
Feature Engineering (Phần 3): Feature engineering với dữ liệu dạng phân loại (Categorical Data)
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người một số phương pháp xử lý với dữ liệu dạng số liên tục (Continuous Numeric Data). Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu về một số phương pháp feature engineering với dữ liệu dạng phân loại (Categorical Data).
Giới thiệu
Trong phần trước chúng ta đã đề cập đến các phương pháp feature engineering với các dữ liệu dạng số liên tục. Trong bài viết này, chúng ta sẽ xem xét một loại dữ liệu có cấu trúc khác, về bản chất là một dạng dữ liệu rời rạc, thường được gọi là dữ liệu phân loại (categorical data). Xử lý dữ liệu số thường dễ hơn dữ liệu phân loại bởi chúng ta không phải đối phó với sự phức tạp của ngữ nghĩa, bối cảnh liên quan đến từng category hoặc type của dữ liệu. Chúng ta sẽ sử dụng các ví dụ thực tế và thảo luận về một số phương pháp mã hóa để xử lý dữ liệu dạng phân loại và một số kỹ thuật để xử lý số lượng lớn nhóm phân loại (thường được gọi là "curse of dimensionality")
Sự cần thiết
Với các bạn đọc đã đi đến phần này của series chắc các bạn đã nhận ra được sự cần thiết và tầm quan trọng của các kỹ thuật feature engineering mà chúng ta đã nhấn mạnh trong phần đầu tiên của series này. Mọi người có thể đọc nhanh lại nếu cần thiết. Tóm lại, các thuật toán học máy không thể làm việc trực tiếp với dữ liệu dạng phân loại và bạn cần thực hiện các kỹ thuật biến đổi trên dữ liệu dạng này để có thể đưa chúng vào các mô hình của mình.
Cơ bản về dữ liệu phân loại (Categorical Data)
Chúng ta xem xét về ý tưởng dữ liệu phân loại trước khi đi sâu vào các phương pháp xử lý. Thông thường, dữ liêu phân loại là dạng dữ liệu có tính chất phân biệt các giá trị thành hữu hạn các nhóm. Chúng cũng thường được gọi là các phân lớp hoặc các nhãn của các thuộc tính. Các giá trị rời rach này có thể là văn bản hoặc các số tự nhiên (hoặc có thể là dữ liệu phi cấu trúc như hình ảnh). Có hai dạng chính của dữ liệu phân loại là danh nghĩa (nominal) và thứ tự (ordinal)
Phân loại danh nghĩa (nominal) là dạng dữ liệu không có khái niệm sắp xếp giữa các giá trị của thuộc tính đó. Một ví dụ đơn giản về việc phân loại thời tiết như hình dưới đây. Chúng ta có thể thấy được 6 phân lớp (hoặc danh mục) trong ví dụ cụ thể này mà trong đó không có khái niệm nào về thứ tự (gió không phải lúc nào cũng xảy ra trước nắng và cũng không nhỏ hơn hoặc lớn hơn nắng)

Tương tự các thể loại phim, âm nhạc, video, tên quốc gia, loại thực phẩm là một vài ví dụ khác về phân loại danh nghĩa.
Phân loại thứ tự thứ tự (ordinal) là dạng dự liệu mang một số ý nghĩa về thứ tự giữa các giá trị của nó. Ví dụ hình dưới đây cho việc phân loại kích cỡ áo. Thứ tự giữa các nhóm được thể hiện rất rõ ràng trong trường hợp này như khi nói về "size" áo sơ mi thì S < M < L
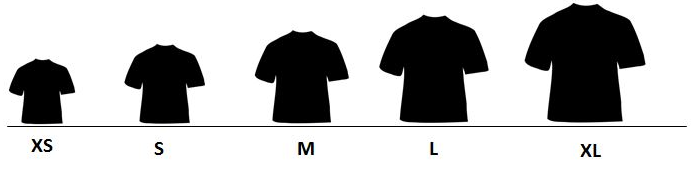
Tương tự, cỡ giày, trình độ học vấn, vai trò của nhân viên... là các ví dụ khác cho dạng phân loại thứ tự. Như vậy chúng ta đã có cái nhìn khái quát về dạng dữ liệu phân loại, tiếp theo hãy xem xét các phương pháp để xử lý chúng.
