Machine Learning thật thú vị (7): Tại sao Machine Learning vẫn chưa thể so sánh với bộ não con người? - mô hình DCGANs
Bài đăng này đã không được cập nhật trong 4 năm
Một trong những khả năng tuyệt vời nhất của con người chính là khả năng tưởng tượng. Có những người ta chưa gặp bao giờ, nhưng nếu ai đó đưa ta ảnh của nửa khuôn mặt người đó, ta hoàn toàn có thể dự đoán ra hình ảnh của cả khuôn mặt. Thậm chí, con người hoàn toàn có thể tưởng tượng ra toàn bộ một câu chuyện không có thật, hay hình dung về một câu chuyện mà ai đó kể cho chúng ta. Đó là common sense (trí thông minh cơ bản) mà bất kể ai trong chúng ta cũng có - theo Yann Lecun - tại sao bộ não học nhanh như vậy
Nhưng điều đó không/ chưa tồn tại trong bộ não của máy tính. Để nhận diện, phân tích bất cứ điều gì, máy tính cần hàng triệu dữ liệu, và khả năng dự đoán, chỉ gói gọn trong tập dữ liệu đó mà thôi. Và đó là lý do, một mô hình Deep Learning mới phát triển - mô hình sinh mẫu.
Hơn một năm trước, bài báo khoa học của Alec Radford đã thay đổi cách mọi người nghĩ về mô hình sinh mẫu trong học máy. Hệ thống mới được gọi là Deep Convolutional Generative Adversarial Networks (DCGANs - mình tạm dịch là mạng đối kháng sinh mẫu tích chập đa lớp).
Đối kháng (Adversarial): trong quá trình xây dựng mô hình có 2 mạng chạy đối lập nhau, cố gắng làm tốt hơn mạng còn lại. Sinh mẫu (Generative): tìm hiểu cách thức dữ liệu được hình thành, sau đó đặt câu hỏi: dựa vào giả định cách thức tạo ra dữ liệu, dữ liệu sẽ được phân vào nhóm nào?. Đối nghịch với sinh mẫu là Phân biệt (Discriminative): không quan tâm đến cách thức dữ liệu được tạo ra, chỉ phân loại dựa trên đầu vào dữ liệu. Tích chập (Convolutional): quá trình trích lọc đặc trưng dữ liệu thông qua cửa sổ trượt với trọng số không đổi
DCGANs đã giúp tạo ra những bức ảnh rất giống với thực tế bằng cách sử dụng tổ hợp 2 mạng nơron đa lớp đối kháng nhau. Tất cả những bức ảnh phòng ngủ dưới đây đều được vẽ lên bởi DCGAN:
 Những nhà nghiên cứu AI (trí thông minh nhân tạo) quan tâm tới generative model - mô hình sinh mẫu, bởi chúng dường như là cánh cửa tiếp theo để xây dựng hệ thống AI có sự hiểu biết về dữ liệu được tiếp nhận.
Những nhà nghiên cứu AI (trí thông minh nhân tạo) quan tâm tới generative model - mô hình sinh mẫu, bởi chúng dường như là cánh cửa tiếp theo để xây dựng hệ thống AI có sự hiểu biết về dữ liệu được tiếp nhận.
Chúng ta sẽ cùng nhau sử dụng mô hình sinh mẫu để làm điều gì đó tưởng chừng hơi điên khùng - tạo hình ảnh cho trò chơi điện tự 8-bit.
Mục đích của mô hình sinh mẫu
Tại sao các nhà nghiên cứu AI lại muốn xây dựng hệ thống để tạo ra hình ảnh không được rõ của phòng ngủ? Ý tưởng chính là: nếu bạn biết cách tạo ra bức ảnh, bạn phải hiểu về nó chứ.
