
Feature Engineering (Phần 1): Vai trò của feature engineering với việc xây dựng mô hình học máy - cơ bản về đặc trưng của dữ liệu
Bài đăng này đã không được cập nhật trong 7 năm
Chào mọi người, như chúng ta đều biết tiền xử lý dữ liệu là giai đoạn rất quan trọng trong việc xây dựng một mô hình học máy tốt. Trong series lần này mình sẽ giới thiệu với mọi người series Understanding Feature Engineering của Dipanjan (DJ) Sarkar. Đây là series mình nghĩ là rất cơ bản để mọi người tiếp cận với các kỹ thuật của feature engineering. Vì mình dịch lại dựa trên ý hiểu của mình nên sẽ có những sai xót mong mọi người góp ý. Series này sẽ bao gồm 5 phần như sau:
Phần 1: Giới thiệu feature engineering, vai trò của feature engineering với việc xây dựng mô hình học máy, cơ bản về đặc trưng của dữ liệu.
Phần 2: Feature engineering với dữ liệu dạng số liên tục (Continuous Numeric Data)
Phần 3: Feature engineering với dữ liệu dạng category (Categorical Data)
Phần 4: Phương pháp xử lý truyền thống với dữ liệu dạng văn bản (Text Data)
Phần 5: Phương pháp nâng cao để xử lý dữ liệu dạng văn bản, phi cấu trúc
Giới thiệu
Mọi người thường nói "Tiền khiến cho thế giới chuyển động" dù bạn có đồng ý với điều này hay không thì bạn cũng không thể phủ nhận nó. Tuy nhiên, với thời đại cách mạng kỹ thuật số hiện nay, có lẽ chúng ta đã có một câu nói thích hợp hơn "Data makes the world go round" (Dữ liệu khiến cho thế giới chuyển động). Thật vậy, dữ liệu đã trở thành tài sản quan trọng nhất đối với các doanh nghiệp, tập đoàn, tổ chức bất kể quy mô lớn hay nhỏ. Mọi hệ thống thông minh bất kể độ phức tạp đều cần dữ liệu để có thể vận hành. Hạt nhân của các hệ thống thông minh là một hoặc nhiều thuật toán được xây dựng dựa trên nền tảng machine learning, deep learning hay phương pháp thống kê đều sử dụng dữ liệu để thu thông thông tin, kiến thức. Từ đó cung cấp các dự đoán, thông tin chuyên sâu phù hợp với nhu cầu. Tuy nhiên, hầu hết các thuật toán không làm việc được với các dạng dữ liệu thô. Vì vậy các kỹ thuật xử lý dữ liệu từ dữ liệu thô là vô cùng quan trọng để các thuật toán học máy có thể hiểu và làm việc tốt dữ liệu được cung cấp.
Nhắc lại các bước xử lý một bài toán học máy (machine learning pipeline)
Bất kỳ hệ thống thông minh nào về cơ bản đều bao gồm các bước bắt đầu từ việc nhập dữ liệu thô, sử dụng các kỹ thuật để sắp xếp, xử lý, thiết kế các đặc trưng (feature) và thuộc tính có ý nghĩa từ dữ liệu này. Sau đó, chúng ta thường sử dụng các kỹ thuật như mô hình thống kê hoặc các mô hình học máy để xây dựng các mô hình với mục đích giải quyết yêu cầu đặt ra. Một quy trình tiêu chuẩn điển hình dựa trên mô hình tiêu chuẩn công nghiệp CRISP-DM được mô tả như hình dưới đây.
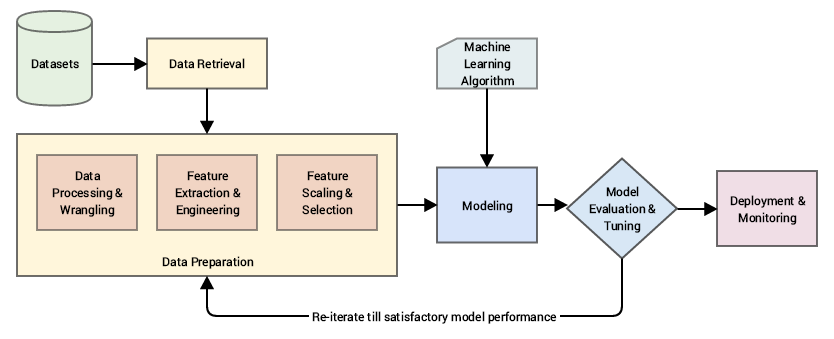
Việc đưa trực tiếp dữ liệu thô vào các mô hình học máy hay thông kê sẽ rất khó cho chúng ta được một kết quả hay hiệu suất như mong muốn vì các thuật toán không có đủ thông minh để tự động trích xuất các đặc trưng (feature) có ý nghĩa với chúng (hiện nay đã có một số kỹ thuật trích xuất đặc trưng tự động với các phương pháp deeplearning ở một mức độ nào đó). Với series này, chúng ta sẽ tập trung vào việc chuẩn bị dữ liệu (giai đoạn data preparation trong hình trên). Ở giai đoạn này, chúng ta sẽ xử dụng các phương pháp khác nhau để trích xuất các thuộc tính hoặc tính năng có ý nghĩa từ dữ liệu thô sau khi trải qua quá trình sắp xếp và tiền xử lý cần thiết.
