Tối ưu cơ sở dữ liệu cải thiện 97% thời gian thực hiện chỉ bằng một “chấm nhẹ” thế nào?
Bài đăng này đã không được cập nhật trong 3 năm
Đây là những bài viết về các dự án & kinh nghiệm tối ưu cơ sở dữ liệu của Wecommit. Những giá trị mà bạn sẽ nhận được khi đọc hết bài viết:
- Tư duy về tối ưu cơ sở dữ liệu
- Ví dụ đời sống cực dễ hiểu
- Phân tích chi tiết dưới góc độ của chuyên gia
- Bài viết sẽ liên tục được cập nhật
1. Thử thách mà rất nhiều lập trình viên, DBA gặp phải liên quan đến vấn đề tối ưu cơ sở dữ liệu hiện nay
Cơ sở dữ liệu gặp hiện tượng chậm, treo. Người dùng cuối và sếp liên tục than phiền. Các anh em kỹ thuật "hò" nhau lấy các câu lệnh ra để kiểm thử. Nhưng khi đem ra thử nghiệm thì kết quả nhận được rất oái oăm
- Cứ chạy từng câu lệnh riêng lẻ thì cực kỳ nhanh (mấy vài mili second)
- Tuy nhiên thực tế hệ thống PRODUCTION chạy nhiều câu lệnh đó cùng lúc thì lại cực kỳ chậm, thời gian chậm hơn vài chục lần đến hàng trăm lần.
Anh em lập trình lúc này về cơ bản sẽ rơi vào cảm giác "BẾ TẮC".
Một loạt các phỏng đoán nhảy ra trong đầu:
- Hạ tầng phần cứng chắc lởm quá, cần phải mở rộng phần cứng chăng?
- Có nên đổ lỗi cho ông NETWORK không, vì case này bí quá rồi?
- Cơ sở dữ liệu chắc gặp phải BUG.
- ...
Nhưng tất cả các câu hỏi đó đều không đưa đến phương án giải quyết gốc rễ của vấn đề.
2. Nếu bạn cũng đang gặp vấn đề này, tôi chúc mừng bạn vì bài viết này là dành cho bạn.
Bạn hãy đọc thật tập trung và đừng bỏ qua bất kỳ đoạn nào cả, bởi vì tất cả những gì tôi chia sẻ đều được chắt lọc qua kinh nghiệm dự án thực tế.
- Tối ưu cơ sở dữ liệu Core chứng khoán: HNX, TCBS, VCBS, HDBS, BVSC…
- Tối ưu cơ sở dữ liệu Core các ngân hàng: Ngân hàng VBSP, Ocean Bank, Ngân hàng Việt Nga, ngân hàng VDB, ngân hàng CBBank (Myanmar), ngân hàng Lào Việt Bank…
- Tối ưu cơ sở dữ liệu các hệ thống quản lý bệnh viện: hàng chục hệ thống HIS do VNPT cung cấp
- Tối ưu cơ sở dữ liệu các hệ thống viễn thông: Core billing của VNPT, Bitel (Peru)
- Thông tin về các dự án của chúng tôi có thể xem tại: https://wecommit.com.vn/du-an/
Trong bài viết này các bạn sẽ thấy 1 SAI LẦM NGHIÊM TRỌNG mà các anh em lập trình mắc phải, kèm với đó là GIẢI PHÁP MANG LẠI HIỆU QUẢ NGAY LẬP TỨC. Bạn sẽ thấy cách thức mà tôi đã cải thiện hiệu năng hàng trăm lần, thậm chí nhiều hệ thống cải thiện hàng nghìn lần như thế nào.
3. Giả lập bài toán cần tối ưu cơ sở dữ liệu
3.1. Môi trường & bảng dữ liệu cần xử lý
Môi trường trong bài toán sử dụng Cơ sở dữ liệu Oracle.
Bảng EMPLOYEES sử dụng để lưu thông tin của nhân viên trong một tập đoàn đa quốc gia.
