Machine Learning thật thú vị (1): Dự đoán giá nhà đất
Bài đăng này đã không được cập nhật trong 4 năm
Adam Geitgey đã viết một loạt series "Machine Learning is fun", và đây được đánh giá là series Machine Learning dành cho số đông: khi tác giả tối thiểu những công thức tính toán và tối đa lý giải thông qua hình ảnh. Một series mà bất cứ ai quan tâm đến Machine Learning (ML) đều nên đọc.
Được sự đồng ý của tác giả Adam Geitgey, mình xin dịch toàn bộ series Hy vọng rằng nhiều người có thể hiểu hơn về ML và quan tâm tới nó. Trong quá trình dịch, mình cũng sẽ bổ sung thêm hiểu biết hoặc làm rõ một vài khái niệm mà mọi người có thể thấy khó hiểu
Phần 1 này đã được tác giả Hồ Văn Tuấn dịch một phần. Mình có sử dụng tiếp nguồn tác giả đã dịch và dịch bổ sung phần còn thiếu.
Machine Learning là gì?
Machine Learning là ý tưởng rằng có những thuật toán chung chung (generic algorithms) có thể cho bạn biết điều gì đó thú vị về một bộ dữ liệu mà không cần phải viết bất kỳ mã tùy chỉnh nào cụ thể cho vấn đề. Thay vì viết mã, bạn đưa dữ liệu vào thuật toán chung chung và nó xây dựng logic riêng dựa trên dữ liệu.
Ví dụ như thuật toán phân loại dữ liệu, nó có thể đưa dữ liệu vào các nhóm khác nhau. Thuật toán phân loại được sử dụng để nhận dạng số viết tay cũng có thể được sử dụng để phân loại email rác và email thường mà không thay đổi một dòng mã nào. Cùng một thuật toán nhưng được đào tạo trên tập dữ liệu khác nhau với mục đích khác nhau.
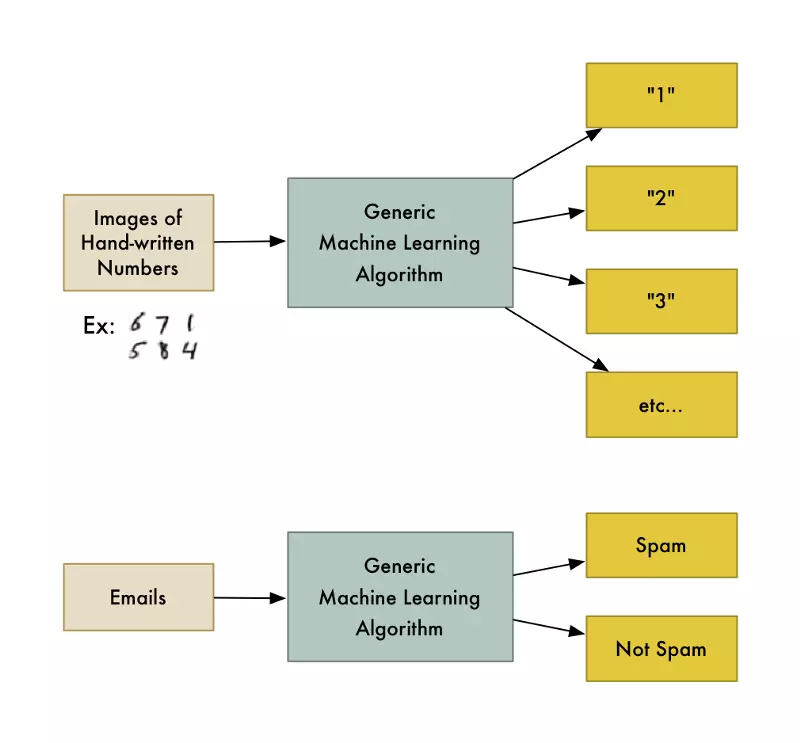 Thuật toán Machine Learning này là một hộp đen có thể được sử dụng lại cho nhiều vấn đề phân loại khác nhau.
