Oke cuối cùng cũng phát hiện ra lỗi, bạn để ý khi sử dụng đoạn failedValidation thì bạn phải thêm các class mà bạn sử dụng bên trong hàm này nhé, ví dụ như đoạn trên thì sẽ use như sau
Hiện tại em có sử dụng 1 app điện thoại có sử dụng FCM để chứng thực otp
Khi login vào app nó phát sinh 1 fcm_token như sau "fcm_token":"fg5rF-27mpc:APA91bGA0DUIEo6JyIS9083XyZ5r-bIeCCHv5EmjG-hsizzua0M6k-A9xS7pkL3n7WxpUacKmU2RH8lflJ0MtFlAdxv87VDqEWQ0e6ls7vGtM0P6XdTKITVcodyhUqZMG1v5CZLP-DdL"
Có cách nào mình có thể bắn otp tới fcm token đã được đăng ký khi login để lấy mã otp xác thực không ạ.
Chủ yếu là bạn phải dự đoán xem dữ liệu của mình có tăng lên không ?. Số lượng user có tăng lên nũa không thêm nữa là data lưu theo kiểu vĩnh viễn hay lưu theo kiểu xóa những data cũ. Từ đó bạn có thể chọn Storage cho phù hợp. Còn hợp lý và có nhiều máu và hồi máu nhanh thì dùng AWS nhưng dữ liệu càng nhiều thì máu càng chát.
Theo mình biết mấy web phim hay có kiểu mua tài khoản Drive ultimate để lưu trữ. Và việc họ cần làm chỉ là tối ưu truy cập và download thôi .

THẢO LUẬN
nó hiện lên discussions, ngày nào chả check cái đó =))
Bạn gửi cho mình xem cái postman bạn call api như nào
Vào tận đây để reply comment cơ à, chú có tâm quá =))
Chị Duyên có thể chia sẻ cho em 1 chút kinh nghiệm test website được không ạ. Em cảm ơn chị!
Chào bạn, bạn có thể cho mình xin email để trao đổi một số cơ hội hợp tác được không ạ?
Ok anh
làm hẳn 1 series handbook phỏng vấn Laravel dev luôn đi bạn!
bạn đã đăng nhập để lấy được access_token chưa
cho vào seri bài đi clip cho khỏe a ei =))
Hi bạn, cho mình hỏi chút
public function user(Request $request)
Cái hàm lấy thông tin user này mình ko hiểu lắm nhỉ, mình chạy api thì ko thấy trả về thông tin gì, Bạn giải thích giúp mình với. thank
Cảm ơn bạn
Cảm ơn bạn bài viết rất hay
tổng hợp những kiến thức rất hay.
Oke cuối cùng cũng phát hiện ra lỗi, bạn để ý khi sử dụng đoạn failedValidation thì bạn phải thêm các class mà bạn sử dụng bên trong hàm này nhé, ví dụ như đoạn trên thì sẽ use như sau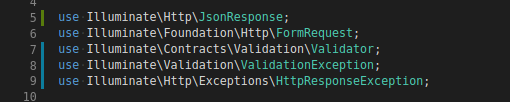
Hiện tại em có sử dụng 1 app điện thoại có sử dụng FCM để chứng thực otp
Có cách nào mình có thể bắn otp tới fcm token đã được đăng ký khi login để lấy mã otp xác thực không ạ.
Mình gửi mail bạn rồi bạn vào xem giúp vs
sao không thấy nội dung thế ạ
ok bạn ak
Chủ yếu là bạn phải dự đoán xem dữ liệu của mình có tăng lên không ?. Số lượng user có tăng lên nũa không thêm nữa là data lưu theo kiểu vĩnh viễn hay lưu theo kiểu xóa những data cũ. Từ đó bạn có thể chọn Storage cho phù hợp. Còn hợp lý và có nhiều máu và hồi máu nhanh thì dùng AWS nhưng dữ liệu càng nhiều thì máu càng chát.
Theo mình biết mấy web phim hay có kiểu mua tài khoản Drive ultimate để lưu trữ. Và việc họ cần làm chỉ là tối ưu truy cập và download thôi .
.