Hãy nhìn vào bức ảnh sau:
 Ngay lập tức, bạn biết đây là hình ảnh của một chú chó - một loài vật có 4 chân và có đuôi. Nhưng với máy tính, hình ảnh chỉ là mạng lưới các con số đại diện cho màu sắc từng pixel. Máy tính không có khả năng hiểu rằng bức ảnh đại diện cho một khái niệm.
Ngay lập tức, bạn biết đây là hình ảnh của một chú chó - một loài vật có 4 chân và có đuôi. Nhưng với máy tính, hình ảnh chỉ là mạng lưới các con số đại diện cho màu sắc từng pixel. Máy tính không có khả năng hiểu rằng bức ảnh đại diện cho một khái niệm.
Nhưng hãy tưởng tượng, sau khi chúng ta chỉ ra cho máy tính hàng nghìn bức ảnh của chó, máy tính có khả năng tự tạo ra những bức ảnh mới với nhiều loài chó và góc độ khác nhau. Chúng ta thậm chí còn có thể yêu cầu nó tạo ra một bức hình cụ thể: "góc nhìn ngang của chó Becgie".
Nếu máy tính có thể làm điều đó, và bức ảnh tạo ra có đúng số chân, đuôi, tai, điều đó chứng tỏ máy tính biết phần nào bức ảnh là của con chó. Một cách nào đó, mô hình sinh mẫu tốt là bằng chứng của sự hiểu cơ bản của học máy - với trình độ đứa trẻ tập đi.
Đó là lý do tại sao các nhà khoa học lại rất phấn khích xây dựng mô hình sinh mẫu. Dường như có một cách để đào tạo máy tính mà không cần dạy chúng ý nghĩa của những khái niệm, và đó là một bước đi dài so với hệ thống hiện tại - học từ dữ liệu được gán nhãn trước bởi con người.
Nếu tất cả nghiên cứu này tạo ra chương trình tự động tạo ra ảnh loài chó, sau bao nhiêu năm nữa, chúng ta có thể có một cuốn lịch về các loài chó hoàn toàn được tạo bởi máy tính?
 Và nếu như chúng ta xây dựng chương trình có thể hiểu về loài chó, tại sao không hiểu về những điều khác nữa. Sao không phải là một chương trình tạo ra kho ảnh vô hạn mọi người bắt tay nhau? Tôi tin là ai đó sẽ trả tiền cho kho ảnh:
Và nếu như chúng ta xây dựng chương trình có thể hiểu về loài chó, tại sao không hiểu về những điều khác nữa. Sao không phải là một chương trình tạo ra kho ảnh vô hạn mọi người bắt tay nhau? Tôi tin là ai đó sẽ trả tiền cho kho ảnh:
 Dựa vào tốc độ phát triển của mô hình sinh mẫu trong vài năm vừa qua, ai biết được điều gì sẽ chờ đợi trong 5 hay 10 năm nữa. Chuyện gì sẽ xảy ra nếu ai đó phát minh ra hệ thống tạo ra một bộ phim hoàn chỉnh? hay âm nhạc? hay trò chơi điện tử?
Dựa vào tốc độ phát triển của mô hình sinh mẫu trong vài năm vừa qua, ai biết được điều gì sẽ chờ đợi trong 5 hay 10 năm nữa. Chuyện gì sẽ xảy ra nếu ai đó phát minh ra hệ thống tạo ra một bộ phim hoàn chỉnh? hay âm nhạc? hay trò chơi điện tử?
Nếu bạn nghĩ về 20-30 năm nữa, bạn có thể tưởng tượng một thế giới mà 100% hoạt động giải trí đều được tạo ra nhờ máy tính.