Machine Learning là một thuật ngữ bao hàm rất nhiều thuật toán chung chung.
Thuật toán Machine Learning này là một hộp đen có thể được sử dụng lại cho nhiều vấn đề phân loại khác nhau.
Machine Learning là một thuật ngữ bao hàm rất nhiều thuật toán chung chung.
Hai loại thuật toán Machine Learning
Thuật toán Machine Learning có hai loại chính: học có giám sát và học không giám sát. Sự khác biệt tuy đơn giản nhưng thực sự quan trọng.
Học có giám sát
Giả sử bạn là đại lý bất động sản. Doanh nghiệp của bạn đang phát triển, bạn thuê một nhóm các nhân viên thực tập mới để giúp bạn trong công việc. Nhưng có một vấn đề, khi bạn lướt qua một căn hộ thì bạn sẽ có ngay một đánh giá về giá trị của căn hộ này, nhưng các nhân viên mới của bạn thì sao? Họ không có kinh nghiệm như bạn để có thể làm được điều đó.
Để giúp các nhân viên mới của bạn có thể làm được điều này, bạn quyết định viết một ứng dụng nhỏ có thể ước tính giá trị của một căn hộ trong khu vực của bạn dựa trên diện tích, khu đô thị, số giường ngủ, ... và những dữ liệu về các căn hộ tương tự đã bán.
Bạn bắt đầu viết ra các lịch sử giao dịch đã bán trong thành phố của bạn trong 3 tháng. Đối với mỗi căn hộ, bạn viết ra một số liệu chi tiết gồm: số phòng ngủ, diện tích, Khu đô thị ... và quan trọng nhất là giá bán cuối cùng:
| Số phòng ngủ | Diện tích | Khu đô thị | Giá bán |
|---|---|---|---|
| 3 | 2000 | Times City | $250,000 |
| 2 | 800 | Royal City | $300,000 |
| 2 | 850 | Times City | $150,000 |
| 1 | 550 | Times City | $78,000 |
| 4 | 2000 | KDT Linh Đàm | $150,000 |
Sử dụng dữ liệu đó, tôi muốn tạo một chương trình có thể ước tính được giá trị của bất kỳ căn hộ nào khác trong khu vực, VD:
| Số phòng ngủ | Diện tích | Khu đô thị | Giá bán |
|---|---|---|---|
| 3 | 2000 | Royal City | ??? |
Đây được gọi là học có giám sát. Bạn biết từng căn hộ bán giá bao nhiêu, hay nói cách khác, bạn biết câu trả lời cho vấn đề và có thể làm ngược lại từ đó để tìm ra logic.
Để xây dựng ứng dụng này, bạn cho dữ liệu đào tạo của bạn về mỗi căn hộ vào thuật toán Machine Learning của bạn. Thuật toán sẽ cố gắng tìm ra những phép toán học cần thiết để thực hiện để tính ra kết quả cuối cùng như mong muốn.
Điều này giống như tìm kiếm câu trả lời cho bài toán với tất cả các dấu phép tính đã bị xóa đi:
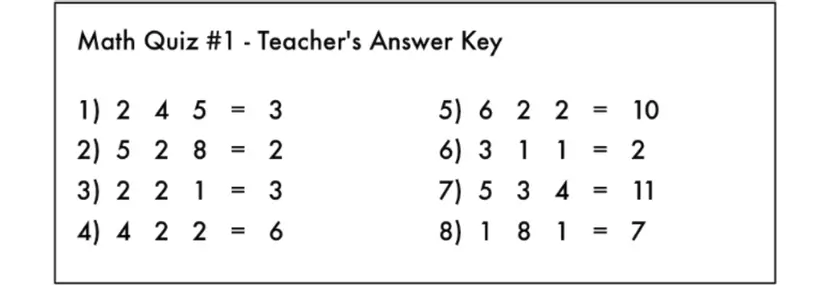 Từ hình vẽ, liệu bạn có thể tìm ra lời giải cho bài toán.
