Thực đơn và công thức cho Machine Learning
Bài đăng này đã không được cập nhật trong 9 năm
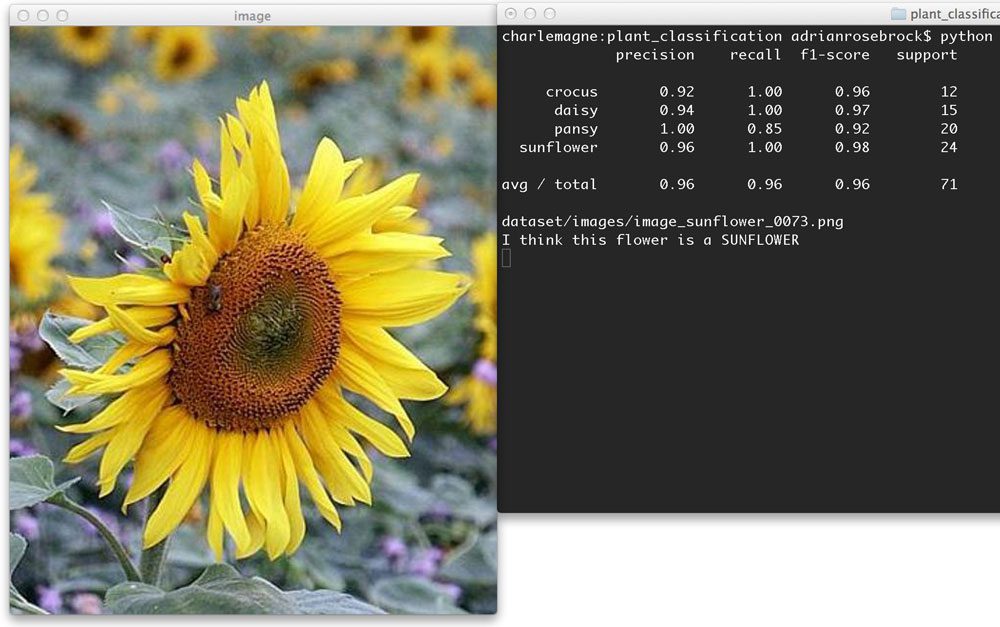
Trong số các xu hướng nổi bật năm 2016 ta không thể không nhắc đến Machine Learning - Học máy, một công nghệ được ưa chuộng và áp dụng ở rất nhiều lĩnh vực tiên tiến. Bài viết này tôi đưa ra một vài công thức lập trình đơn giản vận dụng từ Machine Learning. Ở Machine Learning, người ta sử dụng 2 thư viện nguồn mở, đó là:
- sckit-learn
- TensorFlow
Viết code phân biệt Táo và Cam
Nếu như với cách làm thủ công thông thường thì máy tính sẽ đến số pixel của màu cam và so sánh với số pixel của màu xanh để phân biệt. Tuy nhiên cách này không thể áp dụng với một số trường hợp như là hình ảnh màu đen trắng, hoặc thi thoảng vẫn có những trường hợp khớp không đúng, thì ta lại phải phản ảnh code lại mỗi lần xảy ra lỗi như vậy.
Nhưng với một thuật toán mà nó hiểu, nắm rõ quy tắc thì chúng ta có thể tránh được. Machine Learning chính là cho máy tính học công cụ phân loại có tên Classifier (một loại hàm số).
Input data ⇒ Classifier ⇒ Label
※picture ⇒ Classifier ⇒ Orange
※mail ⇒ Classifier ⇒ SPAM
Cái này gọi là Học có kèm giáo sư hỗ trợ (Supervised Learning), giúp tìm ra cấu trúc mẫu từ dạng dữ liệu đơn giản để tạo nên cơ cấu phân loại.
Mục đích:
-
Tạo hàm phân loại các loại hoa quả
-
Tiếp nhận input các thông tin cơ bản liên quan đến mô tả cho các loại hoa quả, rồi dự đoán output ra dựa theo tính đặc trưng (giá trị đo lường).
Mã hoá code bằng sckit-learn
- Cách install sckit-learn
$ sudo pip install -U numpy
$ sudo pip install -U scipy
$ sudo pip install -U scikit-learn
① Thu thập dữ liệu cho learning
| Weight | Texture | Label |
|---|---|---|
| 150g | Bumpy | Orange |
| 170g | Bumpy | Orange |
| 140g | Smooth | Apple |
| 130g | Smooth | Apple |
Trên đây là những dữ liệu mà tôi muốn cho công cụ phân loại học, ghi nhớ. Dữ liệu cho learning mà ngon lành thì công cụ học phân loại cũng chính xác cao hơn.
Chuẩn bị dữ liệu learning trên code.
Chúng ta cần chuẩn bị 2 biến số là “Lượng đặc trưng" cho input và “Label" cho output.
Lúc này thì dữ liệu của Lượng đặc trưng không phải là String, ta cần thay số trị, coi Bumpy là 0, Smooth là 1. Và cũng coi giá trị cho Táo là 0, Cam là 1.
② Cho công cụ phân loại học, ghi nhớ
Lần này ta sử dụng Cây quyết định Decision Tree.
Công cụ phân loại coi như là một hòm quy tắc.
Thuật toán learning chính là trình tự tạo quy tắc (tức là tạo ra bằng việc phát hiện ra công trúc bên trong dữ liệu learning).
Tạo công cụ phân loại
Ở bước này nó vẫn chỉ như là cái hộp trống rỗng, chưa hề biết thế nào là quả Táo hay Cam mà ta đang đề cập đến.
