Hiểu về Clustered index
Bài đăng này đã không được cập nhật trong 6 năm
Hẳn các bạn cũng đã từng nghe về 2 loại index là Clustered Index và Non-clustered index.
Dạo một vòng tìm các định nghĩa trên Google, chắc các bạn cũng sẽ tìm được cách phân biệt đơn giản đó là: Clustered index được tạo ra trên một table với primary key, còn non clustered thì đơn giản là cho các key còn lại không phải là primary key. Câu trả lời này liệu đã đủ sức thuyết phục?
Bài viết hôm nay mình xin được giới thiệu cách hiểu của mình về clustered index và non-clustered index.
Clustered index
Vậy clustered index là gì? Liệu nó có phải đơn giản là loại index được đánh trên primary key của một table?
Clustered index định nghĩa thứ tự mà dữ liệu được lưu trữ vật lý trong một bảng.
Hiểu một cách thông thường, khi bạn đánh index cho 1 trường trong tables, các giá trị của trường đó sẽ được tổ chức lưu trữ có cấu trúc (thông thường sẽ sử dụng B-Tree), kết quả tìm kiếm trên B-Tree index sẽ trả về row pointer tới record bạn đang muốn tìm.
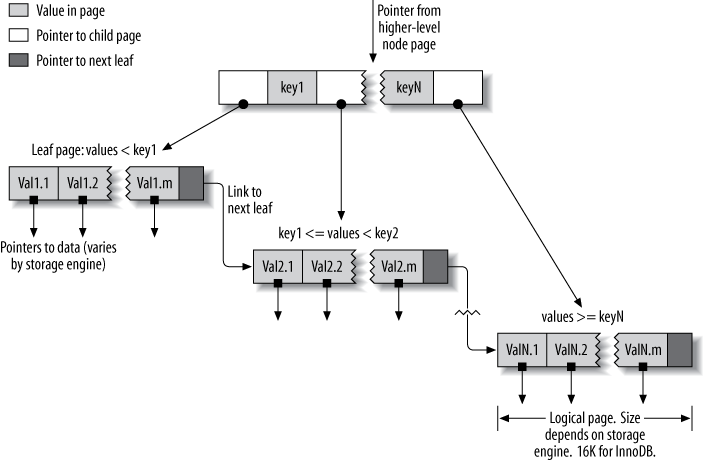
Tuy nhiên, với clustered index, toàn bộ row sẽ được lưu có cấu trúc ngay trên B-Tree index, tức là sau khi tìm kiếm với field được đánh clustered index trên B-Tree kết quả trả về chính là record bạn muốn tìm.
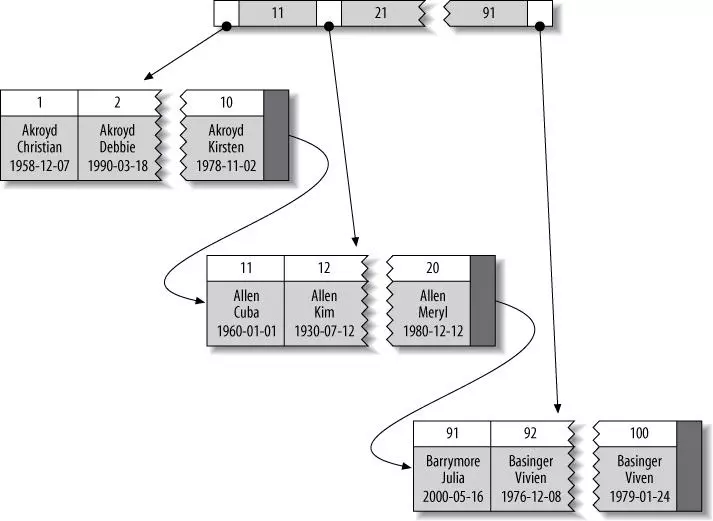
Có một lưu ý là, toàn bộ dữ liệu của 1 row sẽ được lưu ngay trên node lá của B Tree, nhưng những node trung gian sẽ chỉ lưu giá trị của cột được đánh index. Mỗi table chỉ nên có 1 clustered index, bởi vì clustered index lưu toàn bộ dữ liệu trong 1 row và bạn không nên lưu những dữ liệu này ở nhiều nơi một lúc.