Từ hình vẽ, liệu bạn có thể tìm ra lời giải cho bài toán.
Trong quá trình học có giám sát, bạn sẽ để cho máy tính tìm ra mối quan hệ đó cho bạn. Và một khi bạn biết những phép toán học nào là cần thiết để giải quyết vấn đề cụ thể này, bạn có thể trả lời cho bất kỳ vấn đề nào khác cùng loại!
Học không giám sát
Hãy trở lại ví dụ ban đầu của tôi với đại lý bất động sản. Nếu bạn không biết giá bán cho mỗi căn hộ thì sao? Ngay cả khi tất cả những gì bạn biết là kích thước, vị trí, số phòng ngủ, ... của mỗi căn hộ, bạn sẽ vẫn có thể làm được điều gì đó tuyệt vời tuyệt vời. Đây được gọi là học không giám sát.
| Số phòng ngủ | Diện tích | Khu đô thị |
|---|---|---|
| 3 | 2000 | Times City |
| 2 | 800 | Royal City |
| 2 | 850 | Times City |
| 1 | 550 | Times City |
| 4 | 2000 | KDT Linh Đàm |
Đây giống như một người đưa ra danh sách các con số trên một tờ giấy và nhẹ nhàng nói với bạn rằng:
Tôi thực sự không biết những con số này có ý nghĩa gì nhưng có lẽ bạn có thể tìm ra thứ gì đó như một mối liên hệ, một phép tính hoặc một cái gì đó - Oh Yeah!
Vậy bạn có thể làm gì với dữ liệu này? Đối với người mới bắt đầu, bạn có thể có một thuật toán tự động phân khúc thị trường trong dữ liệu của bạn. Có thể bạn sẽ biết rằng những người mua căn hộ ở Times City có vẻ như thích những căn hộ có nhiều phòng ngủ, còn những người mua nhà ở Royal City thì thích những căn hộ có diện tích lớn. Biết được những nhu cầu này của khách hàng, bạn sẽ có thể đưa ra các chiến lược bán hàng của bạn cho hợp lý.
Một điều thú vị khác mà bạn có thể làm là tự động xác định bất kỳ căn hộ nào đó khác biệt so với các ngôi nhà còn lại. Ví dụ như những căn hộ ở những khu đô thị đắt tiền như Royal City là biệt thự khổng lồ và bạn có thể tập trung đội ngũ bán hàng giỏi nhất tiếp cận vào những khu vực này để tăng doanh số của bạn.
Học tập theo chế độ giám sát là những gì chúng ta sẽ tập trung cho phần còn lại của bài đăng này, nhưng đó không phải là vì học không giám sát không ít hữu ích hay thú vị nhé. Trên thực tế, học không giám sát ngày càng trở nên quan trọng vì các thuật toán này tốt hơn bởi vì nó có thể sử dụng mà không cần gắn nhãn dữ liệu với câu trả lời chính xác.
*Lưu ý: Có rất nhiều loại thuật toán Machine Learning khác, nhưng đây là một nơi khá tốt để bắt đầu.
Chương trình Machine Learning demo
Vậy làm thế nào bạn sẽ viết chương trình để ước tính giá trị của một căn hộ như trong ví dụ của tôi ở trên? Trước tiên bạn hãy xem lại yêu cầu tôi đã nêu ở trên
Nếu bạn chưa biết gì về Machine Learning, bạn có thể cố gắng viết ra một số quy tắc cơ bản để ước tính giá của một căn hộ trông như thế này:
function estimate_house_sales_price ($numOfBedrooms, $sqft, $neighborhood)
{
$price = 0;
$pricePerSqft = 200; // VD giá trung bình là $200 / diện tích
if ($neighborhood == 'Royal City') {
$pricePerSqft = 400; // Royal City đắt gấp đôi
} elseif ($neighborhood == 'KDT Linh Đàm') {
$pricePerSqft = 100; // KDT Linh Đàm rẻ hơn 1/2
}
$price = pricePerSqft * $sqft; // Tính giá dựa trên giá theo diện tích
# Điều chỉnh giá dựa theo số phòng ngủ
if ($numOfBedrooms == 0) {
$price = $price - 20000; // VP làm việc thì rẻ hơn
} else {
$price = $price + ($numOfBedrooms * 1000); // Có phòng ngủ thì đắt hơn, tăng theo cấp số cộng
}
return $price;
}
Chương trình của bạn sẽ khó có thể hoàn hảo và sẽ rất khó để duy trì khi giá thị trường thay đổi. Và dĩ nhiên rồi, đây vẫn chưa thể gọi là Machine Learning mà chỉ là những gì bạn đang biết.