Cấu trúc của bảng như sau:
CREATE TABLE HUYTQ.EMPLOYEES
(
EMP_ID NUMBER(10) NOT NULL,
FIRST_NAME VARCHAR2(20 BYTE),
LAST_NAME VARCHAR2(20 BYTE),
SALARY NUMBER,
NOTE VARCHAR2(50 BYTE),
ADDRESS VARCHAR2(100 BYTE),
GENDER NUMBER,
DOB NUMBER,
START_DATE DATE DEFAULT sysdate-1,
DEPTNO NUMBER
)
ALTER TABLE HUYTQ.EMPLOYEES ADD (
PRIMARY KEY
(EMP_ID)
USING INDEX
TABLESPACE DATA
ENABLE VALIDATE);
Bảng EMPLOYEES sử dụng khóa chính trên cột EMP_ID.
Tổng số bản ghi của bảng này là 1.100.016.
3.2. Bài toán về tối ưu cơ sở dữ liệu đang gặp phải
Hệ thống của chúng ta thường xuyên cần thực hiện câu lệnh tìm kiếm thông tin thông qua mã nhân viên (EMP_ID).
Thời điểm cao tải có thể có vài trăm nghìn session cùng thực hiện các câu lệnh tìm kiếm kiểu này.
select * from employees where emp_id=1;
select * from employees where emp_id=2;
....
select * from employees where emp_id=1044;
select * from employees where emp_id=1045;
select * from employees where emp_id=1046;
….
select * from employees where emp_id=9400;
Tôi sẽ giả lập việc chạy 100.000 câu lệnh này bằng cách chạy vòng lặp sau
SQL>
DECLARE
emp_rec employees%ROWTYPE;
BEGIN
FOR i IN 1 .. 100000
LOOP
BEGIN
EXECUTE IMMEDIATE 'select * from employees where emp_id = ' || i
INTO emp_rec;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
NULL;
END;
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:01:33.18
Đoạn lệnh trên có ý nghĩa như sau:
Thực thi lần lượt các câu lệnh dạng"select * from employees where emp_id = i" với i tăng dần từ 1 đến 100.000
Vòng lặp for sẽ giúp chúng ta tạo ra 100.000 câu lệnh và thực thi chúng, giả lập đúng với bài toán đưa ra.
Thời gian thực thi của toàn bộ tiến trình này là 93.18 giây.
3.3. Phân tích các câu lệnh chạy trong thủ tục trên.
Chúng ta có thể thấy rằng 100.000 câu lệnh thực thi với ý nghĩa và chiến lược hoàn toàn giống nhau.
Bây giờ ta thử xem xét 1 câu lệnh riêng lẻ
SQL> select * from employees where emp_id=1044;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2455998802
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 36 | 3 (0) | 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 36 | 3 (0) | 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C0011152 | 1 | | 2 (0) | 00:00:01 |
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMP_ID"=1044)
Câu lệnh này chạy chỉ mấy vài ms (thời gian cực kỳ nhanh).
Chiến lược thực thi của câu lệnh đã là tối ưu:
- Đầu tiên hệ thống sẽ tìm kiếm thông tin theo UNIQUE INDEX (do cột EMP_ID là PRIMARY KEY, hệ thống sẽ tự tạo 1 UNIQUE INDEX trên cột này).
- Do Index chỉ lưu thông tin của cột EMP_ID, nên Oracle sẽ phải thực hiện truy cập vào TABLE để lấy nôt các thông tin của những cột khác (vì người dùng yêu cầu SELECT * ). Đây chính là bước TABLE ACCESS BY INDEX ROWID
- Nếu bạn muốn tự mình có thể phân tích và hiểu tường tận về chiến lược thực thi của câu lệnh (Execution Plans) thì có thể đăng ký chương trình KEY PERSON COACHING - Chương Trình Tối Ưu Cơ Sở Dữ Liệu Thực Chiến.