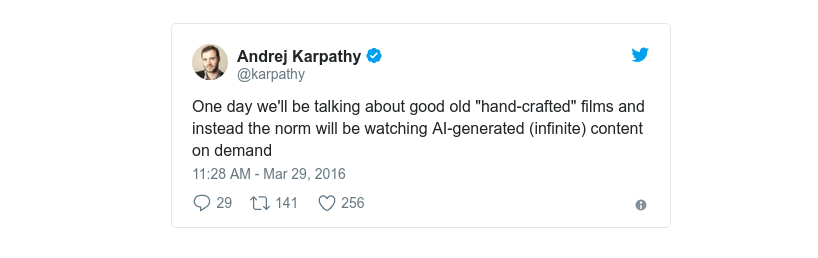
Dịch: Rồi một ngày, chúng ta nói về những bộ phim do con người thủ vai của những ngày xưa cũ; trong khi đang theo dõi những bộ phim máy tính tạo ra dựa trên nhu cầu.
Ngành trò chơi điện tử là lĩnh vực đầu tiên bắt đầu nghiêm túc thử nghiệm với AI để tạo ra nội dung. Chúng ta vẫn đang ở thuở sơ khai của mô hình mẫu sinh dựa trên học máy, và tính ứng dụng thực tế vẫn khá hẹp. Tuy thế, vẫn rất thú vị khi chúng ta tìm hiểu về nó. Hãy cùng nhau bắt đầu thôi nào!
DCGANs hoạt động như thế nào?
Để tạo ra DCGAN, chúng ta cần tạo ra 2 mạng nơron đa lớp, cho chúng cạnh tranh với nhau, và cố gắng làm tốt hơn đối thủ. Trong quá trình đó, cả 2 mạng sẽ cùng trở lên tốt hơn.
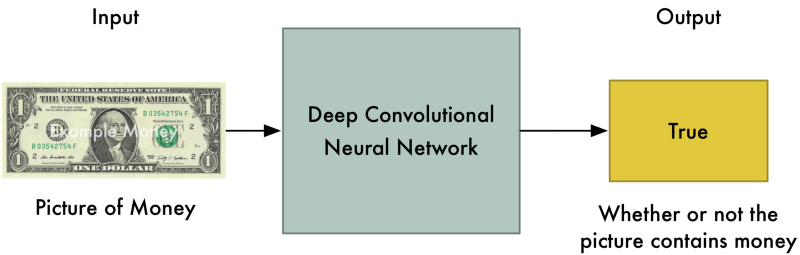
Tưởng tượng rằng mạng nơron đa lớp thứ 1 là một viên cảnh sát được đào tạo để phát hiện tiền giả. Nhiệm vụ của cảnh sát là nhìn vào bức tranh và nói cho chúng ta biết bức ảnh chứa tiền thật hay không.
Vì mục tiêu năm ở trong ảnh, chúng ta sử dung Convolutional Neural Network (CNN). Ý tưởng chính là mạng nơron nhận vào hình ảnh, xử lý qua nhiều lớp ẩn và lấy ra đặc trưng phức tạp từ ảnh, rồi trả ra một giá trị. Trong trường hợp này, giá trị biểu thị liệu ảnh có chứa tiền thật hay không.
Mạng thứ 1 có tên gọi là Discriminator - người phân biệt:
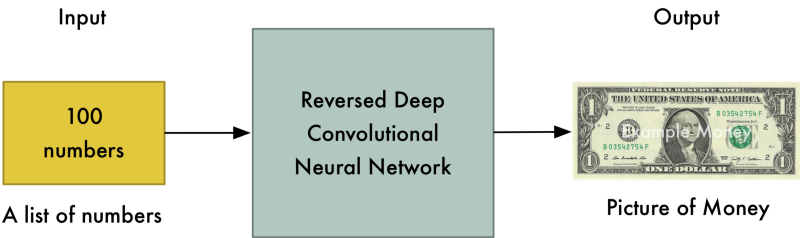
 Ta lại tưởng tượng mạng thứ 2 là kẻ lừa đảo, cố gắng học cách tạo tiền giả. Với mạng thứ 2, ta đảo ngược các lớp ẩn ở mạng thứ nhất để chương trình chạy ngược. Mạng này nhận một chuỗi các giá trị và trả kết quả là một bức ảnh.