Clustered index trên InnoDB
Bởi vì việc thực thi index được đảm nhiệm bởi các storage engines, vì vậy không phải storage engine nào cũng support clustered index. Trong bài viết này mình sẽ nói về việc thực thi clustered index trong InnoDB, những storage engines khác đôi lúc sẽ có những cách thực thi khác biệt tuy nhiên về nguyên tắc hoạt động thì nó vẫn sẽ tương tự nhau.
Trong InnoDB, mặc định cột được đánh primary key sẽ cũng là "index column" cho việc clusters dữ liệu. Bởi nguyên nhân này, các bạn thường nghe nói "Clustered index được tạo ra trên một table với primary key".
Tuy nhiên nếu trong 1 table mà bạn không đánh primary key thì phải sử dụng cột nào để build clustered index. Câu trả lời là: InnoDB chọn column để "chọn mặt gửi vàng" cho việc clustered index theo thứ tự ưu tiên như sau:
- Đầu tiên, như đã đề cập ở trên, InnoDB sẽ mặc định chọn Primary Key làm "index column"
- Nếu table không có khai báo Primary key, InnoDB sẽ tìm kiếm cột nào thỏa mãn điều kiện Unique và Not null để thay thế
- Nếu trong table đó vẫn không có cột nào Unique và Not null, InnoDB sẽ dùng cách cuối cùng là tự define một hidden primary key và cluster data trên cái cột này.
Non clustered index
Với cách lưu trữ index thông thường, dữ liệu sẽ được lưu ở một vùng nhớ nào đó và những node lá cuối cùng của B Tree sẽ chứa con trỏ tới đúng record muốn tìm. Tuy nhiên với clustered index, dữ liệu được tổ chức lưu trữ ngay trên B Tree. Primary key chính là "index column" được chọn để thực hiện clusters. Vậy những cột còn lại khi được đánh index nó sẽ lưu trữ như thế nào?
Trong InnoDB, tất cả những index còn lại mà không phải là clustered index thì sẽ chứa giá trị của clustered index tương ứng. Có nghĩa là, khi bạn thực hiện tìm kiếm với cột nonclustered index, hệ thống sẽ tìm kiếm trên B Tree index của cột đó, kết quả trả về là clustered index tương ứng, hệ thống sẽ tiếp tục quét B Tree của clustered index và trả về đầy đủ dữ liệu.
Giả sử bạn có 1 table gồm ID, FName, LName. Trong đó ID là PK, bạn đánh index cho trường FName thì InnoDB sẽ build 2 B Tree như sau
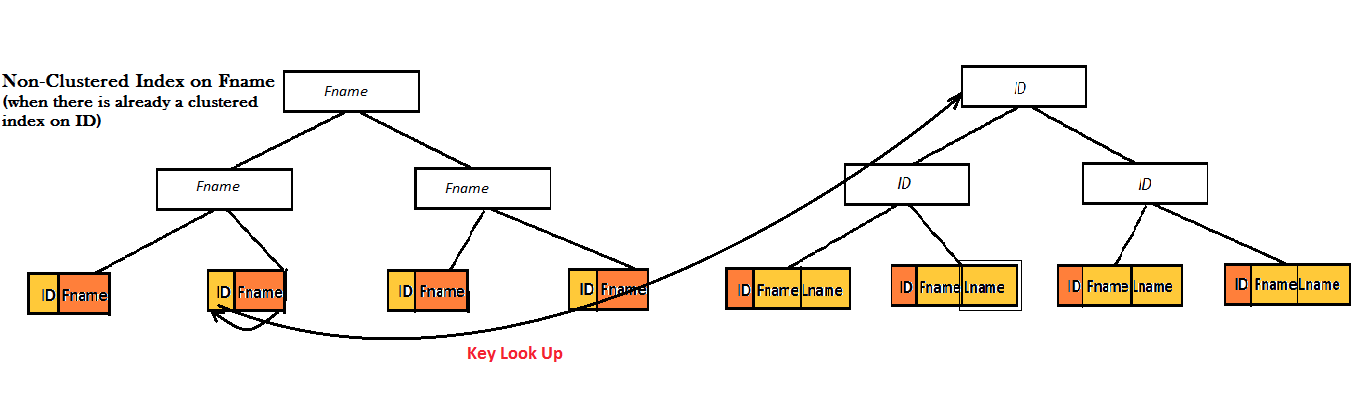
Khi thực hiện câu lệnh
select * from tables where FName = ?
thì InnoDB sẽ thực hiện tìm kiếm trên B Tree của FName, sau khi tìm được node lá tương ứng thì nó tiếp tục cầm giá trị của node lá này (chính là key của clustered index) để quét trên B Tree của ID (clustered index) và trả về giá trị đầy đủ của truy vấn.