Chúng ta cần đến thuật toán learning để cho công cụ học
clf = tree.DecisionTreeClassifier()
Ở sckit có bao gồm thuật toán learning bên trong đối tượng object công cụ phân loại, có tên gọi là Fit. Fit = ”Tìm ra cấu trúc pattern bên trong dữ liệu”
clf = clf.fit(features,labels)
③Phân loại loại hoa quả mới
Input Lượng đặc trưng của một loại hoa quả mới cho công cụ phân loại. (Bumpy 150g)
print clf.predict([[150,0]])
Output sẽ trả về giá trị 1, tức là nó hiểu phân loại quả Cam.
test.py
from sklearn import tree
features = [[140,1],[130,1],[150,0],[170,0]]
labels = [0,0,1,1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(features,labels)
print clf.predict([[150,0]])
Chúng ta cùng thực nghiệm mới về tính vận dụng của nó trong phần xử lý bổ sung dữ liệu mới tiếp theo đây.
Trước hết, tôi cũng giới thiệu một vài máy phân loại thông dụng:
- ANN(artificial neural network)
- SVM(Support Vector Machine)
Lý do ta nên sử dụng Decision tree cho lần vừa rồi bởi vì đây cũng là một model hiểu được chính xác vì sao máy phân loại cần đưa ra quyết định (hay nói cách khác là nó hiểu rất nhanh).
Set data sử dụng cho lần này -Iris-
https://en.wikipedia.org/wiki/Iris_flower_data_set
Iris có thể xác định tên một loại hoa dựa theo các dữ liệu Lượng đo lường như là chiều dài, rộng của cánh hoa. Ở đây ta ví dụ với set data của 3 loại hoa khác nhau (setona,versicolor,virginica), chuẩn bị với tổng cộng mỗi loại 50 ví dụ mô tả (50 * 3 = 150). Ta sẽ sử dụng 4 Lượng đặc trưng gồm chiều dài và chiều rộng của đài hoa và cánh hoa cho các ví dụ.
| Sepal length | Sepal width | Petal length | Petal width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | I. setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | I. setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | I. versicolor |
Mục tiêu thực hiện:
- Sử dụng set data
- Áp dụng cho công cụ phân loại học, ghi nhớ
- Sau đó sử dụng máy phân loại đó cho xác định bất kì loại hoa nào khác mà ta thêm vào
- Thêm thực hành cho học nhớ của thông tin cho Cây nữa
1.Import data
Import set data của Iris. Các bạn đừng quên data (tên hoa) và meta data (Lượng đặc trưng) nữa nhé.
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
>>> print iris.feature_names
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
>>> print iris.target_names
['setosa' 'versicolor' 'virginica']
Cho Lượng đặc trưng vào biến số data.
>>> print iris.data[0]
[ 5.1 3.5 1.4 0.2]
CHo Label vào biến số target.
>>> print iris.target[0]
0
※Kết quả trả về là 0 nên nó thể hiện cho setosa
Chúng ta cũng cần một vài sample data để sau cho máy phân loại test về độ chuẩn xác. Dữ liệu này được gọi là test data. Việc test cũng rất quan trọng giống như khi lập trình, luôn cần phải đảm bảo vận hành chính xác.
Tuy nhiên lần này thì ta cũng có nhiều ví dụ cho mỗi loại rồi nên không cần phải thêm test data nữa.
# training data
train_target = np.delete(iris.target,test_idx)
train_data = np.delete(iris.data, test_idx, axis=0)
# testing data
test_target = iris.target[test_idx]
test_data = iris.data[test_idx]
2. Cho công cụ phân loại học nhớ
Sử dụng máy phân loại Decision Tree cho học nhớ data learning.
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf.fit(train_data, train_target)
3. Xác định thêm loài hoa mới
Để máy phân loại xác định bằng cách
>>> print test_target
[0 1 2]
Nếu bạn còn muốn chắc chắn hơn nữa thì thực hiện thêm test data, cho ra kết quả như trên là OK rồi đó.
print clf.predict(test_data)
[0 1 2]
4. Cách hoạt động của công cụ phân loại áp dụng cho Cây
pip install pydotplus
pip install graphviz
pip install --upgrade IPython
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
impurity=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("iris.pdf")
open -a preview iris.pdf

Ở các điểm giao của Lượng đặc trưng, chúng ra xác định với giá trị 1 (Yes) 0 (No). Ví dụ khi ta xác định được node đầu tiên có cánh hoa (petal) rộng 0.8cm trở xuống, nếu trả về True thì tiến sang trái, giá trị False thì tiến sang phải.
>>> print iris.feature_names, iris.target_names
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] ['setosa' 'versicolor' 'virginica']
>>> print test_data[1], test_target[1]
[ 7. 3.2 4.7 1.4] 1
- pental width 1.4 lớn hơn 0.8 → False. chuyển sang phải
- pental width xác định xem giá trị có nhỏ hơn 1.75 không, nếu khoảng 1.4 thì trả giá trị True, chuyển sang trái
- pental length xác định xem giá trị có nhỏ hơn 4.95 không, nếu khoảng 4.7 thì trả giá trị True, chuyển sang trái.
- pental width xác định xem giá trị có nhỏ hơn 1.65 không, nếu khoảng 1.4 thì trả giá trị True.
- Kết quả xác định các thông số như vậy, dự đoán sẽ là hoa versicolor.

All rights reserved