**Như vậy, mỗi câu lệnh SQL đã được tối ưu hết mức. **
3.4. Phương án tối ưu trong trường hợp này là gì?
Trước khi đưa phương án, tôi muốn các bạn biết điều này.
Khi làm việc với Cơ sở dữ liệu, bạn có 2 cách thức.
- Cách 1: Truyền trực tiếp giá trị vào câu lệnh. Đây là cách trong ví dụ bên trên đã thực hiện. Chúng ta truyền luôn giá trị 1044 vào câu lệnh.
SQL> select * from employees where emp_id=1044;
- Cách 2: Truyền biến. Chúng ta sẽ đưa giá trị cần tìm kiếm vào 1 biến (ví dụ: biến :B1), khi thực hiện câu lệnh thì chúng ta sẽ khai báo cụ thể biến đó nhận giá trị bao nhiêu. Ví dụ như sau
select * from employees where emp_id=:B1
Khi thực hiện sẽ cần nhập giá trị của biến :B1 sau.
Hai cách thức trên đều trả ra cùng 1 kết quả.
Bây giờ, thay vì sử dụng cách thức truyền giá trị thực tiếp trong vòng lặp FOR lúc đầu tiên, tôi sẽ chỉnh lại bằng cách sử dụng biến.
SQL> DECLARE
emp_rec employees%ROWTYPE;
BEGIN
FOR i IN 1 .. 100000
LOOP
BEGIN
EXECUTE IMMEDIATE 'select * from employees where emp_id = :B1'
INTO emp_rec
USING i;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
NULL;
END;
END LOOP;
END
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:02.89
Wow, thời gian hiện tại chỉ còn 2.89s (chỉ bằng ~3.1% so với thời gian lúc đầu là 93s).
3.5. Giải thích cơ chế giúp kỹ thuật trên cải thiện hơn 97% trong việc tối ưu cơ sở dữ liệu.
Trước khi tôi giải thích tất cả nguyên lý trên một cách cặn kẽ, các bạn có thể xem một tình huống tương tự nhưng ở trong đời thường.
3.5.1 BÀI TOÁN TÌM ĐƯỜNG ĐẾN TRẠM Y TẾ ĐỂ TIÊM VACCINE COVID-19
Hôm nay phường Tây Mỗ cần thực hiện tiêm chủng vaccine phòng chống COVID-19. Đội y tế phường yêu cầu 100.00 hộ dân khu đô thị Vinhome Smart City ra đến trạm y tế phường để tiêm chủng. Những người dân tại khu vực này mới chuyển đến và đều không biết chính xác đường đi từ nhà ra đến trạm y tế phường.
Ở dưới tòa chung cư này có một chốt bảo vệ rộng 3m2, trong đó có một người thông thạo mọi con đường trong khu vực phường Tây Mỗ. Mỗi người dân của tòa chung cư này đều phải vào trong chốt bảo vệ để hỏi về con đường nào “ngắn nhất” đi từ nhà mình ra đến nơi tiêm chủng.
Ngày tiêm chủng đã tới, 100.000 hộ dân đều tụ tập xoay quanh chốt bảo vệ. Và đây là những gì đã diễn ra:
- Người dân đầu tiên vào chốt và nói: Tôi đang ở phòng 1501 thì nên đi thế nào?
- Người bảo vệ: Để tôi phân tích xem có bao nhiêu con đường đi… Uhm, từ nhà anh muốn ra phường có thể đi 5 con đường khác nhau. Trong đó muốn đi đường ngắn nhất thì anh đi thẳng, sau đó rẽ phải và bla bla… (Việc phân tích và lựa chọn đường đi này diễn ra mất 1 phút).
- Người dân thứ hai: Tôi đang ở phòng 1502 thì nên đi thế nào?