Lưu ý khi chọn cột đánh clustered index
Việc sử dụng clustered index sẽ giúp tăng tốc độ truy cập dữ liệu. Bởi vì clustered index lưu trữ index và dữ liệu ngay trên B Tree. Record sẽ được trả về ngay sau khi thực hiện quét B Tree kết thúc thay vì phải tìm kiếm đến row pointer như bình thường, cải thiện I/O-bound workloads.
Tuy nhiên, nếu sử dụng không đúng cách, clustered index sẽ làm performance giảm đáng kế:
- Tốc độ insert vào cluster phụ thuộc vào vị trí muốn insert vào. Vì bản chất index là được lưu trữ có thứ tự, khi insert 1 record mới sẽ phải tìm kiếm vị trí phù hợp để insert vào thay vì insert vào ô nhớ khả dụng tiếp theo như cách thông thường.
- Chi phí cho việc cập nhật cột được đánh clustered index sẽ rất đắt, bởi vì InnoDB cũng sẽ phải move toàn bộ row tương tứng đến vị trí mới.
- Table sử dụng clustered index có thể bị phân chia trang khi record mới được chèn vào, hoặc khi cột được đánh index bị cập nhật. Việc chia trang xảy ra khi một key sau khi tìm kiếm đúng vị trí order phải bắt buộc chèn vào vị trí trong page đã full data. Lúc này storage engine phải chia page này thành 2, và table sẽ sử dụng nhiều space trên đĩa hơn.
- Chính ví việc có thể bị phân trang ở trên, clustered tables sẽ chậm hơn khi thực hiện full table scan.
- Non clustered index có thể sẽ lớn hơn bình thường vì node lá của chúng lưu trữ giá trị từ clustered index, giá trị này càng lớn (ví dụ kiểu varchar) thì non clustered index sẽ lớn hơn.
Vậy thì sử dụng clustered index như thế nào cho đúng để tránh những hạn chế đã nêu trên?
Câu trả lời là bạn nên sử dụng field AUTO INCREASEMENT cho column được chọn làm clustered index. Vì sao? Bây giờ chúng ta hãy cùng thử so sánh việc chọn 1 field AUTO INCREASEMENT và một field có giá trị ngẫu nhiên thỏa mãn UNIQUE và NOT NULL (ví dụ UUID) làm clustered index và cùng phân tích performance của 2 trường hợp này tương ứng với những hạn chế nêu ở trên.
| Clustered index column | AUTO INCREASEMENT column | Random Column |
|---|---|---|
| Tốc độ insert | Khi giá trị của key được đánh index tự động tăng, new record chỉ cần insert vào vị trí cuối cùng. | Tìm kiếm ví trí phù hợp để chèn key và record vào |
| Chi phí cập nhật | Không nên thực hiện cập nhật cho cột được chọn đánh clustered index để tránh việc này | Không nên thực hiện cập nhật cho cột được chọn đánh clustered index để tránh việc này |
| Hạn chế phân trang | Với trường tự động tăng, record mới luôn được chèn vào vị trí cuối cùng, sẽ không có trường hợp chèn vào giữa những vị trí đã có data, nên storage engine không cần thực hiện những tác vụ phân trang lãng phí | Vì record mới sẽ được chèn vào ngẫu nhiên nên dẫn tới bị phân trang chiếm dụng nhiều space |
| Giảm kích thước của non clustered index | Thông thường trường tự động tăng sẽ có kiểu dữ liệu là Number, kích thước nhỏ hơn nhiều so với varchar | nếu kiểu dữ liệu là varchar càng lớn thì non clustered index sẽ phải tốn nhiều space hơn để lưu những giá trị này |
Từ những so sánh này có thể thấy, khi đánh clustered index nên chọn cột UNIQUE, NOT NULL, AUTO INCREASEMENT để có được hiệu quả tốt nhất. Thông thường, cột có tính chất như trên chính là cột ID được khai báo là Primary Key và InnoDB sẽ mặc định chọn nó làm clustered index column.
Hi vọng qua bài viết, các bạn hiểu rõ hơn về bản chất của clustered index thay vì cách hiểu hàn lâm thông thường là "Clustered index được tạo ra trên một table với primary key".
All rights reserved