Feature engineering cho dữ liệu phân loại
Hiện nay chúng ta đã có rất nhiều tiến bộ đã được áp dụng cho các frameworks học máy để có thể sử dụng trực tiếp dữ liệu phân loại phức tạp như text label. Thông thường, bất kỳ quy trình làm việc tiêu chuẩn nào trong giai đoạn feature engineering đều liên quan đến một số dạng biến đổi các giá trị phân loại thành các nhãn dạng số (numberic label) và sau đó áp dụng một số phương pháp encoding trên các giá trị này. Đầu tiên chúng ta cần có một số cài đặt sau
import pandas as pd
import numpy as np
Biến đổi dữ liệu phân loại danh nghĩa (Transforming Nominal Attributes)
Như đã đề cập ở trên, phân loại danh nghĩa bao gồm các giá trị phân loại riêng biệt không có khái niệm hoặc ý nghĩa về thứ tự giữa chúng. Ý tưởng ở đây là biến đổi các thuộc tính này thành một dạng số đại diện hơn để có thể dễ dàng đưa vào các thuật toán và pipeline. Chúng ta hãy xem xét một bộ dữ liệu liên quan đến doanh số trò chơi điện tử. Bộ dữ liệu này được cung cấp bởi Kaggle và Github của tác giả.
vg_df = pd.read_csv('datasets/vgsales.csv', encoding='utf-8')
vg_df[['Name', 'Platform', 'Year', 'Genre', 'Publisher']].iloc[1:7]
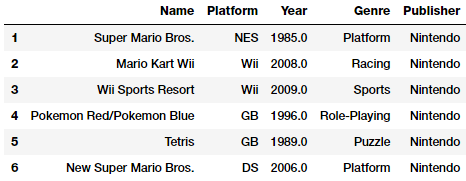
Các bạn hãy tập trung vào các thuộc tính Genre ở bảng dữ liệu trên. Một điều khá rõ ràng đây là một thuộc tính phân loại danh nghĩa tương tự Publisher và Platform. Chúng ta có thể dễ dàng có được danh sách các thể loại trò chơi như sau.
genres = np.unique(vg_df['Genre'])
genres
Output
------
array(['Action', 'Adventure', 'Fighting', 'Misc', 'Platform',
'Puzzle', 'Racing', 'Role-Playing', 'Shooter', 'Simulation',
'Sports', 'Strategy'], dtype=object)
Với đoạn code trên chúng ta có thể biết rằng có 12 thể loại trò chơi riêng việt. Bây giwof chúng ta có thể sử dụng label encoding để ánh xạ từng danh mục thành giá trị số bằng cách sử dụng scikit-learn
from sklearn.preprocessing import LabelEncoder
gle = LabelEncoder()
genre_labels = gle.fit_transform(vg_df['Genre'])
genre_mappings = {index: label for index, label in
enumerate(gle.classes_)}
genre_mappings
Output
------
{0: 'Action', 1: 'Adventure', 2: 'Fighting', 3: 'Misc',
4: 'Platform', 5: 'Puzzle', 6: 'Racing', 7: 'Role-Playing',
8: 'Shooter', 9: 'Simulation', 10: 'Sports', 11: 'Strategy'}
Như vậy chúng ta đã có được một ánh xạ trong đó mỗi giá trị của genre được ánh xạ với một số (numberic) với sự giúp đỡ của LabelEncoder. Các label đã được chuyển đổi được lưu tại genre_labels, chúng ta có thể ghi lại các giá trị này và dataframe của mình.