Mạng thứ 2 có tên gọi là Generator - người sinh mẫu:
Ta lại tưởng tượng mạng thứ 2 là kẻ lừa đảo, cố gắng học cách tạo tiền giả. Với mạng thứ 2, ta đảo ngược các lớp ẩn ở mạng thứ nhất để chương trình chạy ngược. Mạng này nhận một chuỗi các giá trị và trả kết quả là một bức ảnh.
Mạng thứ 2 có tên gọi là Generator - người sinh mẫu:
Ở vòng thứ 1, người sinh mẫu - kẻ lừa đảo tạo ra đồng tiền chẳng giống tiền, bởi vì nó không có chút ý tưởng nào về đồng tiền thật.
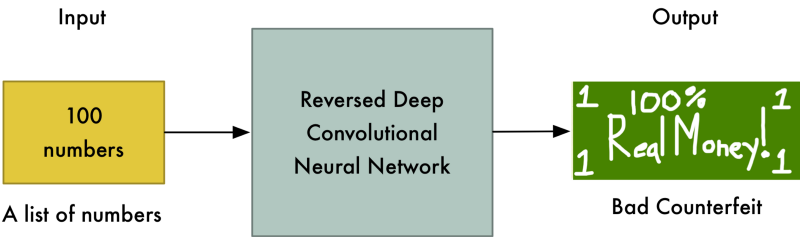 Nhưng bởi vì giờ đây, người phân biệt - viên cảnh sát cũng rất kém trong việc nhận diện tiền thật, nên nó cũng không nhận ra sự sai khác.
Nhưng bởi vì giờ đây, người phân biệt - viên cảnh sát cũng rất kém trong việc nhận diện tiền thật, nên nó cũng không nhận ra sự sai khác.
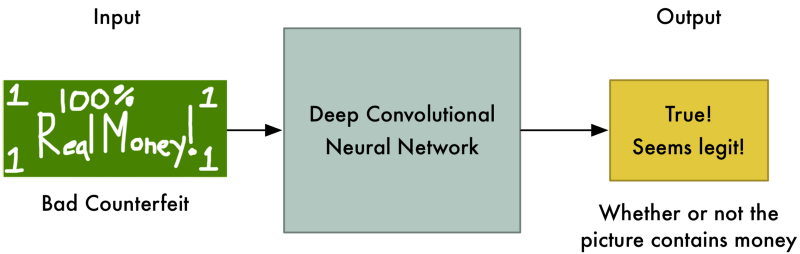 Lúc này, chúng ta can thiệp và nói với viên cảnh sát rằng tờ tiền là giả. Chúng ta đưa ra đồng tiền thật và yêu cầu nó tìm điểm khác biệt. Cảnh sát cố gắng tìm chi tiết để phân biệt 2 tờ tiền.
Lúc này, chúng ta can thiệp và nói với viên cảnh sát rằng tờ tiền là giả. Chúng ta đưa ra đồng tiền thật và yêu cầu nó tìm điểm khác biệt. Cảnh sát cố gắng tìm chi tiết để phân biệt 2 tờ tiền.
Ví dụ: cảnh sát có thể chú ý rằng tiền thật có mặt người và tiền giả không. Sử dụng kiến thức này, cảnh sát biết phân biệt tiền giả, và làm tốt công việc hơn:
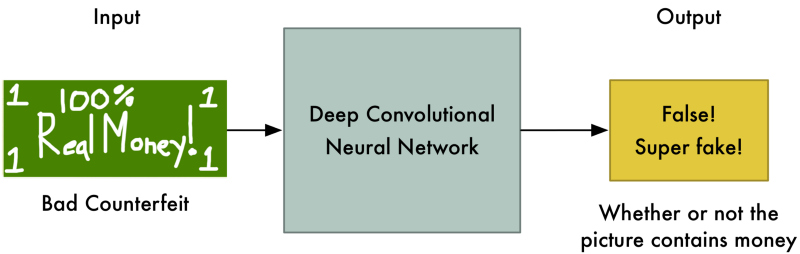 Ở vòng 2, kẻ lừa đảo biết rằng tờ tiền ban đầu đã bị từ chối, và biết rằng cảnh sát tìm kiếm khuôn mặt trên bức ảnh, cách tốt nhất để lừa viên cảnh sát là tạo khuôn mặt trên bức ảnh.
