@maitrungduc1410 cho e hỏi là tại sao a đã dùng apk add ext pdo-mysql rồi mà bên dưới a lại dùng docker-php-ext-install để install nó tiếp rồi còn enable nữa ạ?
HIện tại e cũng đang làm việc với môi trường ubuntu, việc cài php và các ext của nó e thấy khá là đơng giản. Nhưng với docker và image alpine thì e ban đầu cứ nghĩ cũng tương tự thôi mà hóa ra không phải. E có thử dùng apk add để cài các ext cho php 7.4 / 8.1 / 8.2 thì chi có mỗi 8.1 là cài được với syntax là "apk add php81-<ext>". E có dùng cả docker-php-ext-install thì khi cài ext mbstring thì cũng gặp lỗi khi cài gần xong. Em cũng chả hiểu tại sao. A có thể cho e đường link hoặc keyword liên quan đến mấy vấn đề này được ko ạ.
@WRBKOR23 mongo + redis thì bên trong container nó đã luôn chạy port 27017 và 6379 rồi, e ko đổi được (Trừ khi e tự build lại image của nó, mà chả ai rảnh mà làm vậy )
ở đây e chỉ có thể đổi port mà e map ra môi trường ngoài thôi, ví dụ:
db:image: mongo:4.4ports:-"8888:27017"
Còn về việc DB_NAME, thì Mongo khác với các loại SQL DB đó là ta ko cần tạo trước db (collection), mà khi ta insert vào mongo sẽ check nếu collection (db) chưa được tạo thì nó sẽ tạo cho.
Nếu e muốn tạo sẵn collection ngay lúc chạy container mongo thì e truyền thêm biến môi trường MONGO_INITDB_DATABASE là được. Xem thêm ở đây nhé: https://hub.docker.com/_/mongo
@maitrungduc1410 em cảm ơn, nhưng e có thắc mắc là tại sao a dùng cả apk add và docker install ạ, ví dụ như cùng ext pdo_mysql, và chỉ dùng 1 trong 2 cách có được ko ạ, e thấy a dùng cả 2.
@maitrungduc1410 cho e hỏi là cái db_name thì sao mà mongo nó hiểu để tạo ra ạ. Và nếu mình muốn đổi port của mongo và redis thì phải làm sao ạ? Em cảm ơn
không biết e có giải thích khó hiểu k, nhưng đây ko phải cái e đang hỏi @@,
hiện tại e đang triển khai rest api. việc update dc request cho 1 router put.
Chỉ có 1 router put vì e đang làm là user vào trang chỉnh sửa post ( trong trang này có cho phép chỉnh sửa số lượng tags, .... ) sau đó user click save.
toàn bộ data sẽ đưa về router put này.
Vấn đề là với 1 cục data giá trị mới này ta nên xử lý như thế nào để update do ta không biết trong cục data này giá trị nào giữ nguyên, giá trị nào đã thay đổi.
vậy nên ta nên lọc những cái giá trị đã dc thay đổi này ( việc tìm dc cái nào thay đổi e đang thấy rất phức tạp ) và update nó vào sql, hay xóa toàn bộ data post cũ, và create new post luôn. ( nó đơn giản nhưng xử lý dư thừa)
Vậy nên vấn đề e là caasch xửa lý data trc khi đưa nó vào sql thay vì cho nó vào sql ntn.

THẢO LUẬN
@lengocanh vâng anh, mà anh còn giữ source bài này không ạ 🥹
Bạn có thể hướng dẩn mình cách build ra ios và cài vào iPhone được không ? Thank bạn nhiều lắm !
@maitrungduc1410 cho e hỏi là tại sao a đã dùng apk add ext pdo-mysql rồi mà bên dưới a lại dùng docker-php-ext-install để install nó tiếp rồi còn enable nữa ạ? HIện tại e cũng đang làm việc với môi trường ubuntu, việc cài php và các ext của nó e thấy khá là đơng giản. Nhưng với docker và image alpine thì e ban đầu cứ nghĩ cũng tương tự thôi mà hóa ra không phải. E có thử dùng apk add để cài các ext cho php 7.4 / 8.1 / 8.2 thì chi có mỗi 8.1 là cài được với syntax là "apk add php81-<ext>". E có dùng cả docker-php-ext-install thì khi cài ext mbstring thì cũng gặp lỗi khi cài gần xong. Em cũng chả hiểu tại sao. A có thể cho e đường link hoặc keyword liên quan đến mấy vấn đề này được ko ạ.
@moemoe Như mình đã nói, với router PUT thì bạn ko cần so sánh, cứ đập thẳng vào SQL là được.