vg_df['GenreLabel'] = genre_labels
vg_df[['Name', 'Platform', 'Year', 'Genre', 'GenreLabel']].iloc[1:7]
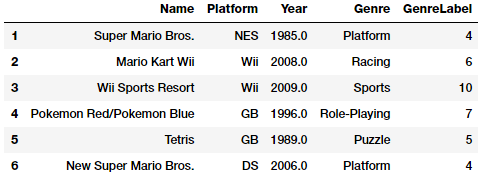
Các labels này có thể sử dụng được trực tiếp đặc biệt là với các framework như scikit-learn nếu sử dụng chúng như những giá trị để dự đoán. Tuy nhiên, như đã thảo luận ở trên, chúng ta sẽ cần thêm một bước mã hóa nữa trước khi có thể sử dụng chúng làm các đặc trưng (features)
Chuyển đổi dữ liệu phân loại thứ tự (Transforming Ordinal Attributes)
Phân loại thứ tự là dạng dữ liệu mà các phân nhóm có quan hệ thứ tự với nhau. Chúng ta cùng xem lại Pokémon dataset mà chúng ta đã sử dụng trong phần trước của series. Hãy tập trụng vào đặc trưng Generation
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8')
poke_df = poke_df.sample(random_state=1,
frac=1).reset_index(drop=True)
np.unique(poke_df['Generation'])
Output
------
array(['Gen 1', 'Gen 2', 'Gen 3', 'Gen 4', 'Gen 5', 'Gen 6'],
dtype=object)
Dựa vào kết quả output ở trên chúng ta có thể thấy rằng có tổng cộng 6 thế hệ và mỗi Pokémon thường thuộc vào một thế hệ cụ thể dựa vào các trò chơi điện tử (khi chúng được phát hành) và loạt phim truyền hình theo dòng thời gian tương tự. Thuộc tính này thường là thứ tự (ở đây chúng ta cần đến kiến thức về bộ phim này) vì hầu hết các Pokémon thuộc thế hệ 1 đã được giới thiệu trước thế hệ 2 trong các trò chơi điện tử và các tập phim. Mọi người có thể kiểm tra hình ảnh dưới đây để ghi nhớ một số Pokémon phổ biến của mỗi thế hệ.

Về cơ bản, không có một module cụ thể hoặc phương pháp chuyển đổi nào để ánh xạ các đặc trưng này thành dạng số một cách tự động. Do đó, chúng ta có thể tự xây dựng các ánh xạ tùy chỉnh như sau.
gen_ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3,
'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
poke_df['GenerationLabel'] = poke_df['Generation'].map(gen_ord_map)
poke_df[['Name', 'Generation', 'GenerationLabel']].iloc[4:10]
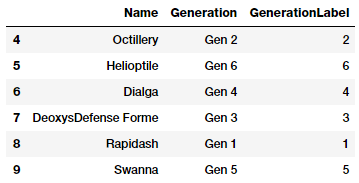
Từ đoạn code trên ta có thể thấy function map() của pandas rất hữu ích trong việc biến đổi các đặc trưng dạng này.
Encoding dữ liệu phân loại
Nếu bạn nhớ những gì chúng ta đã đề cập đến trong những phần trên thì các kỹ thuật xử lý trên dữ liệu phân loại bao gồm quá trình biến đổi (transformation) và quá trình encoding. Encoding là quá trình bắt buộc sử dụng các phương pháp mã hóa cụ thể để tạo ra các giá trị/phân nhóm cụ thể cho từng đặc trưng.
Các bạn sẽ có câu hỏi rằng tại sau cần quá trình encoding sau khi đã biến đổi các label sang dạng số trong phần trước. Lý do khá đơn gián. Xem xét các thể loại trò chơi điện tử, nếu chúng ta trực tiếp cung cấp các giá trị GenreLabel như một đặc trưng (feature) trong mô hình học máy thì thuật toán sẽ hiểu rằng đây là một đặc trưng dạng số liên tục và giá trị 10 (Sports) sẽ lớn hơn giá trị 6 (Racing), nhưng điều đó là vô nghĩa vì thể loại Sports chắc chắn không có ý nghĩa lớn hơn hoặc nhỏ hơn thể loại Racing, đây thực chất chỉ là các giá trị hoặc danh mục khác nhau, không thể so sánh trực tiếp. Do đó, chúng ta cần một bước bổ sung là encoding trong đó các đặc trưng giả được tạo ra cho mỗi giá trị hoặc danh mục của mỗi đặc trưng.
