Xử Lý Ngôn Ngữ Tự Nhiên với Python - P6
Bài đăng này đã không được cập nhật trong 4 năm
Conditional Frequency Distributions
Ở bài trước, ta có nhắc tới khái niệm Conditional Frequency Distributions, bài này chúng ta sẽ đi tìm hiểu thêm về nó. Conditional Frequency Distributions hay Phân bố theo tần xuất có điều kiện. Cách dịch là Phân Phối cũng tương tự.
Trong những bài trước, khi tìm hiểu về Phân bố theo tuần xuất, chúng ta thấy rằng mỗi phân bố đều phải có 1 điều kiện. Với các Corpus không được phân loại như các text từ 1-9 thì ta dễ dàng xây dựng các thống kê dựa trên Phân bố theo tần xuất. Sau khi đã cùng nhau tìm hiểu về các loại Corpus mà NLTK cung cấp, ta thấy rằng có những Corpus được phân loại theo nhiều chuyên mục. Bây giờ nếu muốn thống kê số lượng từ xuất hiện nhiều nhất trong mỗi chuyên mục, ta sẽ phải thực hiện nhiều phép Phân bố theo tần xuất, cụ thể hơn là sử dụng hàm FreqDist(). Tuy nhiên, thật may là chúng ta đã có Conditional Frequency Distributions, hiểu đơn giản thì Conditional Frequency Distributions là tập hợp của các Phân bố theo tần xuất. Dưới đây là 1 ví dụ khi sử dụng Conditional Frequency Distributions để tính số lần xuất hiện của từ trong văn bản.
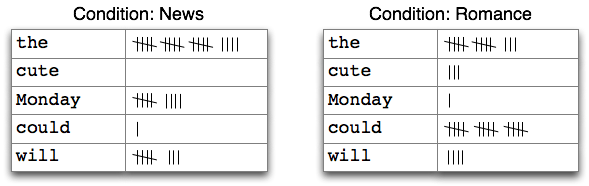 Ta thấy rằng, với mỗi thống kê sẽ có 1 điều kiện, ở đây là điều kiện về chuyên mục mà thống kê này sẽ được chạy, hay các chuyên mục sẽ được thống kê. Mỗi điều kiện tương ứng với tên của một chuyên mục.
Ta thấy rằng, với mỗi thống kê sẽ có 1 điều kiện, ở đây là điều kiện về chuyên mục mà thống kê này sẽ được chạy, hay các chuyên mục sẽ được thống kê. Mỗi điều kiện tương ứng với tên của một chuyên mục.
Điều kiện và Biến cố (Conditions and Events)
Mỗi một Phân bố theo tần xuất có điều kiện (PBTTXCDK) sẽ tính số biến cố xem xét được, ví dụ như sự xuất hiện của một từ trong văn bản. Một PBTTXCDK cần phải ghép cặp các biến cố với các điều kiện, vì nó là tập hợp của các Phân bố theo tuần xuất, mà mỗi Phân bố theo tần xuất lại đi kèm một điều kiện. Do vậy, thay vì xử lý chuỗi các từ thì ta phải xử lý chuối của các cặp. Ví dụ
>>> text = ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
>>> pairs = [('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ...]
Mỗi cặp này sẽ có dạng (điều kiện, biến cố). Nếu chúng ta xử lý Brown Corpus ở bài trước thì có cả thảy 15 điều kiện (cho mỗi chuyên mục) và 1.161.192 biến cố (cho mỗi từ). Trên đây là 2 thành phần cơ bản của một PBTTXCDK
Tính số lượng từ xuất hiện dựa theo thể loại.
Bài trước chúng ta đã tính toán số lần xuất hiện của từ bằng các sử dụng Phân bố theo tần xuất hay hàm FreqDist(). Hàm FreqDist() nhận vào là 1 lists danh sách các từ. Tiếp theo, để tính toán số lần xuất hiện của các từ nằm trong các chuyên mục khác nhau của Brown Corpus, ta sử dụng tới PBTTXCDK, tương ứng ta có hàm ConditionalFreqDist(). Hàm ConditionalFreqDist() nhận vào một lists các cặp như đã đề cập ở trên, bao gốm các cặp (điều kiện, biến cố). Bây giờ hãy thử tạo và xem các cặp (điều kiện, biến cố) ở trong 2 chuyên mục là "news" và "romance".
>>> from nltk.corpus import brown
>>> genre_word = [(genre, word) for genre in ['news', 'romance'] for word in brown.words(categories=genre)]
>>> genre_word[:4]
[('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ('news', 'Grand')]
>>> genre_word[-4:]
[('romance', 'afraid'), ('romance', 'not'), ('romance', "''"), ('romance', '.')]
Vậy là ta đã tạo được các cặp (điều kiện, biến cố) từ các từ và tên chuyên mục. Bước tiếp theo là tính toán số lần xuất hiện của từ theo từng chuyên mục. Đầu tiên hãy xem ta có gì khi sử dụng ConditionalFreqDist().
>>> cfd = nltk.ConditionalFreqDist(genre_word)
>>> cfd
<ConditionalFreqDist with 2 conditions>
>>> cfd.conditions()
['news', 'romance']
Như vậy khi kiểm tra các điều kiện tồn tại trong cfd, ta thấy nó chứa 2 điều kiện tương ứng với tên của 2 chuyên mục. Để truy cập tới kết quả, ta có thể làm như sau
>>> cfd['news']
FreqDist({'the': 5580, ',': 5188, '.': 4030, 'of': 2849, 'and': 2146, 'to': 2116, 'a': 1993, 'in': 1893, 'for': 943, 'The': 806, ...})
>>> cfd['romance']
FreqDist({',': 3899, '.': 3736, 'the': 2758, 'and': 1776, 'to': 1502, 'a': 1335, 'of': 1186, '``': 1045, "''": 1044, 'was': 993, ...})
>>> cfd['romance']['could']
193
Thanks to ConditionalFreqDist().