Ở vòng 2, kẻ lừa đảo biết rằng tờ tiền ban đầu đã bị từ chối, và biết rằng cảnh sát tìm kiếm khuôn mặt trên bức ảnh, cách tốt nhất để lừa viên cảnh sát là tạo khuôn mặt trên bức ảnh.
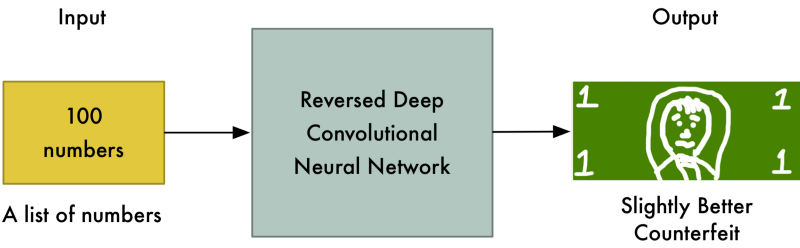 Tờ tiền giả lại được chấp nhận lần nữa! Cảnh sát lại phải nhìn vào tờ tiền thật để tìm ra điểm nhận dạng khác biệt so với tiền giả.
Tờ tiền giả lại được chấp nhận lần nữa! Cảnh sát lại phải nhìn vào tờ tiền thật để tìm ra điểm nhận dạng khác biệt so với tiền giả.
Quá trình này lặp lại liên tục hàng nghìn lần cho tới khi cả viên cảnh sát và kẻ lừa đảo đều trở thành chuyên gia. Cuối cùng, kẻ lừa đảo tạo ra tiền giả giống như thật, và cảnh sát cũng rất giỏi tìm ra những lỗi dù là bé nhất.
Đến thời điểm này, cả cảnh sát và kẻ lừa đảo đều đã được đào tạo đủ đến nỗi mà con người cũng khó phát hiện ra tờ tiền giả từ máy tính.
Mọi người có thấy quá trình này giống quá trình mà loài người đã trải qua đế tiến hóa không? Mình thì thấy nó giống với thuyết tiến hóa của Darwin, khi những cá thể yếu kém bị loại bỏ, những cá thể mạnh tiếp tục phát triển. Tương tự, trong mạng sinh mẫu, những nhận diện chuẩn xác được giữ lại, những phân biệt kém không được chấp nhận. Con người đã trải qua hàng chục ngàn năm để được như bây giờ. Thế mới thấy, sự tiến hóa của máy tính nhanh đến mức nào!!!
Áp dụng vào trò chơi điện tử
Giờ chúng ta đã biết cách thức DCGANs hoạt động, hãy xem cách chúng ta dùng nó để tạo ra trò chơi điện tử thế hệ 1980s.
Ý tưởng là chúng ta cố gắng tạo ra ảnh chụp màn hình của trò chơi điện tử tưởng tượng, rồi sao chép từng bits trong những ảnh chụp này để tạo ra những trò chơi theo phong cách cổ xưa. Vì trò chơi máy tạo chưa bao giờ tồn tại, nó có vẻ sẽ không bị coi là ăn cắp bản quyền  ).
).
Thiết kế trò chơi thời kì ban đầu rất đơn giản. Vì hệ thống trò chơi của Nintendo (NES) có rất ít bộ nhớ (thậm chí còn ít bộ nhớ hơn bài viết này), những lập trình viên phải sử dụng rất nhiều thủ thuật để có thể lưu thiết kế vào bộ nhớ. Để tối đa không gian, trò chơi sử dụng các mảnh ghép đồ họa 16x16 pixel, và tái sử dụng nhiều lần. Ví dụ, màn hình trò chơi "Huyền thoại Zelda" được tạo nên bởi 8 mảnh:
 Và đây là những mảnh cho toàn bộ sơ đồ trò chơi. Thỉnh thoảng, lập trình viên thay đổi màu sắc để tạo ra các khu vực khác nhau, nhưng thực ra thiết kế mảnh ghép không đổi.