- Người bảo vệ: Thực hiện phân tích lại từ đầu và thấy rằng chiến lược đi cũng giống như người đầu tiên. Và việc phân tích này diễn ra cũng mất 1 phút
- …
- Người thứ 100.000: Cũng diễn ra như vậy nhưng đã bị muộn giờ tiêm.
Nếu ở tình huống đời thường này, chúng ta có thể thấy cách thức mà khu dân cư này hoạt động thực sự không hiệu quả, phải không nào? Vấn đề ở đây là 100.00 hộ dân này tuy ở các tầng khác nhau, ví dụ: người ở phòng 202, người ở phòng 1503, nhưng vẫn trong 1 tòa chung cư. Vì vậy về mặt logic thì những người này sẽ có cùng một con đường đi từ nhà mình ra đến nơi tiêm chủng. Nếu người bảo vệ kia nhận ra điều này và chỉnh lại như sau:
- Người dân đầu tiên: Tôi đang ở phòng 1501 thì nên đi thế nào?
- Người bảo vệ: Để tôi phân tích xem có bao nhiêu con đường đi… Uhm, từ nhà anh muốn ra phường có thể đi 5 con đường khác nhau. Trong đó muốn đi đường ngắn nhất thì anh đi thẳng, sau đó rẽ phải và bla bla… (Việc phân tích và lựa chọn đường đi này diễn ra mất 1 phút). Sau đó người bảo vệ lưu lại thông tin về con đường đi ngắn nhất này ra 1 tấm bản đồ cầm tay.
- Người thứ hai vào chốt: Tôi đang ở phòng 1502 thì nên đi thế nào?
- Người bảo vệ: Ah, tôi sẽ không cần phải phân tích lại đường đi mà sẽ dùng ngay thông tin lúc nãy phân tích được. Người bảo vệ đưa luôn thông tin bản đồ cho người thứ hai. Việc này diễn ra chỉ mất 3 giây.
- Cứ như vậy mọi việc xảy ra, và toàn bộ cư dân đều đến được địa điểm 1 cách nhanh chóng
 .
.
Ví dụ trên chính là cách thức mà tôi đã xử lý bài toán tối ưu cơ sở dữ liệu đặt ra. Về mặt tổng quan thì các bạn có thể đã hình dung được. Bây giờ tôi sẽ đưa tất cả những thứ này vào góc nhìn của Cơ sở dữ liệu Oracle.
3.5.2. Đây là những thứ "xảy ra bên trong" của Cơ sở dữ liệu Oracle khi chúng ta gửi một câu lệnh SQL tới.
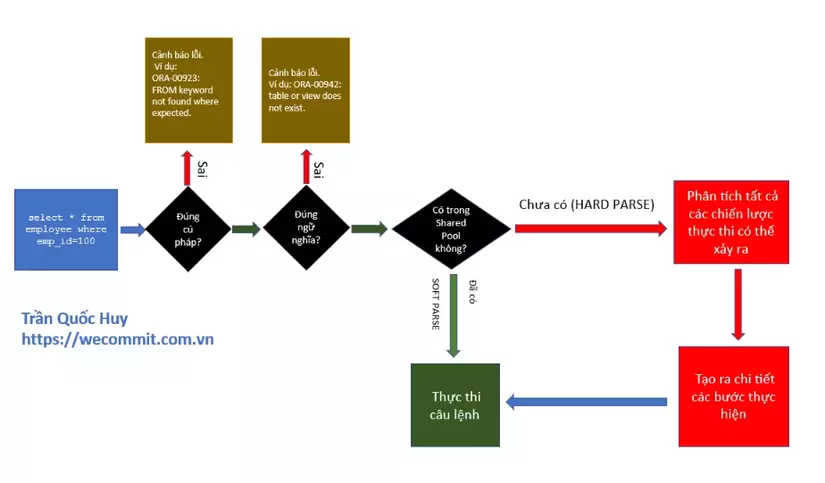
Bước 1: Thực hiện kiểm tra cú pháp của câu lệnh. Ví dụ khi chúng ta gõ sai cú pháp
select * employees where emp_id=100
Hệ thống kiểm tra và biết được câu lệnh trên bị lỗi cú pháp, thông báo lỗi như sau
ERROR at line 1:
ORA-00923: FROM keyword not found where expected.