Tạo văn bản ngẫu nhiên bằng Bigrams.
Ở các bài trước, ta đã biết tới Bigrams, hoạt động như một công cụ để tách từ trong câu hay "Tokenize". Ở bài này, lợi dụng việc Bigrams tạo ra các cặp từ, ta sử dụng nó để tạo ra các đoạn văn bản ngẫu nhiên từ các Corpus có sẵn. Một ví dụ về Bigrams với 1 câu.
>>> sent = ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven', 'and', 'the', 'earth', '.']
>>> list(nltk.bigrams(sent))
[('In', 'the'), ('the', 'beginning'), ('beginning', 'God'), ('God', 'created'), ('created', 'the'), ('the', 'heaven'), ('heaven', 'and'), ('and', 'the'), ('the', 'earth'), ('earth', '.')]
Các từ trong câu đã được tách thành list các cặp từ. Tiếp đến, ta cùng ngó qua đoạn code sẽ tạo ra Ramdom text.
>>> def generate_model(cfdist, word, num=15):
... for i in range(num):
... print(word)
... word = cfdist[word].max()
...
>>> text = nltk.corpus.genesis.words('english-kjv.txt')
>>> bigrams = nltk.bigrams(text)
>>> cfd = nltk.ConditionalFreqDist(bigrams)
>>> generate_model(cfd, 'living')
# Kết quả
living
creature
that
he
said
,
and
the
land
of
the
land
of
the
land
Cùng giải thích qua một chút, lúc mình bắt đầu tìm hiểu tới đây thì cũng khá khó hiểu.
- Bước 1: Lấy văn bản từ Corpus rồi gán vào biến text. Lấy Bigrams của text. Kết quả trả lại sẽ là các cặp từ đứng cạnh nhau như ví dụ trên.
- Bước 2: Lấy Phân phối theo tần suất có điều kiện, tại sao ở đây lại lấy theo dạng phân phối này? Như ta đã biết thì dạng phân phối này sẽ nhận vào 1 list các cặp dữ liệu (điều kiện, biến cố). Vậy khi dùng Bigrams thì điều kiện sẽ tương ứng với 1 từ, và biến cố sẽ là từ đứng ngay cạnh nó trong văn bản. Vậy kết quả của phép phân phối này là gì? Dựa trên kết quả đã được sắp sếp thì đó chính là các từ đứng cạnh từ điều kiện nhiều nhất. Để kiểm chứng, ta thử in ra kết quả với từ "living"
>>> print(dict(cfd['living']))
{'creature': 7, 'thing': 4, 'soul': 1, '.': 1, 'substance': 2, ',': 1}
Kết quả cho thấy từ "creature" xuất hiện tới 7 lần phía sau từ "living".
- Bước 3: Sau khi đã có được 1 đối tượng chứa dữ liệu kết quả của phép phân phối, ta tiến hành lấy các từ ngẫu nhiên bắt đầu bằng từ "living", vòng lặp tới range là 15, tức là lấy ra 15 từ random. Dầu tiên ta in từ "living", tiếp đó vòng lặp sẽ reset biến word về vị trí max của list chứa các từ xuất hiện nhiều với "living". Trong trường hợp này ta có từ "creature", nó chính là từ đầu tiên nằm trong list, ứng với từ có số lần xuất hiện nhiều nhất ngay sau từ "living". Sau đó vòng lặp lại tiếp tục với việc sử dụng từ "creature" như một điều kiện, và lấy từ xuất hiện nhiều nhất ngay phia sau từ "creature" này. Tiếp tục cho tới khi kết thúc vòng lặp và ta có được 1 đoạn văn bản.
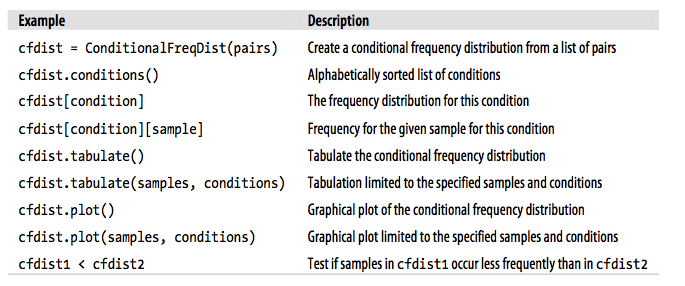
Như vậy, ta đã hoàn thành viện lấy 1 đoạn Random text bằng cách sử dụng Phân phối theo tần suất cho điều kiện và Bigrams. Dưới đây là một bảng cung cấp các thuộc tính, phương thức khi làm việc với đội tượng được sinh ra của hàm ConditionalFreqDist().
 Mình xin kết thúc phần này ở đây, vì có lẽ có nhiều bạn sẽ khá khó hiểu phần tạo Random text bằng Bigrams. Hãy đọc thật kỹ nhé.
Mình xin kết thúc phần này ở đây, vì có lẽ có nhiều bạn sẽ khá khó hiểu phần tạo Random text bằng Bigrams. Hãy đọc thật kỹ nhé.
DEHA AI Lab - Công ty cổ phần DEHA Việt Nam.
All rights reserved