One-hot Encoding Scheme
Sau bước biến đổi, chúng ta có biểu diễn dạng số của bất kỳ đặc trưng phân loại nào với m nhãn khác nhau. One-hot encoding là quá trình biến đổi từng giá trị thành các đặc trưng nhị phân chỉ chứa giá trị 1 hoặc 0. Mỗi mẫu trong đặc trưng phân loại sẽ được biến đổi thành một vecto có kích thước m chỉ với một trong các giá trị là 1 (biểu thị nó là active). Chúng ta hãy xem xét một tập con của bộ dữ liệu Pokémon.
poke_df[['Name', 'Generation', 'Legendary']].iloc[4:10]
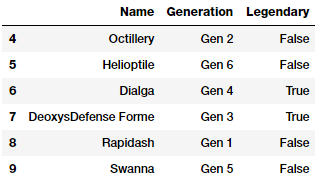
Chúng ta sẽ quan tâm đến hai đặc trưng là Generation và Legendary. Đầu tiên ta sẽ biến đổi các thuộc tính này thành biểu diễn dạng số học như đã giới thiệu ở phần trước.
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
# transform and map pokemon generations
gen_le = LabelEncoder()
gen_labels = gen_le.fit_transform(poke_df['Generation'])
poke_df['Gen_Label'] = gen_labels
# transform and map pokemon legendary status
leg_le = LabelEncoder()
leg_labels = leg_le.fit_transform(poke_df['Legendary'])
poke_df['Lgnd_Label'] = leg_labels
poke_df_sub = poke_df[['Name', 'Generation', 'Gen_Label',
'Legendary', 'Lgnd_Label']]
poke_df_sub.iloc[4:10]
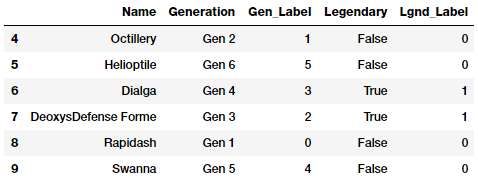
Các đặc trưng Gen_Label và Lgnd_Label bây giờ đã được mô tả dưới dạng số học . Tiếp theo chúng ta sẽ sử dụng one-hot encoding cho các đặc trưng này.
# encode generation labels using one-hot encoding scheme
gen_ohe = OneHotEncoder()
gen_feature_arr = gen_ohe.fit_transform(
poke_df[['Gen_Label']]).toarray()
gen_feature_labels = list(gen_le.classes_)
gen_features = pd.DataFrame(gen_feature_arr,
columns=gen_feature_labels)
# encode legendary status labels using one-hot encoding scheme
leg_ohe = OneHotEncoder()
leg_feature_arr = leg_ohe.fit_transform(
poke_df[['Lgnd_Label']]).toarray()
leg_feature_labels = ['Legendary_'+str(cls_label)
for cls_label in leg_le.classes_]
leg_features = pd.DataFrame(leg_feature_arr,
columns=leg_feature_labels)
Nhìn chung, các bạn có thể sử dụng cùng 1 object encode cho cả hai đặc trưng bằng cách sử dụng fit_transform(…) bằng cách chuyển nó thành mảng hai chiều của hai đặc trưng (cụ thể hơn tại đây). Tuy nhiên ở đây chúng ta sẽ encoding cho từng đặc trưng để dễ hiểu hơn. Bên cạnh đó, chúng ta có thể tạo ra các dataframe riêng biệt và gán nhãn cho chúng. Bây giờ, chúng ta hay concatenate các đặc trưng được tạo ra ở trên và xem kết quả cuối cùng.
poke_df_ohe = pd.concat([poke_df_sub, gen_features, leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels, ['Legendary', 'Lgnd_Label'],
leg_feature_labels], [])
poke_df_ohe[columns].iloc[4:10]

Như bảng trên bạn có thể thấy rằng có 6 đặc trưng nhị phân tạm thời được tạo ra cho đặc trưng Generation và 2 cho Legendary vì đó là số các nhóm của từng đặc trưng tương ứng. Trạng thái active của đặc trưng được biểu thị bằng giá trị 1 trong đặc trưng tạm tương ứng. Chúng ta có thể rất dễ dàng nhận ra điều này!