Và đây là những mảnh cho toàn bộ sơ đồ trò chơi. Thỉnh thoảng, lập trình viên thay đổi màu sắc để tạo ra các khu vực khác nhau, nhưng thực ra thiết kế mảnh ghép không đổi.

Chúng ta sẽ để máy tính tạo ra các mảnh ghép cho trò chơi, và không quan tâm liệu bố cục bức ảnh được tạo có giống với thực tế không. Thay vào đó, chúng ta tìm hình dáng và cấu trúc mảnh 16x16 mà chúng ta có thể sử dụng trong trò chơi như hòn đá, nước, cầu... Sau đó, chúng ta có thể sử dụng các mảnh này để tạo nên các mức độ khác nhau của trò chơi.
Mục tiêu: sinh mẫu các mảnh ghép trong trò chơi
Thu thập dữ liệu
Để đào tạo mô hình, chúng ta cần rất nhiều dữ liệu. May mắn là có hơn 700 trò chơi của NES mà ta có thể lấy về.
Tôi sử dụng wget để tải về toàn bộ màn hình trò chơi NES trên website. Sau vài phút tải, tôi có hơn 10,000 ảnh chụp.
 Hiện tại, DCGANs chỉ hoạt động trên ảnh nhỏ - cỡ 256x256 pixels. Nhưng vì màn hình ảnh của NES là 256x224, để cho đơn giản, tôi cắt ảnh còn 224x224 pixels.
Hiện tại, DCGANs chỉ hoạt động trên ảnh nhỏ - cỡ 256x256 pixels. Nhưng vì màn hình ảnh của NES là 256x224, để cho đơn giản, tôi cắt ảnh còn 224x224 pixels.
Cài đặt DCGAN
Có rất nhiều cài đặt mã nguồn mở của DCGANs trên github mà bạn có thể thử. Tôi sử dụng bản cài đặt trên Tensorflow của Taehoon Kim. Vì DCGANs là thuật toán học không giám sát, tất cả những gì bạn cần làm là đưa dữ liệu, khởi tạo tham số ban đầu, bắt đầu đào tạo và đợi kết quả.
Đây là mẫu của dữ liệu đào tạo gốc:
 Quá trình đào tạo bắt đầu! Đầu tiên, kết quả từ Generator chứa nhiều nhiễu. Nhưng từng phần bắt đầu hình thành khi Generator học cách làm công việc tốt hơn:
Quá trình đào tạo bắt đầu! Đầu tiên, kết quả từ Generator chứa nhiều nhiễu. Nhưng từng phần bắt đầu hình thành khi Generator học cách làm công việc tốt hơn:
 Sau một vài vòng đào tạo, chúng ta đã nhận ra được cấu trúc phiên bản quen thuộc của game Nintendo:
Sau một vài vòng đào tạo, chúng ta đã nhận ra được cấu trúc phiên bản quen thuộc của game Nintendo:
 Tiếp tục đào tạo, chúng ta có thể thấy tường và vật cản đã được hình thành. Chúng ta thậm chí còn thấy cả số máu hay những dòng chữ:
Tiếp tục đào tạo, chúng ta có thể thấy tường và vật cản đã được hình thành. Chúng ta thậm chí còn thấy cả số máu hay những dòng chữ:

Đây là lúc mọi thứ trở nên phức tạp. Làm thế nào chúng ta biết máy tính đang tạo ra bức ảnh mới, thay vì chỉ tái tạo lại trực tiếp từ ảnh đào tạo. Ở 2 trong những bức ảnh trên, bạn có thể nhìn thấy rõ thanh menu từ game Mario cùng thanh tiêu đề và hòn đá từ bản nguyền gốc.
