tải về trở nên dễ dàng.
Rectified Linear Units (tinh chỉnh các đơn vị tuyến tính)
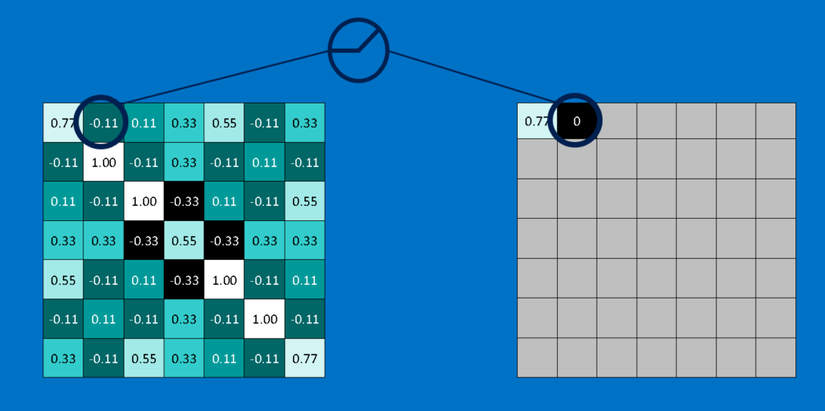
Đóng vai trò nhỏ nhưng quan trọng trong quá trình này là Rectified Linear Unit hoặc ReLU. Toán của cái này cũng rất đơn giản -- bất cứ nơi nào có số âm, hoán đổi nó với 0. Điều này giúp CNN giữ vững sự tin cậy toán học bằng cách giữ các giá trị đã được học khỏi bị mắc kẹt gần 0 hoặc bị thổi bay về vô tận. Đó là thứ dầu mỡ bôi trơn CNNs- không hấp dẫn mấy, nhưng nếu không có nó, chúng sẽ không đi xa hơn được.

Đầu ra của một layer ReLU có kích thước giống với đầu vào, chỉ là tất cả các giá trị âm được loại bỏ.
(còn tiếp)
Tham khảo
- Bài viết gốc http://brohrer.github.io/how_convolutional_neural_networks_work.html
- Tham khảo thuật ngữ https://ongxuanhong.wordpress.com/2015/12/29/convolutional-neural-networks-la-gi/
- Tham khảo https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks/
All rights reserved