Ví dụ như typeorm nếu bạn bật cascade UPDATE, thì nó sẽ update luôn nguyên object và relation nếu nó có sẵn ID.
Còn tags. nếu ORM không support, thì trước khi update bạn xóa hết relation, sau đó chạy for để add lại những tags có trong array.
Em đang chạy command ở thư mục laravel\learning-docker\docker-laravel-realtime-chat-app> ạ
Dạ. cấu trúc folder của em đây ạ. A xem giúp em với ạ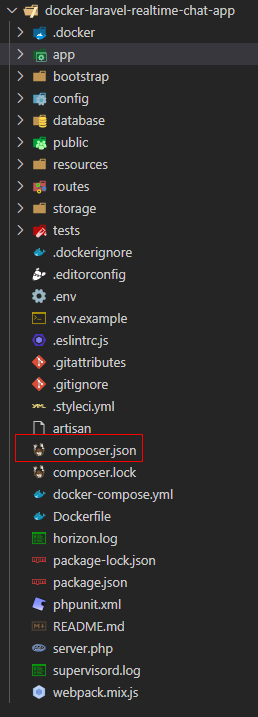
@nguyendt mình lỡ xóa mất trên driver rồi. Bạn có thể thử đề CTF về .NET deserialize mình ra trên viblo ctf https://ctf.viblo.asia/puzzles/book-store-xd6lrvs8np3
tks
khó hiểu =-))
@manhhung1511 lỗi rõ ràng rồi kìa e,
ko thể tìm thấy file composer.json ở đường dẫn /app.
Ở môi trường ngoài e có file đó ko? e đã COPY vào chưa?
Và sau đó em có bỏ --no-suggest thì gặp lỗi này ạ
Em chào anh. Em có cài dependencies (composer) theo cách anh hướng dẫn và bị lỗi này ạ. Mong anh giúp đỡ em ạ
Link source code CTF không truy cập được anh ạ
@WRBKOR23 mongo + redis thì bên trong container nó đã luôn chạy port 27017 và 6379 rồi, e ko đổi được (Trừ khi e tự build lại image của nó, mà chả ai rảnh mà làm vậy )
)
ở đây e chỉ có thể đổi port mà e map ra môi trường ngoài thôi, ví dụ:
Còn về việc DB_NAME, thì Mongo khác với các loại SQL DB đó là ta ko cần tạo trước db (collection), mà khi ta insert vào mongo sẽ check nếu collection (db) chưa được tạo thì nó sẽ tạo cho.
Nếu e muốn tạo sẵn collection ngay lúc chạy container mongo thì e truyền thêm biến môi trường
MONGO_INITDB_DATABASElà được. Xem thêm ở đây nhé: https://hub.docker.com/_/mongo@WRBKOR23 e chỉ dùng 1 cũng đc nhé.
Một số trường hợp thì dùng
docker-php-ext-enablesẽ tiện hơn thôi@maitrungduc1410 em cảm ơn, nhưng e có thắc mắc là tại sao a dùng cả apk add và docker install ạ, ví dụ như cùng ext pdo_mysql, và chỉ dùng 1 trong 2 cách có được ko ạ, e thấy a dùng cả 2.
@maitrungduc1410 cho e hỏi là cái db_name thì sao mà mongo nó hiểu để tạo ra ạ. Và nếu mình muốn đổi port của mongo và redis thì phải làm sao ạ? Em cảm ơn
không biết e có giải thích khó hiểu k, nhưng đây ko phải cái e đang hỏi @@, hiện tại e đang triển khai rest api. việc update dc request cho 1 router put. Chỉ có 1 router put vì e đang làm là user vào trang chỉnh sửa post ( trong trang này có cho phép chỉnh sửa số lượng tags, .... ) sau đó user click save. toàn bộ data sẽ đưa về router put này. Vấn đề là với 1 cục data giá trị mới này ta nên xử lý như thế nào để update do ta không biết trong cục data này giá trị nào giữ nguyên, giá trị nào đã thay đổi. vậy nên ta nên lọc những cái giá trị đã dc thay đổi này ( việc tìm dc cái nào thay đổi e đang thấy rất phức tạp ) và update nó vào sql, hay xóa toàn bộ data post cũ, và create new post luôn. ( nó đơn giản nhưng xử lý dư thừa)
Vậy nên vấn đề e là caasch xửa lý data trc khi đưa nó vào sql thay vì cho nó vào sql ntn.
Và tất nhiên data đến server e đã cho validation.
Bài viết rất hay ạ, cảm ơn tác giả.
@maitrungduc1410 Dạ. em cảm ơn anh ạ