Như vậy, sau khi đã xây dựng được sơ đồ encoding như trên từ bộ dữ liệu training và bây giwof chúng ta có một số dữ liệu mới vào phải được biến đổi phù hợp với sơ đồ encoding trước đó để phục vụ cho việc dự đoán. Đầu tiên chúng ta sẽ tạo ra một số dữ liệu mới.
new_poke_df = pd.DataFrame([['PikaZoom', 'Gen 3', True],
['CharMyToast', 'Gen 4', False]],
columns=['Name', 'Generation', 'Legendary'])
new_poke_df

Bạn có thể sử dụng function transform() của đối tượng LabeLEncoder và OneHotEncoder cho dữ liệu mới. Hãy nhớ quy trình, đầu tiên là biến đổi.
new_gen_labels = gen_le.transform(new_poke_df['Generation'])
new_poke_df['Gen_Label'] = new_gen_labels
new_leg_labels = leg_le.transform(new_poke_df['Legendary'])
new_poke_df['Lgnd_Label'] = new_leg_labels
new_poke_df[['Name', 'Generation', 'Gen_Label', 'Legendary',
'Lgnd_Label']]

Chúng ta đã có các nhãn dạng số học (numeric labels), tiếp theo hãy áp dụng encoding
new_gen_feature_arr = gen_ohe.transform(new_poke_df[['Gen_Label']]).toarray()
new_gen_features = pd.DataFrame(new_gen_feature_arr,
columns=gen_feature_labels)
new_leg_feature_arr = leg_ohe.transform(new_poke_df[['Lgnd_Label']]).toarray()
new_leg_features = pd.DataFrame(new_leg_feature_arr,
columns=leg_feature_labels)
new_poke_ohe = pd.concat([new_poke_df, new_gen_features, new_leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels,
['Legendary', 'Lgnd_Label'], leg_feature_labels], [])
new_poke_ohe[columns]

Như vậy, chúng ta có thể rất dễ dàng áp dụng các quá trình biến đổi và encoding cho dữ liệu mới vào bằng cách sử dụng các API từ scikit-learn
Ngoài ra, bạn cũng có thể dễ dàng áp dụng one-hot encoding bằng cách sử dụng function to_dummies của pandas.
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
pd.concat([poke_df[['Name', 'Generation']], gen_onehot_features],
axis=1).iloc[4:10]
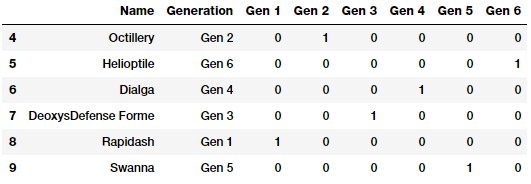
Như vậy chúng ta có thể thấy rằng phương pháp này áp dụng one-hot encoding cho đặc trưng Generation thu được kết quả tương tự như cách làm trước đó.
Dummy Encoding
Dummy Encoding là một phương pháp mã hóa tương tự như One-hot Encoding ngoại trừ việc khi áp dụng Dummy Encoding cho một đặc trưng có m phân nhóm thì chúng ta sẽ thu được m-1 đặc trưng nhị phân. Do đó, mỗi giá trị của đặc trưng phân loại được biến đổi thành một vecto có m-1 chiều. Các nhóm/danh mục không được sử dụng toàn bộ để tạo đặc trưng tạm, như vậy giá trị của các danh mục được thêm vào sẽ là {0, 1, ..., m-1}, chúng ta sẽ bỏ đi giá trị đầu tiên hoặc giá trị cuối cùng và giá trị tương ứng thường được biểu diễn bởi vecto 0. Chúng ta tiếp tục xem xét đặc trưng Generation của bộ dữ liệu Pokémon với việc bỏ qua giá trị Gen 1
gen_dummy_features = pd.get_dummies(poke_df['Generation'],
drop_first=True)
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]
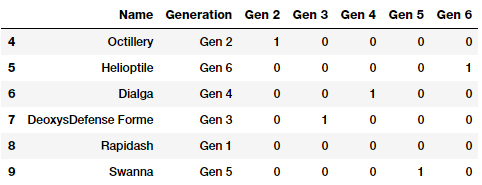
Chúng ta cũng có thể bỏ qua giá trị cuối cùng Gen 6
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_dummy_features = gen_onehot_features.iloc[:,:-1]
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]
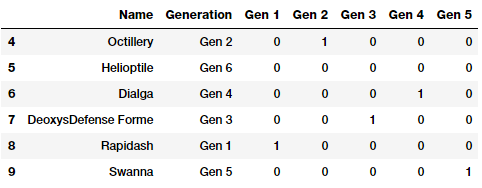
Từ hai ảnh trên chúng ta có thể thấy giá trị bị bỏ qua của đặc trưng sẽ được biểu diễn bởi một vecto 0.
