6. Những điểm hạn chế của Machine Learning
Bài đăng này đã không được cập nhật trong 7 năm
Chào mừng các bạn đến với bài thứ 6 trong loạt bài "From AI to Strategy". Hôm nay chúng ta sẽ không bàn tới những sự cao siêu của AI mà sẽ bàn tới những hạn chế của AI hiện tại hay chính xác hơn là của Machine Learning. Đầu tiên hãy tới với sự ảo tưởng của các cấp lãnh đạo và khách hàng của chúng ta.
1. Sự thổi phồng:
- Với sự thổi phồng từ báo chí, không ít hay nếu không muốn nói là hầu hết những lãnh đạo của các công ty chưa được tiếp cận với AI trước kia và kể cả những khách hàng mong muốn outsource phần tính năng AI cũng đều lầm tưởng rằng AI hiện nay có thể làm được mọi thứ, chỉ cần có được chuyên gia là mọi bài toán sẽ được giải quyết. Đây là một suy nghĩ sai lầm, dẫn đến sự thất bại của nhiều dự án và dĩ nhiên hao tốn tiền của của chính những người muốn áp dụng nhưng lại ảo tưởng về sức mạnh của AI.
- Tôi từng được biết tới có khách hàng mong muốn tạo ra một trợ lý ảo có thể trò chuyện như tâm giao tri kỉ với con người. Khách hàng này thậm chí còn chưa biết rằng chỉ việc trò chuyện được với người (trong trường hợp này họ muốn nói bằng tiếng Anh nhưng lại cho người Nhật) đã là một thử thách. Những khách hàng này họ chỉ quan tâm tới việc liệu chi phí có khả thi không, họ chẳng những không có tí chút kiến thức gì về việc phát triển sản phẩm AI mà còn chẳng biết rằng nếu nhận được sản phẩm, bạn sẽ đánh giá nó như thế nào. Phần lớn họ chỉ đánh giá bằng cảm tính, dùng thấy hợp với mình chắc là cũng hợp với user.
- Lãnh đạo các công ty cũng tương tự như vậy, họ cũng như khách hàng của đội AI, nếu họ không hiểu rằng "nhà văn nói láo, nhà báo nói phét", lên mạng đọc vài ba tờ báo và nghĩ rằng thuê vài người có trình độ chút là được. Điều đáng nói là họ còn chẳng biết nên thuê ai, giỏi quá thì chi phí cao, mà có kém thì họ cũng chẳng biết là kém, và dĩ nhiên nhân lực của họ sẽ rất ngoan, dự án nào các sếp đưa ra cũng nhận. Như bài trước tôi có nhắc tới những điểm đặc biệt của công ty AI, nếu công ty bạn đến việc kiếm dữ liệu còn chưa từng nghĩ tới một cách nghiêm túc, thì e rằng chuyện xây dựng sản phẩm cũng chỉ là viển vông. Các dự án sẽ chỉ được đưa ra với tiêu chí là chính xác được bao nhiêu, chứ không hề có bàn tới nó có khả thi hay không !
