Sự khác nhau giữa SQL Server Clustered Index Scan và Index Seed
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Trong bài này mình sẽ giới thiệu về Clustered và Non-Clustered Index trong SQL Server, cách mà hai Index này hoạt động, và đưa ra một số ví dụ sử dụng Execution Plan trong SQL Server Management Studio. Hãy xem thử nhé. Trong bài viết này mình sử dụng database AdventureWorks2014, các bạn có thể lấy nó tại đây https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2014.bak

Định nghĩa
Một Index là một cấu trúc on-disk liên quan tới 1 bảng hoặc view nhằm mục đích tăng tốc độ đọc dữ liệu. Một Index bao gồm các key được lấy từ các cộng trong table hoặc view. Những key này được lưu theo cấu trúc (B-tree) cho phép SQL Server có thể tìm thấy các row liên quan một cách nhanh chóng và hiệu quả nhất. Có 2 loại Index là Clustered Index và Non Clustered Index.
Clustered Index
- Clustered index sắp xếp và lưu data rows trong table hoặc view dựa trên giá trị của key, gồm các cột trong định nghĩa index. Chỉ có 1 clustered index mỗi table, bởi vì các data rows chỉ có thể lưu 1 lần theo 1 thứ tự (lưu vật lý).
- Data rows chỉ được lưu theo 1 một thứ tự nhất định (sorted order) khi bảng đó có chứa clustered index. Khi một table có clustered index, table đó được gọi là clustered table. Nếu table không có clustered index, các data rows của nó được lưu theo một cấu trúc không có thứ tự gọi là heap.
Non Clustered Index
- Nonclustered index có cấu trúc độc lập với data rows. Một nonclustered index chứa các giá trị key nonclustered index và mỗi giá trị key này trỏ tới 1 data row.
- Việc trỏ từ một index row ở nonclustered index đến 1 data row được gọi là row locator. Cấu trúc của row locator phụ thuộc vào việc dữ liệu được lưu ở heap hay là clustered table. Đối với head, một row locator là một con trỏ trỏ đến data row, còn với clustered table, một row locator chính là clustered index key.
Cả 2 clustered index và nonclustered index đều có thể định nghĩa duy nhất, với keyword là unique, nghĩa là không có 2 data row nào có index key giống nhau. Còn nếu index không unique, thì sẽ có nhiều data row có thể có các index key giống nhau.
Hãy cẩn thận khi chọn những column sử dụng để tạo index. Số lượng column trong clustered (hoặc non-clustered) index có thể có ảnh hưởng đáng kể đến performance khi thực hiện các hành động INSERT, UPDATE, DELETE.
Xem các Index của một table trong database
Ví dụ mình muốn xem các Index của bảng "Sales.SalesOrderDetail" trong database AdventureWork2014. Có thể sử dụng SQL Command như sau
Use AdventureWorks2014
EXECUTE sp_helpindex 'Sales.SalesOrderDetail'
Kết quả như sau.
 Có 3 index ở bảng Sales.SalesOrderDetail, bao gồm 1 clustered index và 2 nonclustered index
Có 3 index ở bảng Sales.SalesOrderDetail, bao gồm 1 clustered index và 2 nonclustered index
Cách thứ 2 là từ giao diện của SMSS, tìm đến thư mục Index theo thứ tự sau: Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes
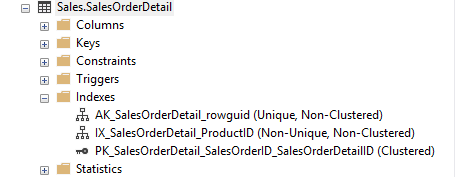
Table Scan
- When: Table Scan xảy ra khi select dữ liệu ở một table không có clustered index. Vì việc lưu các data row không có thứ tự gì nên SQL server sẽ thực hiện query bằng cách scan qua toàn bộ table.
- Good or bad: Với số lượng data nhỏ thì đôi khi chúng ta không thấy sự khác biệt ở tốc độ select. Tuy nhiên với một lượng lớn data, vấn đề performance sẽ xảy ra.