Effect encoding
Efftect encoding thực chất rất giống với Dummy encoding ngoại trừ trong quá trình encode, giá trị bị bỏ qua sẽ được thay thế bằng -1 thay vì vecto 0 như trong Dummy encoding. Chúng ta hãy xem ví dụ sau.
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_effect_features = gen_onehot_features.iloc[:,:-1]
gen_effect_features.loc[np.all(gen_effect_features == 0,
axis=1)] = -1.
pd.concat([poke_df[['Name', 'Generation']], gen_effect_features],
axis=1).iloc[4:10]
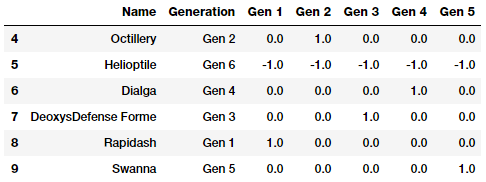
Kết quả trên cho thấy, các Pokémon thuộc Gen 6 đã được biểu thị bằng tất cả các giá trị -1 thay vì giá trị 0 như trong Dummy encoding.
Bin-counting
Các phương pháp encoding ở trên sẽ hoạt động khá tốt trên các dữ liệu phân loại nói chung. Tuy nhiên chúng sẽ bắt đầu xảy ra vấn đề khi số lượng các nhóm/danh mục trong từng đặc trưng trở nên rất lớn. Bạn luôn cần m đặc trưng riêng biệt cho một đặc trưng phân loại có m danh mục. Điều này sẽ tăng kích thước của bộ dữ liệu và gây ra các vấn đề trong việc lưu trữ và training mô hình. Bên cạnh đó, chúng ta cũng phải đối mặt với vấn đề rất phổ biến được biến đến là ‘curse of dimensionality’. Về cơ bản, số lượng đặc trưng quá lớn và không đủ số lượng mẫu cần thiết thì hiệu suất của mô hình sẽ bị ảnh hưởng và thường dẫn đến overfitting.

Do đó, chúng ta cần hướng tới các phương pháp encoding khác cho các đặc trưng phân loại có số lượng danh mục quá lớn (như địa chỉ IP). Bin-counting là một phương pháp khá hữu ích. Trong phương pháp này, thay vì sử dụng các giá trị nhãn thực tế để encode, chúng ta sẽ sử dụng thông tin thông kê dựa trên xác suất về giá trị và mục tiêu thực tế hoặc label chúng ta nhắm đến để dự đoán trong các mô hình của mình. Ví dụ, dựa trên dữ liệu lịch sử quá khứ của địa chỉ IP và các địa chỉ được sử dụng trong các cuộc tấn công DDOS, chúng ta có thể xây dựng các giá trị xác suất cho một cuộc tấn công tương tự được gây ra bởi bất cứ địa chỉ IP nào. Sử dụng thông tin này, chúng ta có thể encode một địa chỉ IP xuất hiện trong tương lại có giá trị xác suất tấn công DDOS là bao nhiêu. Phương pháp này cần dữ liệu trong lịch sử như một điều kiện tiên quyết và xử lý rất công phu. Việc mô tả phương pháp này với một ví dụ hoàn chỉnh hiện tại là rất khó khăn.
Feature hashing
Feature hashing cũng là một phương pháp hữu ích để xử lý các đặc trưng phân loại có số lượng danh mục quá lớn. Trong phương pháp này, hàm băm thường được sử dụng với số lượng các đặc trưng tạm sinh ra được cài đặt sẵn (dưới dạng các vevto có độ dài xác định trước). Do hàm băm sẽ ánh xạ một số lượng lớn các giá trị thành một tập hữu hạn nhỏ có thể xảy ra trường hợp nhiều giá trị sẽ tạo ra cùng một hàm băm, điều này được gọi là xung đột.