2. Những điều mà Machine Learning làm được/không làm được hiện nay:
- Trước tiên hãy điểm lại một số ứng dụng mà Machine Learning (trong trường hợp này là Supervise Learning) có thể làm :
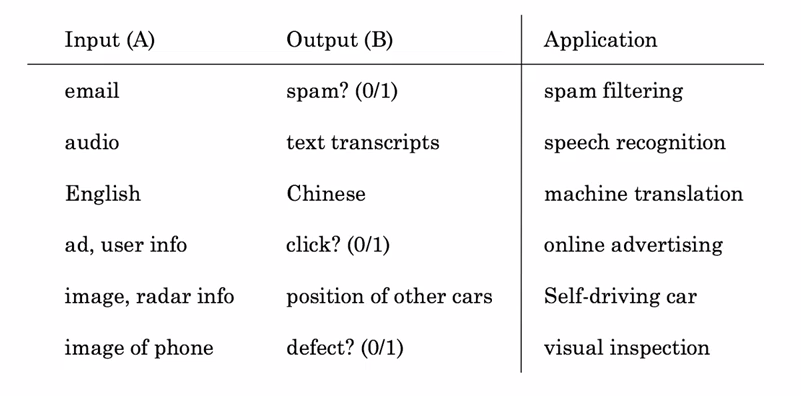
- Một điểm bạn dễ nhận thấy với những ứng dụng trên là chúng ta sẽ chỉ cần 1s (hoặc thậm chí ít hơn) để đưa ra được output. Bạn nhìn vào email có thể biết ngay đó là email spam hay không, nghe đoạn ghi âm có thể biết nội dung là gì, thông dịch giữa các ngôn ngữ, quan sát vị trí các xe trên đường hay phát hiện điện thoại có bị trày xước, nứt vỡ chỉ qua một tấm ảnh. Đây cũng là một kết luận (của GS Andrew Ng) về những ứng dụng mà Supervise Learning có thể đã và sẽ sớm làm được. Vậy nên nếu tính năng bạn muốn có thể được con người làm trong 1s, thì có lẽ nó sẽ khả thi.
- Đối trọng với những điều trên là vô vàn những thứ mà Machine Learning hiện tại chưa thể làm. Chẳng hạn như bạn nghĩ tới việc đưa cho vào máy tính một vài website có chứa thông tin về thị trường hiện tại và muốn nó tổng kết thành một bản báo cáo dài vài chục trang thì bạn đang đòi hỏi quá mức mà Machine Learning hiện tại có thể làm. Hãy thử nghĩ mà xem, đến bản thân con người sẽ mất không ít thời gian cho những công việc tương tự.
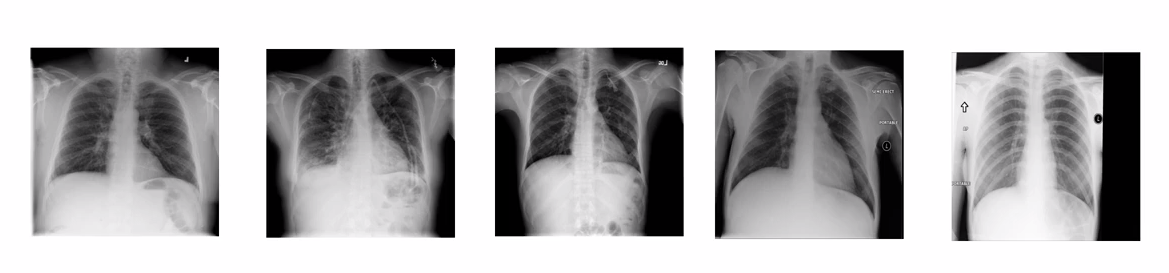
- Một ví dụ khác, ta muốn AI nhận vào hình chụp phim X-ray, và mong muốn nó dự đoán xem bệnh nhân có bị viêm phổi hay không. Thì điều đó là khả thi trong khi nếu ta muốn AI học từ muốn cuốn sách y khoa để làm điều tương tự thì hiện nay AI vẫn chưa thể làm được.
- Tuy nhiên điều này không có nghĩa là cứ một ứng dụng phức tạp cần nhiều hơn 1s của con người thì Machine Learning không thể làm được. Nếu bạn có thể chia nhỏ ứng dụng này thành nhiều tính năng nhỏ mà mỗi tính năng chỉ cần < 1s của con người thì Machine Learning có thể tạo ra một chuỗi các mô hình để giải quyết từng tính năng một. Chẳng hạn như bạn muốn làm một cửa hàng bán lẻ tự động như Amazon Go, bạn có thể chia nhỏ thành các tính năng như sau:
- Phát hiện người mua lấy sản phẩm từ kệ hàng
- Xác định sản phẩm được người mua lấy là sản phẩm nào
- Phát hiện người mua trả lại sản phẩm lên kệ hàng
- Xác định sản phẩm được người mua trả lại là sản phẩm nào
- Một vài tính năng đơn giản khác như thanh toán tiền, lập hóa đơn...