- Action item: Tạo ra 1 clustered index.
Clustered Index Scan
- When: Table với clustered index được truy cập, table đó không có non-clustered index hoặc query đó không sử dụng nonclustered index.
- Good or bad: Nó khá là xấu. Trừ khi lượng data rows trả về nhiều, còn nếu không thì nó cũng ảnh hưởng performance khá nhiều, vì nó cũng scan hết các index key values.
- Action item: nên cân nhắc các index key để tối ưu index, không phải scan toàn bộ index key values.
Clustered Index Seek
- When: Một table với clustered index được truy cập và cấu trúc B-tree có thể làm lọc được các kết quả trả về, giúp chúng ta lấy được 1 số lượng nhất định rows từ table.
- Good or bad: rất tốt để thấy Clustered index seek.
- Action item: đánh giá khả năng xảy ra mà query sử dụng nonclustered index, để có thể loại bỏ và tận dụng clustered index seek.
Ví dụ sử dụng Execution Plan
Để đưa ra ví dụ cụ thể, thì mình sử dụng bảng "Sales. SalesOrderDetail" từ database "AdventureWorks2014". Cấu trúc bảng như sau:
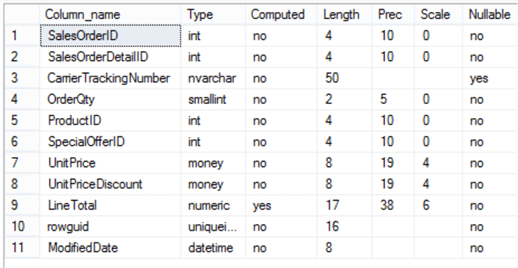
Gồm các index như sau:
Một vài sample data trong bảng như bên dưới:
Select Test
Ở test đầu tiên chúng ta sẽ chạy một query SELECT đơn giản sử dụng 2 phần của clustered index key để thấy cách query thực hiện bằng cách nhìn vào execution plan.
--Query 1
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 58950
--Query 2
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID = 68531
Trong 2 query trên, các cột được chọn giống nhau từ cùng table và sự khác biệt duy nhất là ở mệnh đề WHERE.
Trong query đầu tiên SalesOrderID được sử dụng trong mệnh đề WHERE và ở query thứ hai SalesOrderDetailId được sử dụng trong mệnh đề WHERE. Query đầu tiên trả về 28 record và query thứ hai trả về 1 record. Vậy, câu hỏi là query nào chạy tốt hơn?
Dưới đây là query plan
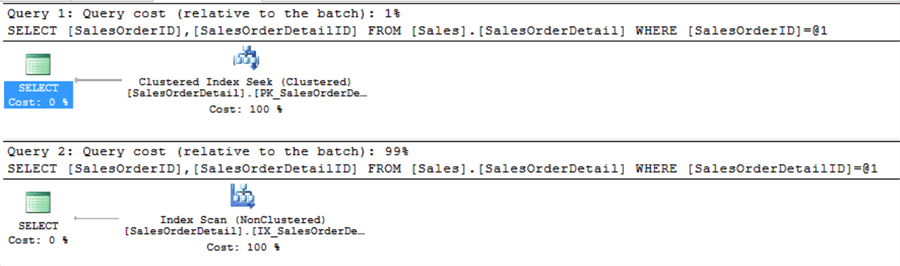
Rõ ràng, từ execution plans chúng ta có thể thấy cost cho query đầu tiên chỉ 1% trong khi query thứ hai tốn 99%. Phân tích kĩ hơn, có thể thấy là query đầu tiên thực hiện Index Seek trên clustered index và query thứ hai thực hiện index scan trên nonclustered index. Ở query thứ hai, nonclustered index scan được sử dụng bởi vì nó nhanh hơn scan bằng clustered index. Nguyên nhân là nonclustered index kia đã bao gồm 2 clustered key (SalesOrderID và SalesOrderDetailID) là 2 cột được dùng trong query. Mỗi nonclustered index bao gồm key của clustered index để trỏ đến data còn lại của clustered index.
