Xử Lý Ngôn Ngữ Tự Nhiên với Python - P5
Bài đăng này đã không được cập nhật trong 4 năm
Trong phần này, chúng ta sẽ cùng tìm hiểu về khái niệm Corpus/Corpora và cách khai thác chúng từ NLTK. Phần này chúng ta sẽ chỉ đi qua những thông tin cơ bản của Corpus mà thôi, ở những phần sau, ta sẽ đi tìm hiểu sâu hơn về những thứ mà Corpus cung cấp và có giá trị hơn như Part-of-speech tags, dialogue tags hay syntactic trees...
1. Corpus/Corpora là gì?
Hiểu đơn giản là Corpora là các dữ liệu văn bản, ngôn ngữ đã được số hoá. Có thể xem Corpora như một kho ngữ liệu. Corpora thường là các dữ liệu đã được xử lý, được sử dụng như đầu vào của các thuật toán trong NLP. Ví dụ như NLTK Book là một Corpora được cung cấp sẵn. Corpora có rất nhiều đặc tính, tuy nhiên ở khuôn khổ bài viết sẽ không đi vào chi tiết những đặc tính đó. Bạn có thể tham khảo theo đường dẫn phía dưới để hiểu thêm về Corpora/Corpus Khái quát về Corpus Hiểu sâu hơn về Corpus
2. Các Corpora có sẵn của NLTK.
Ở những bài đầu, ta đã khai thác 1 corpora của NLTK là Book. Ở bài viết này, ta sẽ khám phá thêm các Corpora khác mà NLTK cung cấp để đang dạng hoá thông tin trong xử lý ngôn ngữ của chúng ta.
Gutenberg Corpus
Gutenberg là một dự án cung cấp 25.000 cuốn sách điện tử miễn phí, trang Web của nó là https://www.gutenberg.org/. Và NLTK đã lấy 1 phần nhỏ số sách trong dự án này để cung cấp cho chúng ta trong các gói của mình. Để hiển thị các cuốn sách trong dự án Gutenberg mà NLTK cung cấp, chúng ta thực hiện như sau
>>> import nltk
>>> nltk.corpus.gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Hay để ngắn gọn, ta có thể viết
>>> from nltk.corpus import gutenberg
>>> gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', ...] >>> emma = gutenberg.words('austen-emma.txt')
Kết quả hiển thị file chưa các cuốn sách. Bây giờ hãy chọn 1 cuốn sách, và đưa nội dung của nó vào 1 biến trong Python.
>>> emma = nltk.corpus.gutenberg.words('austen-emma.txt')
>>> len(emma)
192427
Cuốn sách có tên Emma, và độ dài của nó là 192.427 ký tự. Sau khi có được Corpus này rồi, hãy sử dụng các kỹ năng ở những bài trước để thử làm các phép toán và thống kê trên Corpus này nhé.
Bài toán: Hãy thống kê trung bình độ dài mỗi từ, trung bình độ dài mỗi câu và trung bình số lần xuất hiện của 1 từ trong tất cả các cuốn sách của Gutenberg mà NLTK cung cấp.
Bước 1: Ta lấy thông tin về tổng độ dài các từ, số từ đơn và số câu Bước 2: Thực hiện tính toán
- Trung bình độ dài mỗi từ = Tổng số ký tự / Tổng số từ.
- Trung bình độ dài mỗi câu = Tổng số từ / Tổng số câu.
- Trung bình lần xuất hiện của mỗi từ = Tổng số từ đơn / Tổng số từ. Ta sẽ có đoạn Code như sau:
from nltk.corpus import gutenberg
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid)) # Tính số lượng ký tự
num_words = len(gutenberg.words(fileid)) # Tính số lượng từ đơn
num_sents = len(gutenberg.sents(fileid)) # Tính số lượng câu.