Vẫn là hàm tính giá đó, với các biến đó, tôi rút gọn hàm trên thành một hàm rất đơn giản như thế này:
function estimate_house_sales_price ($numOfBedrooms, $sqft, $neighborhood)
{
$price = 0; // khởi tạo
// Cho thêm chút mắm vào
$price += $numOfBedrooms * 0.841231951398213;
// Ok. Thêm chút muối nữa
$price += $sqft * 1231.1231231;
// Greate. Thêm chút đường nữa
$price += $neighborhood * 2.3242341421;
// So crazy. Thêm chút mắm tôm nữa
$price += 201.23432095;
return $price;
}
Bạn có tin rằng 2 hàm trên có chức năng ý hệt nhau không? Bạn có thể tự test để kiểm tra nhé.
Điều bí ẩn có lẽ bạn cũng thấy chính là các số 0.841231951398213, 1231.1231231, 2.3242341421 và 201.23432095? Đây chính là weight (trọng số). Nếu chúng ta có thể tìm được trọng số hoàn hảo thì chúng ta sẽ có thể đoán được giá của một căn hộ. Đến đây bạn đã thấy Machine Learning ở đâu rồi chứ?
Một cách đơn giản để tìm ra các trọng số như sau:
Bước 1:
Bắt đầu với mỗi trọng lượng được đặt thành 1.0:
function estimate_house_sales_price ($numOfBedrooms, $sqft, $neighborhood)
{
$price = 0; // khởi tạo
// Cho thêm chút mắm vào
$price += $numOfBedrooms * 1.0;
// Ok. Thêm chút muối nữa
$price += $sqft * 1.0;
// Greate. Thêm chút đường nữa
$price += $neighborhood * 1.0;
// So crazy. Thêm chút mắm tôm nữa
$price += 1.0;
return $price;
}
Bước 2:
Chạy hàm với tất cả ngôi nhà mà bạn biết và xem kết quả so với thực tế:
| Số phòng ngủ | Diện tích | Khu đô thị | Giá bán | Machine Learning đoán |
|---|---|---|---|---|
| 3 | 2000 | Times City | $250,000 | $178,000 |
| 2 | 800 | Royal City | $300,000 | $371,000 |
| 2 | 850 | Times City | $150,000 | $148,000 |
| 1 | 550 | Times City | $78,000 | $101,000 |
| 4 | 2000 | KDT Linh Đàm | $150,000 | $121,000 |
Kết quả sai bét nhè nhỉ? Dĩ nhiên rồi, vì lúc này trọng số = 1.0 chưa phải là trọng số hoàn hảo. Chúng ta sẽ dựa vào kết quả sai này để điều chỉnh trọng số cho đến khi nó trở nên hoàn hảo. Ví dụ: nếu căn hộ đầu tiên được bán với giá $250,000 nhưng hàm của bạn đoán rằng nó đã bán với giá $178.000, bạn sẽ bị mất $72,000 cho căn hộ đó.