Hãy tưởng tượng clustered index như một cuốn sổ danh bạ điện thoại. Trong cuốn sổ này, dữ liệu được index bằng LastName và FirstName. Giả sử bạn cần tìm cho "Doanh Ho", Doanh là FirstName và Ho là LastName. Nếu được yêu cầu tìm kiếm bằng 1 trong 2, tìm kiếm bằng FirstName (Doanh) và tìm kiếm bằng LastName (Ho), dễ dàng nói rằng tìm kiếm bằng LastName (Ho) sẽ nhanh hơn nhiều vì cuốn sổ được index bằng LastName rồi mới đến FirstName. Còn trong trường hợp tìm kiếm bằng FirstName (Doanh), không có cách nào khác là phải tìm kiếm trong toàn bộ danh bạ.
Bởi vì bảng SalesOrderDetail có clustered index gồm SalesOrderID và SalesOrderDetailID, query đầu tiên tìm kiếm bằng SalesOrderID và query thứ hai tìm kiếm bằng SalesOrderDetailID. Query đầu tiên có thể sử dụng index đề thực hiện seek, nhưng query thứ hai phải scan toàn bộ table cho đến khi tìm được giá trị matching.
Điểm rút ra được ở test này là số lượng record trả về không liên quan lắm tới tốc độ (performance) của query, vì trong trường hợp này thì query nhanh hơn là query trả về nhiều row dữ liệu hơn.
Select Test với mệnh đề WHERE khác nhau
Hãy xem các query dưới đây
-- Using full index
--Query 1
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID = 68531
--Query 2
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 58950
AND SalesOrderDetailID = 68531
Trong query trên, cả 2 query trả về cùng 1 row như nhau. Điểm khác biệt là mệnh đề WHERE ở query đầu tiên có 1 parameter và query thứ hai có 2 parameter. Nếu xem lại ví dụ về tìm kiếm "Doanh Ho" trong danh bạ ở test 1, có thể thấy là tìm kiếm khi có "SalesOrderID" sẽ nhanh hơn nhiều khi không có, đúng không?
Hãy xem execution plan để thấy rõ
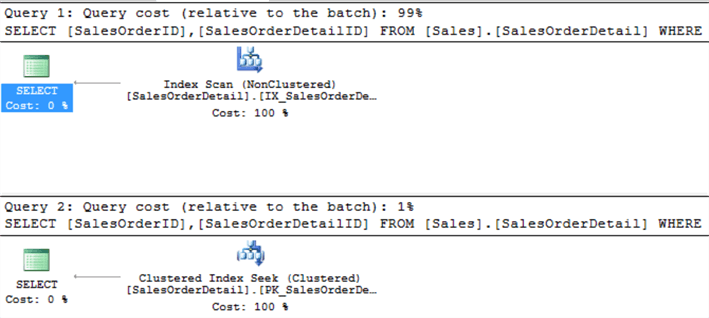
Execution plan cho thấy là khi index được dùng đầy đủ trong WHERE, thì performance sẽ được tối ưu. Một vài người nghĩ khi mệnh đề WHERE càng phức tạp thì càng khiến performance tồi tệ. Điều này là sai lầm.
Select Test với mệnh đề WHERE thay đổi thứ tự
Hãy tiếp tục với 2 query dưới đây
-- Changing the Where clause order
--Query 1
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
AND SalesOrderDetailID = 240
--Query 2
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID = 240
AND SalesOrderID = 43683
Trong 2 query trên, điểm khác biệt duy nhất là thứ tự column trong mệnhd đề WHERE. Nhiều người tin rằng mệnh đề WHERE nên có cùng thứ tự như thứ tự trong index. Hãy xem họ nghĩ như vậy có đúng không bằng execution plan
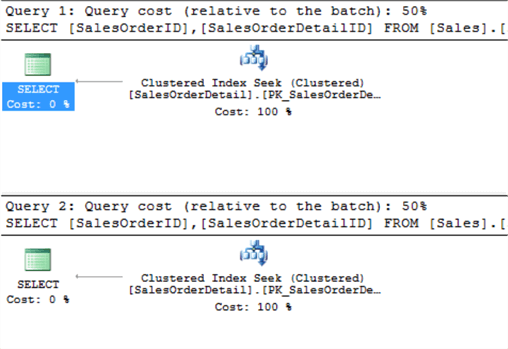
Execution plan cho thấy là chi phí (cost) của cả 2 query trên là như nhau (50%), vì vậy thứ tự trong WHERE clause là không quan trọng.