Tái tạo lại dữ liệu đào tạo hoàn toàn có thể xảy ra. Sử dụng tập dữ liệu đào tạo lớn và không đào tạo quá lâu, ta có thể giảm khả năng điều này xảy ra. Đây là vấn đề nhức nhối vẫn đang được các nhà khoa học nghiên cứu.
Vì muốn hình ảnh đẹp hơn, tôi tinh chỉnh mô hình cho tới khi nó tạo được thiết kế có vẻ giống nguyên gốc. Nhưng tôi không thể biết được đây là thiết kế hoàn toàn mới hay không, trừ phi so sánh với tất cả ảnh trong tập đào tạo.
Sau một vài giờ huấn luyện, ảnh máy tạo chứa các mảnh 16x16 trông khá ổn. Tôi thêm một chút thay đổi vào vật cản, mẫu đá, nước, bụi cây...
Tiếp đến, tôi cần tiền xử lý ảnh được tạo để chắc chắn rằng chúng chỉ chứa 64 màu hiển thị được trên NES.
 Sau đó, tôi mở ảnh 64 màu ra ở trong Tiled Map Editor và lấy ra các mảnh 16x16 phù hợp với các nhóm đối tượng khác nhau. Đây là những mảnh tôi đã lựa chọn sau khi bỏ đi những mảnh khó nhận diện.
Sau đó, tôi mở ảnh 64 màu ra ở trong Tiled Map Editor và lấy ra các mảnh 16x16 phù hợp với các nhóm đối tượng khác nhau. Đây là những mảnh tôi đã lựa chọn sau khi bỏ đi những mảnh khó nhận diện.
 Sử dụng Editor trên, tôi sắp xếp các mảnh 16x16 lựa chọn phía trên thành các lớp tương tự như trò chơi "Castlevania"
Sử dụng Editor trên, tôi sắp xếp các mảnh 16x16 lựa chọn phía trên thành các lớp tương tự như trò chơi "Castlevania"

Lưu ý là ở bài này, tác giả cố gắng tìm thiết kế của các mảnh, và không quá quan tâm đến việc liệu học máy có tạo ra được bố cục trò chơi chính xác hay không.
Ảnh trông khá ổn. Hãy nhớ rằng chúng ta không chỉnh sửa bất cứ pixel nào trong từng mảnh 16x16 đó. Tất cả các mảnh đều được lấy ra trực tiếp từ mô hình DCGAN
Tiếp đến, hãy thêm nhân vật chính và một vài kẻ thù. Dưới đây là hình ảnh trong trò chơi khi đã được thêm cả thanh menu:
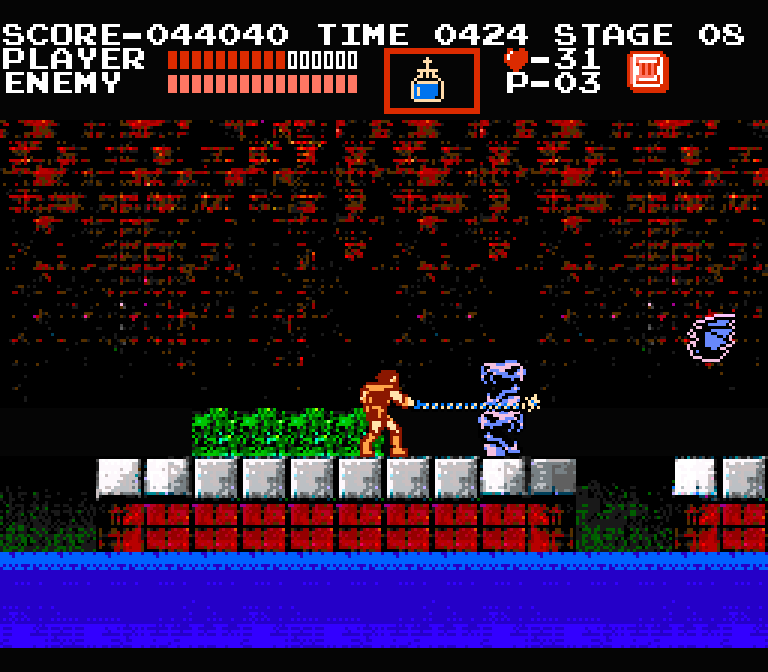 Khá giống trò chơi thực tế phải không nào!!