3. Điều kiện nào thì Machine Learning hoạt động hiệu quả và ngược lại? :
- Tính khả thi của dự án AI ngoài việc phụ thuộc vào tính năng mà bạn muốn hướng tới còn phụ thuộc vào những yếu tố về tài nguyên khác như số lượng dữ liệu, chi phí tính toán..
- Khi bạn có một tính năng muốn phát triển và bạn có khá nhiều dữ liệu (cả đầu vào tương ứng với đầu ra - input & output mapping) thì tính khả thi của tính năng đó là rất cao, khả năng máy học xog sẽ đưa ra được độ chính xác cao là rất lớn. (Thường là hàng ngàn, hay thậm chí lên tới hàng triệu cặp input-output)
- Ngược lại khi bạn có trong tay số lượng dữ liệu ít ỏi hay chỉ là những dữ liệu bạn tự mình gán nhãn thủ công thì khả năng dự án thất bại là rất lớn.
- Chẳng hạn bạn muốn làm hệ thống tự động lọc email của khách hàng gửi tới thành cách loại yêu cầu khác nhau (như yêu cầu bảo hành, cần tư vấn, yêu cầu hoàn tiền ...) thì việc bạn đã có sẵn dữ liệu trong hệ thống cũ là khá tốt, nhưng nếu bạn muốn máy tự động trả lời email một cách con người thì có lẽ bạn cần phải có tới hàng trăm ngàn hay thậm chí hàng triệu cặp email của khách và email trả lời của nhân viên.
- Ngoài tính khả thi do nguồn dữ liệu lớn hay nhỏ thì chi phí tính toán cũng làm đau đầu nhiều start-up hiện nay. Machine Learning, đặc biết là Deep Learning yêu cầu chi phí tính toán lớn, nếu hệ thông của bạn chỉ chạy dựa vào CPU của máy tính thông thường thì thời gian chờ đợi thường rất lớn và số lượng người dùng lớn cũng khiến cho chi phí này càng tăng rõ rệt. Có một vài giải pháp như sử dụng các loại Cloud như Google/Amazon.. nhưng chi phí cũng thường đội lên khủng khiếp khi sản phẩm của bạn được nhân rộng. Nếu phát triển lâu dài thì việc xây dựng cho mình một hệ thống máy riêng là điều cần thiết.
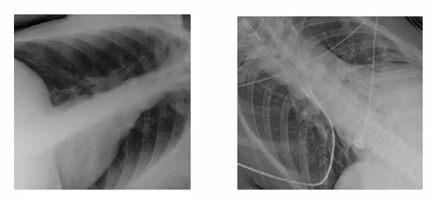
- Một điểm nữa cũng khiến cho Machine Learning hoạt động kém hiệu quả là việc training trên một loại dữ liệu nhưng lại đem nó đi sử dụng với một loại dữ liệu mới. Kể cả khi 2 loại dữ liệu này không quá khác nhau đối với con người. Chẳng hạn với ví dụ về phim X-ray ở trên, nếu dữ liệu training là ảnh dọc như trong hình thì với những bức ảnh có độ nghiêng lớn máy có xu hướng dự đoán sai.
- Bạn thử dạy máy nghe tiếng miền Bắc rồi đem vào Sài Gòn dùng xem, người miền Nam sẽ ném chúng đi trong một nốt nhạc

4. Tổng kết:
- AI không hoàn hảo, phương pháp phổ biến nhất hiện nay của nó là Supervise Learning gặp rất nhiều trở ngại trong việc phát triển bên cạnh sự thiếu khả thi trong nhiều dự án.
- Machine Learning phụ thuộc rất nhiều vào dữ liệu, nếu không có trong tay những mô hình có thể kế thừa (như Oneshot Learning) thì khó có thể dễ dàng phát triển dự án với lượng dữ liệu ít ỏi được.
- Chi phí tính toán cũng là một vấn đề đau đầu cho các start-up.
- Cần nhận thức rõ ràng về loại dữ liệu training và loại dữ liệu thực tế để AI có thể hoạt động tốt nhất.
- Hẹn gặp lại các bạn trong bài viết tiếp theo nhé.
All rights reserved