Select Test với AND OR logic
Hãy xem ví dụ dưới đây
-- Difference between AND and OR
--Query 1
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
AND SalesOrderDetailID = 240
--Query 2
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
OR SalesOrderDetailID = 240
Trong trường hợp này, 2 query giống nhau chỉ khác là AND/OR trong mệnh đề WHERE. Nếu xem lại ví dụ về "Doanh Ho", dễ dàng thấy là (Doanh and Ho) sẽ nhanh hơn (Doanh or Ho), khi dùng "OR" thì việc scan toàn bộ danh bạ là bắt buộc. Hãy xem execution plan để thấy rằng nhận định trên là đúng.
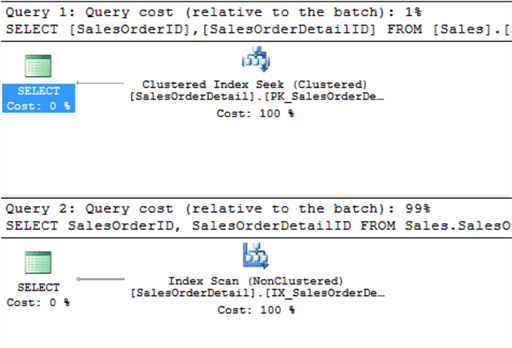
Execution plan cho thấy là sử dụng "OR" là làm performance tệ hợn rất nhiều so với "AND"
Select Test với việc trả về nhiều Column
-- Different Columns
--Query 1
SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
AND SalesOrderDetailID = 240
--Query 2
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43683
AND SalesOrderDetailID = 240
Trong 2 query này, điểm thay đổi chính là cột thêm vào (CarrierTrackingNumber) trong mệnh đề SELECT ở query 1. Một vài người có thể nghĩ khi lấy data về nhiều hơn ở query 1, thì performance có thể chậm hơn. Hãy xem execution plan nói gì.
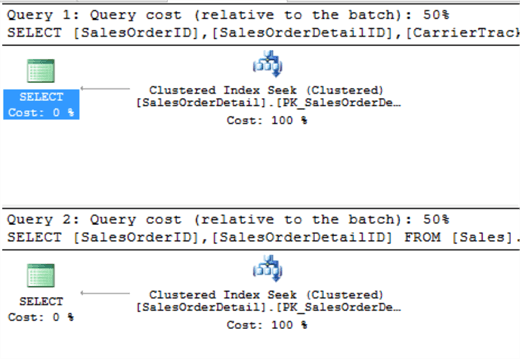
Chúng ta có thể thấy là query plan tương tự nhau và cost của 2 query là như nhau. Điểm quan trọng là clustered index được cấu thành từ SalesOrderId và SalesOrderDetailID, việc select ra bao nhiêu cột không quan trọng. Nhưng lưu ý nếu là nonclustered index thì việc này sẽ khác, vì nó phải matching đến clustered index để lấy thêm dữ liệu của column thêm vào.
Kết bài
Vậy là hết rồi. Hi vọng các bạn có thể hiểu thêm về các thể loại có thể xảy ra khi tiến hành query trên các bảng của SQL Server. Từ đó tối ưu được tốc độ query, làm tăng tốc xử lý dữ liệu. Cảm ơn các bạn đã đọc bài.
Bài viết tham khảo 1 số nguồn dưới đây https://docs.microsoft.com/en-us/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-2017
https://www.sqlshack.com/sql-server-query-execution-plan-beginners-clustered-index-operators/
All rights reserved