Khá giống trò chơi thực tế phải không nào!!
Lời kết
Tôi thực sự cảm thấy phấn khích với mô hình sinh mẫu. Ý tưởng của một ngày làm việc nghệ thuật không ngừng rất cuốn hút tôi. Nhưng khi mà tôi nói với mọi người về vấn đề này, một số người trả lời: "Thế này vẫn quá đơn giản".
Có rất nhiều niềm hy vọng xung quanh mô hình sinh mẫu. Generative Adversarial Networks - GANs được gọi là tương lai của AI, mặc dầu mô hình khó đào tạo và chỉ giới hạn ở ảnh nhỏ. Thực tế, mô hình tốt nhất chỉ có thể tạo ra ảnh chó đột biến kích thước nhỏ như tem thư.
 Nhưng chỉ một vài năm trước, chúng ta còn không thể làm được điều đó. Chúng tôi đã cực kỳ phấn khích chỉ với bức ảnh như thế này thôi:
Nhưng chỉ một vài năm trước, chúng ta còn không thể làm được điều đó. Chúng tôi đã cực kỳ phấn khích chỉ với bức ảnh như thế này thôi:
 Và công nghệ cải thiện từng ngày. Một vài bài báo xuất hiện gần đây đã sử dụng GANs để già hóa khuôn mặt con người.
Và công nghệ cải thiện từng ngày. Một vài bài báo xuất hiện gần đây đã sử dụng GANs để già hóa khuôn mặt con người.
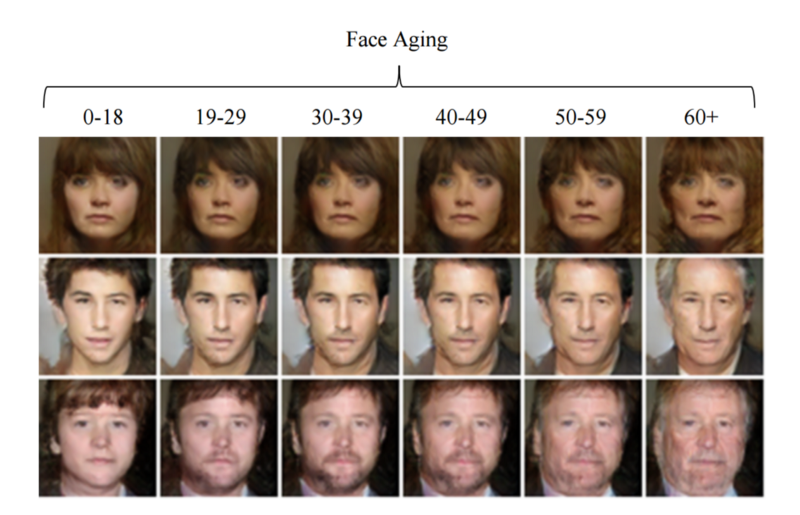 Nếu mọi thứ cứ tiếp tục cải thiện ở tốc độ này, không lâu sau nữa, mô hình sinh mẫu sẽ có khả năng sáng tạo như con người. Đây chính là thời kỳ tuyệt vời để bắt tay vào thử nghiệm!!!
Nếu mọi thứ cứ tiếp tục cải thiện ở tốc độ này, không lâu sau nữa, mô hình sinh mẫu sẽ có khả năng sáng tạo như con người. Đây chính là thời kỳ tuyệt vời để bắt tay vào thử nghiệm!!!
Nguồn
All rights reserved