Bây giờ, cộng thêm bình phương của số tiền mà bạn phải trả cho mỗi căn hộ mà bạn có trong bộ dữ liệu. Giả sử rằng bạn đã có 500 doanh số bán nhà trong bộ dữ liệu của bạn và khoảng vuông cho biết hàm của bạn đã giảm cho mỗi căn hộ là tổng cộng $86.123,373. Đó một cách đo độ lệch của dự đoán so với kết quả thực tế. Lấy độ lệch đó chia cho 500 để có được một số trung bình, gọi là cost cho chức năng của bạn.
Nếu bạn có được cost này bằng 0 bằng cách chạy với weight đã tìm ra, hàm của bạn sẽ là hoàn hảo. Nó có nghĩa là trong mọi trường hợp, function của bạn hoàn toàn đoán được giá căn hộ dựa trên dữ liệu đầu vào. Và đó là mục tiêu của tôi - làm cho cost này càng thấp càng tốt bằng cách thử các trọng số khác nhau.
Bước 3:
Lặp lại Bước 2 ở trên với trọng số khác nhau đến khi nào bạn tìm ra được trọng số tốt nhất, tức cost gần bằng 0 nhất thì bạn đã gần tới đích rồi.
Lưu ý
Bạn thấy Machine Learning đơn giản rồi chứ? Nó chính là những gì bạn vừa làm. Bạn đã lấy một số dữ liệu, bạn cho xử lý thông qua ba bước chung, thực sự đơn giản, và bạn đã kết thúc với một hàm có thể đoán được kết quả bạn muốn tìm mà không sử dụng những logic thông thường.
Và đây là một số lưu ý bạn cần nhớ:
- Nghiên cứu trong nhiều lĩnh vực (như ngôn ngữ học / dịch thuật) trong 40 năm qua đã chỉ ra rằng việc những thuật toán chung chung "mò mẫm trọng số" làm tốt hơn con người với những luật lệ phức tạp của mình trong giải quyết vấn đề. Cách tiếp cận "thầm lặng" của Machine Learning cuối cùng cũng có thể đánh bại được các chuyên gia.
- Hàm bạn tìm được khá "ngốc". Nó thậm chí không biết diện tích hay số phòng ngủ là gì. Tất cả những gì nó biết là nó cần phải thay đổi trọng số để có được câu trả lời chính xác.
- Có thể bạn không biết tại sao một bộ trọng số lại làm tốt dự đoán. Bạn vừa viết được một hàm mà bạn không thực sự hiểu nhưng bạn có thể chứng minh nó sẽ hoạt động.
- Mở rộng từ bài toán trên, hãy tưởng tượng rằng thay vì bạn đưa vào các con số như
$sqft,$numOfBedrooms... để tính ra giá của một căn hộ, bạn chuyển thành đưa dữ liệu đầu vào là giá trị pixel từ ảnh chụp của camera trước của ô tô, và giá trị đầu ra là góc quay của bánh lái. Thế là bạn vừa tạo ra một hàm giúp ô tô tự điều hướng rồi đó .
.
Đọc thêm
"Thử từng giá trị" ở bước 3!??
Dĩ nhiên là chúng ta không thể thử từng tập hợp tất cả các bộ weights (trọng số) để tìm ra tập tốt nhất. Nếu thế, chúng ta sẽ phải thử đến vô tận bởi tập số là vô cùng. Các nhà toán học đã tìm ra một phương pháp để nhanh chóng tìm được các trọng số mà không phải thử quá nhiều lần.