Bước 2: Kiểm tra ngữ nghĩa của câu lệnh.
- Nếu như câu lệnh đã hoàn toàn đúng cú pháp, hệ thống sẽ kiểm tra xem về mặt “ý nghĩa” thì người dùng đang muốn làm gì.
- Hệ thống kiểm tra xem table mà người dùng định tương tác có tồn tại không, nếu tồn tại thì người dùng có quyền để làm việc trên đó không, các cột mà người dùng định lấy dữ liệu có trong bảng hay không …
- Ví dụ: Khi chúng ta thực hiện câu lệnh
select * from employee where emp_id=100
- Về mặt ngữ pháp, câu lệnh này không có lỗi gì, nên hệ thống sẽ thực hện bước kiểm tra “ngữ nghĩa”. Sau khi kiểm tra thì thấy người dùng muốn làm việc với một OBJECT tên là EMPLOYEE (có thể là TABLE hoặc VIEW vì object này đứng đằng sau FROM). Hệ thống kiểm tra thông tin các objects mà mình có thì thấy rằng không tồn tại object nào tên là EMPLOYEE cả. Cảnh báo lỗi người dùng nhận được như sau:
ERROR at line 1:
ORA-00942: table or view does not exist.
Bước 3: Kiểm tra thông tin trong Shared Pool (bộ nhớ lưu giữ các chiến lược thực thi của những câu lệnh đã từng thực hiện trong hệ thống.Nếu bạn muốn tìm hiểu thêm về kiến trúc tổng quan của Oracle, bao gồm những vùng bộ nhớ quan trọng khác thì bạn có thể xem tại video mô tả bên dưới). Nếu như đã tìm thấy thông tin về chiến lược thực thi của câu lệnh trong Shared Pool thì thực hiện bước 6 (bỏ qua bước 4 và bước 5). Nếu chưa tìm thấy thông tin thì lần lượt thực hiện 3 bước còn lại (bước 4,5 và 6).
- Trường hợp nếu Oracle không tìm thấy thông tin trong Shared Pool và buộc phải làm đầy đủ cả 6 bước, chúng ta gọi là HARD PARSE.
- Trường hợp nếu Oracle tìm thấy thông tin và bỏ qua bước 4,5, chúng ta gọi là SOFT PARSE
- Trước khi hoàn thành bước số 3 này, Oracle sử dụng một giải thuật HASH để chuyển câu lênh SQL FULL TEXT ban đầu thành một mã SQL_ID. Hàm HASH này có thể thay đổi tùy vào phiên bản của Oracle database mà bạn sử dụng.
- Ở đây bạn có thể thấy một điều thú vị là:
- Các câu lệnh SQL có giá trị FULL TEXT giống nhau 100% thì sẽ cùng có SQL_ID, mặc dù các câu lệnh này có thể chạy trên các hệ thống khác nhau (miễn là cùng phiên bản Oracle database).
- Nếu bạn cần biết về kiến trúc của Cơ sở dữ liệu Oracle thì có thể xem video này:
**Bước 4: **Thực hiện tính toán và phân tích tất cả những chiến lược thực thi có thể sử dụng để thực hiện câu lệnh mà người dùng yêu cầu. và lựa chọn ra chiến lược thực thi có chi phí tối ưu.
**Bước 5: **Nhận chiến lược thực thi tối ưu và sinh ra 1 kế hoạch thực thi cụ thể, chi tiết cho câu lệnh. Kế hoạch thực thi của một câu lệnh có dạng như dưới đây:
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 36 | 3 (0) | 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 36 | 3 (0) | 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C0011152 | 1 | | 2 (0) | 00:00:01 |
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMP_ID"=100)
Dựa vào thông tin này, Cơ sở dữ liệu sẽ biết chính xác mình cần xử lý những gì để lấy được kết quả mong muốn.(xử lý từ các nguồn dữ liệu nào, sử dụng chiến lược quét FULL TABLE hay quét INDEX, nếu quét INDEX thì sử dụng giải thuật gì, các bước thực hiện theo trình tự nào...)
