Index trong database là gì? Tại sao cần Index Database?
Bài đăng này đã không được cập nhật trong 6 năm
Index database là gì?
- Index là một cấu trúc dữ liệu được dùng để định vị và truy cập nhanh nhất vào dữ liệu trong các bảng database
- Index là một cách tối ưu hiệu suất truy vấn database bằng việc giảm lượng truy cập vào bộ nhớ khi thực hiện truy vấn
Index database để làm gì?
- Giả sử ta có một bảng User lưu thông tin của người dùng, ta muốn lấy ra thông tin của người dùng có trường tên (Name) là “HauNguyen” . Ta có truy vấn SQL sau:
SELECT * FROM User WHERE Name = 'HauNguyen';
Khi không có Index cho cột Name, truy vấn sẽ phải chạy qua tất cả các Row của bảng User để so sánh và lấy ra những Row thỏa mãn. Vì vậy, khi số lượng bản ghi lớn, việc này thực sự là ác mộng @@
Index được sinh ra để giải quyết vấn đề này. Nói đơn giản, index trỏ tới địa chỉ dữ liệu trong một bảng, giống như Mục lục của một cuốn sách (Gồm tên đề mục và số trang), nó giúp truy vấn trở nên nhanh chóng như việc bạn xem mục lục và tìm đúng trang cần đọc vậy 
- Index có thể được tạo cho một hoặc nhiều cột trong database. Index thường được tạo mặc định cho primary key, foreign key. Ngoài ra, ta cũng có thể tạo thêm index cho các cột nếu cần.
Cấu trúc của Index
- Index là một cấu trúc dữ liệu gồm:
- Cột Search Key: chứa bản sao các giá trị của cột được tạo Index
- Cột Data Reference: chứa con trỏ trỏ đến địa chỉ của bản ghi có giá trị cột index tương ứng

Một số loại Index Database
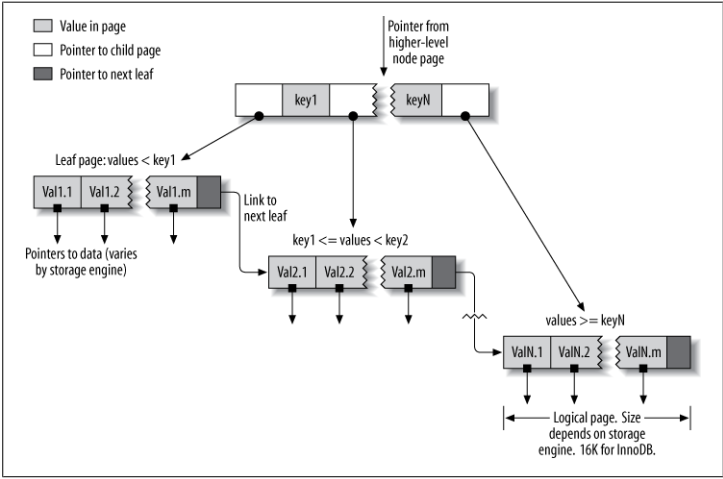
1. B-Tree
- Là kiểu dữ liệu phổ biến nhất cho Index
- Dữ liệu index trong B-Tree được tổ chức và lưu trữ theo dạng tree, tức là có root, branch, leaf.
- Ý tưởng chung của B-Tree là lưu trữ các giá trị được sắp xếp, mỗi leaf node có độ cao bằng nhau tính từ gốc. B-Tree có thể tăng tốc truy vấn vì storage engine không cần tìm toàn bộ bản ghi của bảng. Thay vào đó, nó sẽ tìm từ node root, root sẽ chứa con trỏ tới node con, storeage engine sẽ dựa vào con trỏ đó. Nó tìm đúng con trỏ bằng cách xét giá trị của node pages, nơi chứa khoảng giá trị của các node con. Cuối cùng, storage engine chỉ ra rằng giá trị không tồn tại hoặc tìm được giá trị ở leaf node.
- B-Tree index được sử dụng trong các biểu thức so sánh dạng: =, >, >=, <, <=, BETWEEN và LIKE
- B-Tree index được sử dụng cho những column trong bảng khi muốn tìm kiếm 1 giá trị nằm trong khoảng nào đó
![]() 2.Hash Index
2.Hash Index - Dữ liệu index được tổ chức theo dạng Key - Value được liên kết với nhau.
- Khác với B-Tree, thì Hash index chỉ nên sử dụng trong các biểu thức toán tử là = và <>. Không sử dụng cho toán từ tìm kiếm 1 khoảng giá trị như > hay <
- Không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order.
- Toàn bộ nội dung của Key được sử dụng để tìm kiếm giá trị records, khác với B-Tree một phần của node cũng có thể được sử dụng để tìm kiếm.
- Hash có tốc độ nhanh hơn kiểu Btree.
Dùng Index Database thế nào cho hiệu quả?
- Dù Index đóng vai trò quan trọng trong việc tối ưu truy vấn và tăng tốc độ tìm kiếm trong Database nhưng nhược điểm của nó là tốn thêm bộ nhớ để lưu trữ. Do vậy, việc Index cho các cột phải được tính toán, tránh lạm dụng.
- Dưới đây là một số Tips giúp bạn tạo Database index hiệu quả hơn:
- Nên Index những cột được dùng trong WHERE, JOIN và ORDER BY
- Dùng chức năng index prefix" or "multi-columns index” của MySQL. Vd: Nếu bạn tạo Index(first_name, last_name) thì k cần tạo Index(first_name)
- Dùng thuộc tính NOT NULL cho những cột được Index
- Không dùng Index cho các bảng thường xuyên có UPDATE, INSERT
- Không dùng Index cho các cột mà giá trị thường xuyên bị thay đổi
- Dùng câu lệnh EXPLAIN giúp ta biết được MySQL sẽ chạy truy vấn ra sao. Nó thể hiện thứ tự join, các bảng được join như thế nào. Giúp việc xem xét để viết truy vấn tối ưu, chọn cột để Index dễ dàng hơn
Một số lệnh Index Database
- Create Index trong SQL:
CREATE INDEX ten_chi_muc ON ten_bang;
- Single-Column Index trong SQL: Chỉ mục cho một cột đơn là một chỉ mục được tạo dựa trên chỉ một cột trong bảng. Cú pháp cơ bản là:
CREATE INDEX ten_chi_muc ON ten_bang (ten_cot);
- Unique index trong SQL Unique index được sử dụng không chỉ để tăng hiệu suất, mà còn cho mục đích toàn vẹn dữ liệu. Một Unique index không cho phép bất kỳ bản sao giá trị nào được chèn vào trong bảng. Cú pháp cơ bản là:
CREATE UNIQUE INDEX ten_chi_muc ON ten_bang (ten_cot);
- Composite Index trong SQL Composite Index là một chỉ mục cho hai hoặc nhiều cột trong một bảng. Cú pháp cơ bản của nó như sau:
CREATE INDEX ten_chi_muc ON ten_bang (cot1, cot2);
- Implicit Index trong SQL Implicit Index (có thể hiểu là chỉ mục ngầm định) là chỉ mục mà được tạo tự động bởi Database Server khi một đối tượng được tạo. Các chỉ mục được tạo tự động cho các ràng buộc Primary key và các ràng buộc Unique
- DROP INDEX trong SQL
DROP INDEX ten_chi_muc;
Tài Liệu Tham khảo
All rights reserved