Đầu tiên, chúng ta viết lại phương trình đơn giản ở bước 2 phía trên:
$
Cost = \dfrac{\sum_{i=1}^{500} (MyGuess(i) - RealAnswer(i))^2}{500 * 2}
$
Đây được gọi là hàm mất mát
Cost function còn có tên gọi khác là loss function (hàm mất mát)
Chúng ta sẽ viết lại chính xác phương trình phía trên, nhưng sử dụng một loạt các ký hiệu toán học khác:
$
J(\theta) = \dfrac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})^2
$
Trong đó, đại diện cho trọng số hiện tại, và là "mất mát của trọng số hiện tại"
Phương trình này thể hiện sự sai lệch của hàm dự đoán giá cho trọng số hiện tại
Nếu chúng ta đồ thị hàm mất mát này cho tất cả các giá trị trọng số của số phòng ngủ hay diện tích, chúng ta có đồ thị như dưới đây
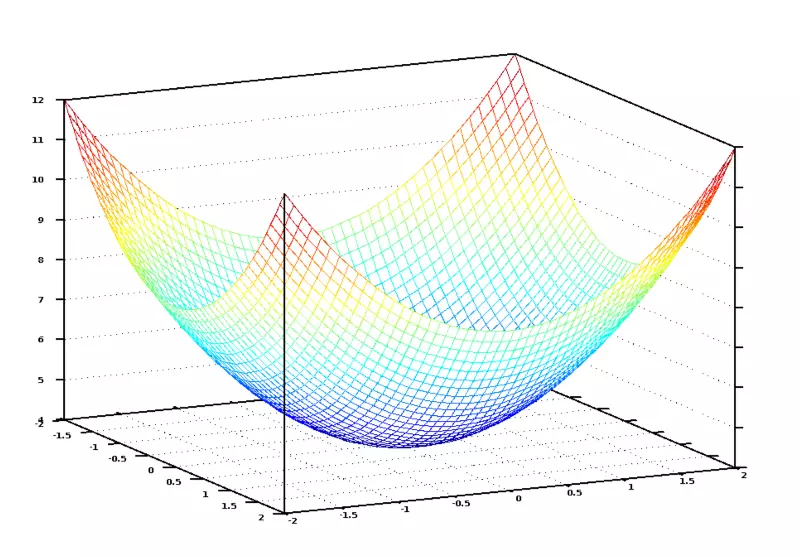 Trong đồ thị này, điểm thấp nhất màu xanh là điểm mà hàm mất mát đạt cực tiểu - khi đó, hàm mất mát sẽ ít sai nhất. Vị trí trọng số để hàm mất mát đạt cực tiểu chính là lời giải của bài toán.
Trong đồ thị này, điểm thấp nhất màu xanh là điểm mà hàm mất mát đạt cực tiểu - khi đó, hàm mất mát sẽ ít sai nhất. Vị trí trọng số để hàm mất mát đạt cực tiểu chính là lời giải của bài toán.
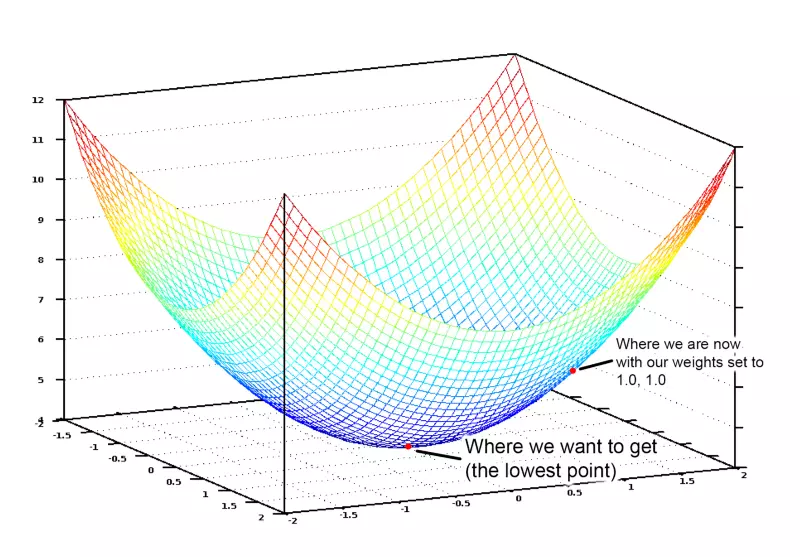
Do đó, chúng ta cần điều chỉnh tất cả các trọng số để "lăn xuống" điểm cực tiểu đó. Nếu chúng ta thay đổi trọng số từng tí một, theo chiều hướng về cực tiểu, thì cuối cùng, chúng ta sẽ tìm ra lời giải, mà không phải thử tất cả các trọng số có thể như ý tưởng ban đầu.