Hashing hoạt động với chuỗi, số hoặc các cấu trúc khác như vecto. Bạn có thể hiểu rằng các ouput được băm là một tập hợp n bins hữu hạn sao cho khi hàm băm được áp dụng trên cùng một giá trị nhóm/danh mục chúng sẽ được gán vào cùng một bin (hoặc một tập hợp các bins) trong số n bins được tạo ra trước đó. Chúng ta có thể định nghĩa trước giá trị n là kích thước cuối cùng của vecto đặc trưng sẽ được băm của từng giá trị.
Do vậy, kể cả khi chúng ta có 1000 danh mục khác nhau trong một đặc trưng và chúng ta định nghĩa n = 10 làm kích thước vecto cuối cùng thì bộ đặc trưng tạm cuối cùng được sinh ra vẫn sẽ chỉ là 10 so với 1000 nếu áp dụng one-hot encoding. Chúng ta cùng xem xét ví dụ về đặc trưng Genre của trò chơi điện tử để hiểu rõ hơn.
unique_genres = np.unique(vg_df[['Genre']])
print("Total game genres:", len(unique_genres))
print(unique_genres)
Output
------
Total game genres: 12
['Action' 'Adventure' 'Fighting' 'Misc' 'Platform' 'Puzzle' 'Racing'
'Role-Playing' 'Shooter' 'Simulation' 'Sports' 'Strategy']
Chúng to có thể thấy rằng có tổng cộng 12 thể loại trò chơi điện tử. Nếu chúng ta áp dụng one-hot encoding chúng ta sẽ sinh ra 12 đặc trưng nhị phân. Thay vào đó chúng ta sẽ sử dụng FeatureHasher của scikit-learn với phiên bản 32 bit của hàm băm Murmurhash3. Chúng ta sẽ xác định trước kích thước của vecto đầu ra là 6.
from sklearn.feature_extraction import FeatureHasher
fh = FeatureHasher(n_features=6, input_type='string')
hashed_features = fh.fit_transform(vg_df['Genre'])
hashed_features = hashed_features.toarray()
pd.concat([vg_df[['Name', 'Genre']], pd.DataFrame(hashed_features)],
axis=1).iloc[1:7]
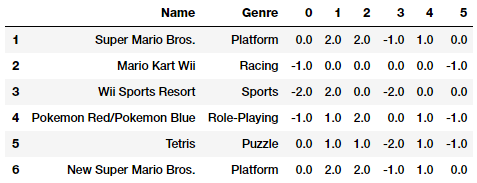
Với kết quả trên, đặc trưng Genre được mã hóa bằng phương pháp băm sẽ thu được chỉ là 6 đặc trưng mới thay vì 12. Chúng ta hoàn toàn có thể thấy được mẫu số 1 và số 6 biểu diễn hai trò chơi cùng một thể loại bởi chúng có cùng một vecto đặc trưng.
Kêt luận
Những ví dụ trên đây có thể sẽ cung cấp cho bạn một số ý tưởng tối cho việc xử lý các dữ liệu dạng phân loại, rời rạc. Nếu bạn đọc trong phần trước với xử lý dữ liệu với dạng số liên tục có thể thấy rằng làm việc với dữ liệu có phần khó hơn, nhưng chắc chắn nó sẽ thú vị. Chúng ta cũng đã nói về một số cách để xử lý các không gian đặc trưng lớn hơn bằng các kỹ thuật xử lý dữ liệu bao gồm trích chọn đặc trưng và giảm kích thước để xử lý không gian đặc trưng lớn. Chúng ta sẽ đề cập đến các phương pháp này trong một series khác.
Trong phân tiếp theo của series feature engineering này chúng ta sẽ bàn luật về phương pháp xử lý với dữ liệu dạng văn bản, phi cấu trúc. Hãy theo dõi nhé!!!
Tài liệu tham khảo
All rights reserved