Bước 6: Câu lệnh thực thi theo kế hoạch đã được lựa chọn.
3.5.3. Phân tích giải pháp tối ưu Cơ sở dữ liệu trong bài toán thực tế.
Đến đây bạn đã hiểu được 6 bước cơ sở dữ liệu Oracle cần phải thực hiện khi nhận một câu lệnh SQL. Chúng ta cùng phân tích 6 bước này vào trong bài toán đang thực hiện tối ưu nhé.
a. Đối với trường hợp truyền trực tiếp giá trị cho câu lệnh.
select * from employees where emp_id=1;
select * from employees where emp_id=2;
....
select * from employees where emp_id=1044;
select * from employees where emp_id=1045;
select * from employees where emp_id=1046;
….
select * from employees where emp_id=9400;
Do các câu lệnh có "nội dung" khác nhau (vì những giá trị truyền vào là khác nhau), vì vậy Cơ sở dữ liệu Oracle sẽ thực hiện như sau
- Tất cả các câu lệnh đều cần thực hiện bước số 1 - phân tích cú pháp. Cú pháp lệnh đúng nên sẽ được đi tiếp bước sau.
- Các câu lệnh đều thực hiện phân tích ngữ nghĩa. Tại đây Oracle thấy rằng ngữ nghĩa chuẩn xác, hệ thống tiếp tục đi sang bước thứ 3
- Tại bước kiểm tra thông tin trong Shared Pool, do đây là những câu lệnh khác nhau, Oracle sẽ cần thực hiện 10.000 lần HARD PARSE.
- Hệ thống phải thực hiện 10.000 lần bước số 4 và bước số 5 (đây là hai công việc cực kỳ tiêu tốn tài nguyên).
- Sau đó hệ thống thực hiện chạy câu lệnh theo chiến lược đã có ở bước số 5. b. Đối với trường hợp chúng ta sử dụng phương pháp truyền biến
select * from employees where emp_id=:B1
Trong trường hợp này, Oracle sẽ nhìn thấy 10.000 câu lệnh truyền vào là giống nhau (vì đoạn text của câu lệnh giống nhau hoàn toàn). Do đó các công việc thực tế xảy ra như sau
Hệ thống chỉ cần thực hiện phân tích câu lệnh 1 lần duy nhất (đối với câu lệnh đầu tiên). Với 9.999 câu lệnh còn lại, Oralce sẽ lấy luôn chiến lược thực thi (thực hiện SOFT PARSE - bỏ qua 2 bước tiêu tốn tài nguyên là bước số 4 và bước số 5).
Chính việc này dẫn đến kết quả tối ưu đã cải thiện hơn 97% (từ 93s còn ~3s).
4. Trong dự án tối ưu cơ sở dữ liệu thực tế, nếu luôn dùng truyền biến trong các câu lệnh SQL thì có rủi ro gì không?
Để giúp các bạn có thể trải nghiệm nhiều hơn nữa kỹ thuật tối ưu cơ sở dữ liệu trong những dự án thực tế, chúng ta hãy cùng xem xét một tình huống sau đây.
Giả sử bạn cần thực hiện 2 câu lệnh liên tiếp nhau như sau:
select * from employees where salary < 500;
select * from employees where salary < 50000;
Thông tin về bảng employeesnhư sau:
Tổng số bản ghi: 1.100.016 bản ghi.