Trong môn Giải tích, chúng ta biết rằng: đạo hàm của hàm số cho ta biết hệ số góc của một hàm số ở bất kì điểm nào. Hay nói theo một cách khác, nó cho ta biết chiều mà ta cần đi để chạm tới cực tiểu.
Chúng ta có thể thay đổi trọng số dần dần bằng cách trừ đi giá trị đạo hàm từng phần của hàm mất mát đối với từng trọng số. Lặp lại quá trình như vậy cho tới khi chúng ta chạm tới cực tiểu và có giá trị tốt nhất của trọng số.
Đó là giải thích ngắn gọn của phương pháp tìm trọng số với tên gọi là batch gradient descent - xuống dốc toàn lô. Hãy đọc thêm về đề tài này nếu bạn cảm thấy thú vị.
Toàn lô (batch): tính toán đạo hàm trên toàn bộ tập dữ liệu Từng lô (mini-batch): thông thường tập dữ liệu đào tạo (training) rất lớn, dẫn tới tính toán để tìm ra đạo hàm sẽ rất lâu. Người ta chia tập dữ liệu thành nhiều tập con, và tính toán đào tạo trên từng tập một, giúp tính toán nhanh hơn.
Khi chúng ta sử dụng thư viện để giải quyết vấn đề, tất cả những điều trên đã được ẩn đi. Dẫu sao thì, hiểu điều gì đang diễn ra vẫn sẽ rất có ích cho bạn.
Điều gì mà bạn cũng đã bỏ qua
Thuật toán 3 bước phía trên có tên gọi là multivariate linear regression (hồi quy tuyến tính đa biến). Bạn dự hàm số đoán đường thẳng phù hợp với tất cả điểm dữ liệu nhà đất, từ đó bạn có thể đoán được giá nhà mà bạn chưa từng biết trước đây. Đây là một ý tưởng tuyệt vời và có thể giải quyết các bài toán thực tế đơn giản.
Hồi quy: các điểm giá trị liên tục như giá nhà, độ dài đường thẳng; đối nghịch với phân nhóm (classification) Tuyến tính: theo dạng đường thẳng Đa biến: kết quả phụ thuộc vào nhiều biến, như giá nhà phụ thuộc vào diện tích, vị trí, số phòng ngủ...
Tuy thế, giá nhà không phải lúc nào cũng tuân thao một đường thẳng liên tục, nên phương pháp này không áp dụng được ở hầu hết các trường hợp. Các nhà nghiên cứu đã nghĩ ra rất nhiều thuật toán có thể xử lý dữ liệu bất tuyến tính như mạng nơ-ron, SVM, hay kernel. Cũng có rất nhiều cách sử dụng hồi quy tuyến tính thông minh hơn, tìm ra đường thẳng phức tạp phù hợp hơn với dữ liệu. Trong tất các trường hợp, mục đích vẫn là tìm trọnng số tốt nhất để giảm mất mát
Tôi cũng đã lờ đi ý tưởng về overfitting - quá khớp. Không quá khó để tìm được hàm số phù hợp cho tất cả các điểm dữ liệu nhà đất trong tập ban đầu, nhưng hàm số đó lại không thể dự đoán đúng cho dữ liệu mới. Lý do là tập dự liệu luôn tồn tại nhiễu (1 vài ngôi nhà đặc biệt có giá quá cao, hay quá thấp). Nếu cố gắng tạo ra hàm đúng với tất cả các điểm, thì hàm đã bị thiên kiến bởi các điểm đặc biệt này và không có khả năng dự đoán giá trị trong tương lai. Một số cách để hạn chế overfitting như regularization hay cross validation. Tìm hiểu phương pháp loại bỏ overfitting là một phần quan trọng để áp dụng thành công các thuật toán học máy.