Sự cần thiết của Feature Engineering
Feature Engineerning là một giai đoạn không thể thiếu trong quá trình phát triển bất kỳ một hệ thống thông minh nào. Mặc dù hiện nay chúng ta có rất nhiều các phương pháp mới như học sâu, siêu mô hình hỗ trợ học máy tự động (automated machine learning), tuy nhiên với mỗi vấn đề cụ thể cần giải quyết luôn có những đặc trưng quan trọng hơn, có giá trị hơn để quyết định hiệu suất hệ thống của bạn. Feature Engineering vừa là nghệ thuật cũng là một môn khoa học và đây là lý do để các nhà khoa học dữ liệu thường dành tới 70% thời gian của họ cho giai đoạn chuẩn bị dữ liệu trước khi xây dựng mô hình. Dưới đây chúng ta có thể xem qua một vài trích dẫn liên quan đến feature engineering của các nhà khoa học dữ liệu nổi tiếng.
“Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.” — Prof. Andrew Ng.
Điều này về cơ bản là củng cố thêm những gì chúng ta đã đề cập đến trước đó: Các nhà khoa học dữ liệu dành 70% thời gian của họ cho giai đoạn feature engineering. Đây là một quá trình khó khăn đòi hỏi cả kiến thức chuyên ngành và tính toán toán học.
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.” — Dr. Jason Brownlee
Câu nói trên cho chúng ta một cái nhìn về feature engineering. Đây là quá trình biến đổi dữ liệu thành các đặc trưng đóng vai trò là đầu vào cho các mô hình học máy. Các đặc trưng được xử lý tốt sẽ nâng cao hiệu suất của mô hình. Các đặc trưng cũng ảnh hưởng rất bởi vấn đề cần giải quyết. Do đó, mặc dù các tác vụ học máy có thể giống nhau trong các bài toán như phân loại thư rác hoặc phân loại chữ số viết tay... thì các đặc trưng phù hợp, cần được trích xuất ra trong mỗi kịch bản sẽ là rất khác nhau.
Giáo sư Pedro Domingos từ đại học Washington trong bài viết “A Few Useful Things to Know about Machine Learning” đã viết như sau:
“At the end of the day, some machine learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used.” — Prof. Pedro Domingos
Và trích dẫ cuối cùng dưới đây là Xavier Conort một Grandmaster của Kaggle về feature engineering. Như các bạn đã biết, mọi vấn đề gặp phải trong thực tế của machine learning được chia sẻ rất thường xuyên trên Kaggle.
“The algorithms we used are very standard for Kagglers. …We spent most of our efforts in feature engineering. … We were also very careful to discard features likely to expose us to the risk of over-fitting our model.” — Xavier Conort
Cơ bản về đặc trưng của dữ liệu
Một đặc trưng (feature) thường là một đại diện cụ thể trên dòng đầu tiên của dữ liệu thô, là một thuộc tính riêng lẻ, có thể đo lường và mô tả bởi một cột trong tập dữ liệu. Lấy ví dụ với một tập dữ liệu hai chiều, mỗi observation (quan sát) được mô tả bởi một hàng và mỗi đặc trưng được mô tả bởi một cột, sẽ có giá trị cụ thể cho mỗi đặc trưng của từng quan sát.
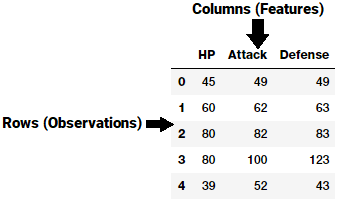
Như ví dụ ở hình trên, mỗi hàng thường biểu thị một vectơ đặc trưng và tập hợp tất cả các đặc trưng trên tất cả các quan sát tạo thành một ma trận hai chiều còn được gọi là feature-set. Thông thường, các thuật toán học máy hoạt động với các ma trận số hóa hoặc tenxo bởi vậy hầu hết các kỹ thuật feature engineering sẽ xử lý việc chuyển đổi dữ liệu thô thành các dạng biểu diễn số học giúp các thuật toán có thể dễ dàng hiểu được.
Các đặc trưng có thể chia thành hai loại chính:
- Đặc trưng thô (Raw features): là các đặc trưng vốn có được lấy trực tiếp từ tập dữ liệu mà không cần sử dụng thêm thao tác kỹ thuật nào
- Đặc trưng phát sinh (Derived features): là các đặc trưng được thu được sau quá trình feature engineering, là kết quả của quá trình trích xuất và xử lý các đặc trưng có sẵn. Ví dụ, chúng ta có một đặc trưng thô là "sinh nhật" của nhân viên và chúng ta có thể dễ dàng có được một đặc trưng mới là "tuổi" của các nhân viên đó bằng cách trừ năm hiện tại cho năm sinh của họ.
Có rất nhiều loại và nhiều định dạng dữ liệu khác nhau bao gồm cả dữ liệu có cấu trúc và dữ liệu không có cấu trúc. Trong phần tiếp theo của series này, chúng ta sẽ thảo luận về các cách tiếp cận khác nhau để xử lý dữ liệu có cấu trúc dạng số liên tục (continuous numeric data). Tất cả những ví dụ này là một phần của một trong những cuốn sách gần đây của tác giả ‘Practical Machine Learning with Python’, mọi người có thể sử dụng các bộ dữ liệu và code liên quan tại GitHub. Tác giả cũng gửi lời cảm ơn chân thành đến Gabriel Moreira đã cung cấp những gợi ý tuyệt vời về feature engineering!
All rights reserved