Bảngemployees đã được đánh index trên cột salary. Index này sử dụng dạng Btree với tên là IDX_SALARYTEST
Bảng employees có 1.100.016 bản ghi. Trong đó có
- 2 bản ghi thỏa mãn điều kiện salary < 500 (chiếm 0.00018% tổng số lượng bản ghi)
- 342.344 bản ghi thỏa mãn điều kiện salary < 50000 (hơn 31% tổng số lượng bản ghi).
Chúng ta có thể thấy rõ ràng về tập kết quả cần tìm kiếm của 2 câu lệnh trên là RẤT KHÁC NHAU (về số lượng). Rõ ràng chiến lược thực thi của 2 câu lệnh này cũng hoàn toàn khác nhau.
Dưới đây là chiến lược thực thi mà Oracle sử dụng đối với từng câu lệnh
Đối với câu lệnh thứ nhất:
select * from employees where salary < 500;
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 6 | 4278 | 9 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 6 | 4278 | 9 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_SALARYTEST | 6 | | 3 (0)| 00:00:01 |
Predicate Information (identified by operation id):
2 - access("SALARY"<500)
Với câu lệnh thứ nhất Oracle sẽ thực sử dụng Index để thực hiện tìm kiếm.
Đối với câu lệnh thứ hai
> select * from employees where salary < 50000;
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1100K| 747M| 39879 (1)| 00:07:59 |
|* 1 | TABLE ACCESS FULL| EMPLOYEES | 1100K| 747M| 39879 (1)| 00:07:59 |
Predicate Information (identified by operation id):
1 - filter("SALARY"<500000)
Chúng ta có thể thấy rằng: Oracle sử dụng giải thuật quét toàn bộ bảng (FULL TABLE SCAN) đối với việc tìm kiếm các bản ghi thỏa mãn điều kiện SALARY < 50000. Tại sao ở câu lệnh thứ hai này Oracle không sử dụng Index?
- Do bản chất của việc tìm kiếm dựa trên Index và tìm kiếm toàn bộ bảng là khác nhau.
- Oracle ưu tiên tìm kiếm index nếu số lượng bản thi thỏa mãn là một tập nhỏ (trong trường hợp câu lệnh thứ nhất, số bản ghi thỏa mãn điều kiện chỉ chiếm 0.00018%.
- Oracle sẽ đánh giá các chiến lược thực thi theo chi phí (Cost) cần phải thực hiện, và sẽ quyết định lựa chọn chiến lược nào có chi phí thấp nhất. Như vậy ta thấy rằng 2 chiến lược thực thi tối ưu cho 2 câu lệnh trên là hoàn toàn khác nhau.
Bây giờ nếu chúng ta sử dụng truyền biến thì sẽ như thế nào, hãy cùng phân tích nhé. Câu lệnh của chúng ta sẽ truyền vào như sau:
select * from employees where salary < :B1
Đối với câu lệnh đầu tiên:
- Người dùng nhập vào giá trị :B1 = 500.
- Oracle sẽ thực hiện phân tích và thấy rằng đối với giá trị biến :B1 = 500 thì giải pháp tốt nhất là sử dụng Index.
- Oracle lưu lại thông tin chiến lược thực thi này
Người dùng tiếp tục thực hiện câu lệnh thứ hai
- Người dùng nhập giá trị :B1=50000
- Oracle sử dụng luôn chiến lược thực thi đã được lưu trước đó (sử dụng Index).
Ta có thể thấy Oracle đã chọn sai chiến lược "tốt nhất" cho câu lệnh thứ hai !!!.
Như vậy, để có thể thực sự tối ưu những cơ sở dữ liệu phức tạp trong thực tế, chúng ta cần cân nhắc và đo lường rất nhiều yếu tố khác nhau. Tôi sẽ tiếp tục cập nhật sâu hơn nữa các dự án tối ưu thực tế của mình trong thời gian tới.
5. Sai lầm của những anh em lập trình mắc phải là gì?
Các anh em lập trình đã mắc phải một số sai lầm sau trong quá trình xây dựng các câu lệnh SQL.