Nói một cách khác, trong khi lý thuyết cơ bản rất đơn giản, để áp dụng học máy và nhận được kết quả hữu ích cần nhiều kĩ năng và kinh nghiệm. Nhưng đó là các kĩ năng mà mọi lập trình viên đều có thể học.
Liệu học máy có thật sự thần thông?
Khi bạn nhìn thấy những thuật toán học máy được áp dụng dễ dàng để giải quyết các vấn đề rất phức tạp (như nhận diện chữ viết), bạn bắt đầu cảm thấy bạn có thể sử dụng học máy để giải quyết bất kể vấn đề nào và nhận được câu trả lời, miễn là bạn có tập dữ liệu đủ lớn. Chỉ cần đưa dữ liệu vào và bằng một cách thần thông nào đó, máy tính đưa ra hàm số phù hợp với dữ liệu.
Nhưng hãy nhớ rằng, học máy chỉ hiệu quả nếu vấn đề thực sự có thể giải quyết bằng dữ liệu bạn đưa vào.
Ví dụ, nếu bạn xây dựng mô hình dự đoán giá nhà dựa trên số giỏ cây ở mỗi nhà, hàm số tìm được sẽ không thể áp dụng. Không có bất kể mối liên hệ nào giữa số giỏ cây và giá nhà. Bạn chỉ có thể mô hình hóa mối quan hệ thực sự tồn tại giữa các đại lượng
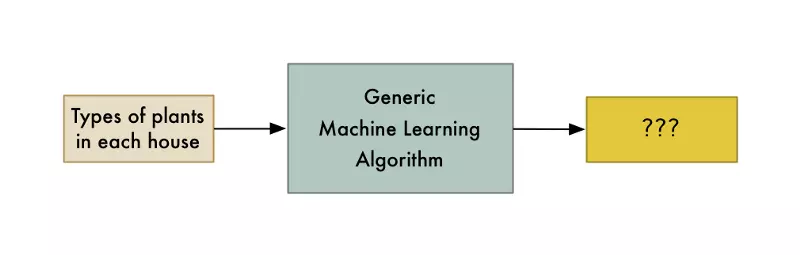
Nếu chuyên gia không thể sử dụng dữ liệu để giải quyết vấn đề, máy tính cũng sẽ không thể. Hãy tập trung vào vấn đề con người có thể giải quyết được, nhưng máy tính có thể giải quyết nhanh chóng hơn rất nhiều
Tìm hiểu thêm về Machine Learning
Khóa học cơ bản về Machine Learning được coi là kinh thánh (hầu hết mọi nguồn học thuật đều gợi ý) là khóa Machine Learning của giáo sư Andrew Ng
Tác giả Adam Geitgey của chuỗi bài viết cũng tạo 1 khóa học miễn phí trên Lynda, hiển thị tất cả các dòng code của loạt bài này. Nếu bạn quan tâm, bạn có thể đăng ký link này để có tài khoản Lynda thử nghiệm trong 30 ngày (link tài khoản thử nghiệm do tác giả cung cấp).
Ngoài ra, ở Việt Nam, có trang web Machine Learning cơ bản trình bày mọi kiến thức bài bản và khoa học, với hình minh họa đầy đủ.
Sau khi dịch series này, mình cũng sẽ viết 1 series "Học hiểu về Machine Learning" đúc rút những kiến thức nền tảng mình học được, hy vọng series có thể sẽ hữu ích với ai đó.
Nguồn
Bản gốc: https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471 Bản dịch của tác giả Hồ Văn Tuấn: https://viblo.asia/p/machine-learning-that-thu-vi-ByEZk7QqZQ0
Nếu các bạn thấy hứng thú với series này, các bạn có thể follow mình hoặc clip series để nhận được thông báo khi có bản dịch mới nhất. Series hiện có 8 bài, những bản dịch tiếp theo sẽ được cập nhật dần dần
All rights reserved