Thứ nhất: Tin vào một số "LUẬT TRUYỀN MIỆNG" mà không hiểu rõ nguyên lý hoạt động của Cơ sở dữ liệu. Đa phần anh em lập trình chỉ nhìn mặc hiệu năng ở mức "Câu lệnh SQL", thiết kế bảng, index. Tuy nhiên không thật sự hiểu về kiến trúc của các loại objects này, cách thức mà Cơ sở dữ liệu hành xử khi tương tác với các objects. Ví dụ như:
- Có một số anh em đọc thấy LUẬT rằng: cứ quét FULL TABLE thì có hiệu năng chậm hơn so với sử dụng Index.
- Sử dụng với chiến lược INDEX SKIP SCAN thì không hiệu quả.
- Câu lệnh SELECT mà không có điều kiện WHERE thì không thể sử dụng Index.
- Một bảng có ít bản ghi thì truy vấn dữ liệu sẽ nhanh.
Tôi đã trực tiếp lý giải và chứng minh rất nhiều trường hợp ngược lại với các luật trên.
- Mọi người nói rằng FULL TABLE SCAN luôn có hiệu năng chậm hơn so với việc sử dụng Index. Tôi dẫn chứng các trường hợp nêu sử dụng INDEX chậm hơn nhiều lần so với FULL TABLE SCAN
- Mọi người nói rằng sử dụng INDEX SKIP SCAN không hiệu quả. Tôi lấy các trường hợp nếu dùn INDEX SKIP SCAN thì cực kỳ nhanh. Tôi đã áp dụng trong những bài toán tối ưu thực tế.
- Mọi người nói rằng câu lệnh SELECT mà không có điều kiện WHERE thì không có cách nào sử dụng Index. Tôi liền lấy dẫn chứng rằng không có WHERE thì vẫn có thể dùng Index
- Mọi người nói rằng một bảng có ít bản ghi thì truy vấn sẽ nhanh. Tôi lấy dẫn chứng về một bảng có 0 bản ghi nhưng SELECT vẫn cực kỳ lâu, và cũng giải thích gốc rễ của vấn đề hiệu năng này.
Muốn thật sự trở thành KHÁC BIỆT và THỰC SỰ có năng lực TỐI ƯU, chúng ta cần hiểu rõ một cách TƯỜNG MINH những gì diễn ra bên trong một Cơ sở dữ liệu, từ lúc chúng ta bắt đầu tương tác, đến khi chúng ta nhận được những kết quả mong muốn.
**Thứ hai: **Nội dung này sẽ cập nhật trong nhóm học viên đặc quyền của Wecommit.
6. Link bài viết gốc
Link bài viết gốc tại đây: https://wecommit.com.vn/database-performance-tuning-speed-up-97/
7. Nếu bạn muốn xem các giải pháp tối ưu được áp dụng trong những hệ thống Production giao dịch 24x7
Nếu bạn chưa thuộc nhóm học viên đặc quyền của tôi nhưng vẫn muốn xem một số giải pháp tối ưu thực tế (giải pháp chi tiết, phân tích cụ thể), bạn có thể nhận mật khẩu để đọc giải pháp thông qua nhóm Zalo sau: Nhóm Tư Duy - Tối Ưu - Khác Biệt
8. Thông tin tác giả
- Tác giả: Trần Quốc Huy - Founder & CEO Wecommit
- Facebook: https://www.facebook.com/tran.q.huy.71
- Email: huy.tranquoc@wecommit.com.vn
- Youtube: Trần Quốc Huy
- Số điện thoại: 0888549190
Lời nhắn dành cho các bạn có duyên với bài viết:
- Hãy có tư duy khác biệt và tập trung vào những việc giá trị 100x (các công việc mang lại giá trị cực cao).
- Nếu như 100.000 người ngoài kia đang đi 1 con đường, bạn cũng đi cùng con đường đó thì tại sao lại mang kết quả khác?
All rights reserved