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)])) # Tính số lượng từ vựng trong văn bản
print(int(num_chars / num_words), int(num_words / num_sents), int(num_words / num_vocab), fileid)
# Kết quả
4 24 26 austen-emma.txt
4 26 16 austen-persuasion.txt
4 28 22 austen-sense.txt
4 33 79 bible-kjv.txt
4 19 5 blake-poems.txt
4 19 14 bryant-stories.txt
4 17 12 burgess-busterbrown.txt
4 20 12 carroll-alice.txt
4 20 11 chesterton-ball.txt
4 22 11 chesterton-brown.txt
4 18 10 chesterton-thursday.txt
4 20 24 edgeworth-parents.txt
4 25 15 melville-moby_dick.txt
4 52 10 milton-paradise.txt
4 11 8 shakespeare-caesar.txt
4 12 7 shakespeare-hamlet.txt
4 12 6 shakespeare-macbeth.txt
4 36 12 whitman-leaves.txt
Lưu ý: gutenberg.raw() không trả lại list các Token (xem lại khái niệm Token ở phần trước), mà trả lại tổng số lượng ký tự, có chứa cả các dấu cách. Hàm gutenberg.sents() sẽ trả lại một list các câu, và mỗi câu thì là một list các từ => Token.
Web và Chat Text Corpus.
Mặc dù Gutenberg cung cấp rất nhiều cuốn sách tuy nhiên nó chỉ cung cấp cho chúng ta các văn bản mang tính trang trọng, các cuốn cách kinh điển. Bây giờ, chúng ta muốn có thêm các văn bản, các đoạn hội thoại trên Web hay mạng xã hội. NLTK cũng cung cấp cho chúng ta các văn bản này. Hãy thử xem các văn bản dạng Web Text, hãy lấy ra tên File và 65 ký tự đầu tiên.
>>> from nltk.corpus import webtext
>>> for fileid in webtext.fileids():
... print fileid, webtext.raw(fileid)[:65]
#Kết quả
firefox.txt Cookie Manager: "Don't allow sites that set removed cookies to se
grail.txt SCENE 1: [wind] [clop clop clop]
KING ARTHUR: Whoa there! [clop
overheard.txt White guy: So, do you have any plans for this evening?
Asian girl
pirates.txt PIRATES OF THE CARRIBEAN: DEAD MAN'S CHEST, by Ted Elliott & Terr
singles.txt 25 SEXY MALE, seeks attrac older single lady, for discreet encoun
wine.txt Lovely delicate, fragrant Rhone wine. Polished leather and strawb
Ngoài ra ta còn có Chat Text nữa, bạn hãy tìm hiểu thêm về nó nhé. Dưới đây là 1 ví dụ về nó.
>>> from nltk.corpus import nps_chat
>>> chatroom = nps_chat.posts('10-19-20s_706posts.xml')
>>> chatroom[123]
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',', 'I', 'can', 'look', 'in', 'a', 'mirror', '.']
Brown Corpus
Đây là Corpus điện tử đầu tiên của tiếng Anh, có từ năm 1961. Nó chứa văn bản từ 500 nguồn và các nguồn thì được chia mục theo thể loại như tin tức, các bài xã luận... Các bạn có thể xem danh sách đầy đủ tại đây http://icame.uib.no/brown/bcm-los.html Bây giờ, hãy cùng khám phá một chút về Brown Corpus. Đầu tiên hãy lấy ra Corpus và thông tin các chuyên mục của nó
>>> from nltk.corpus import brown
>>> brown.categories()
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
Tiếp đến hãy lấy ra các từ thuộc chuyên mục có tên là "news" xem sao
>>> brown.words(categories='news')
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
Lấy ra các câu, từ những chuyên mục khác nhau.
>>> brown.sents(categories=['news', 'editorial', 'reviews'])
[['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'], ['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive', 'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted', '.'], ...]
Brown Corpus là một tài nguyên rất tốt cho việc học ngữ nghĩa giữa các thể loại văn bản, một dạng của ngôn ngữ học có tên là "stylistics". Vậy thì chúng ta hãy làm một thống kê nho nhỏ về cách sử dụng các động từ khuyết thiếu (Modal verb) trong các thể loại văn bản mà Brown Corpus cung cấp nhé. Đầu tiên, ta sẽ có 1 list các Modal verb: modals = ['can', 'could', 'may', 'might', 'must', 'will'].
>>> import nltk
>>> from nltk.corpus import brown
>>> cfd = nltk.ConditionalFreqDist((genre, word) for genre in brown.categories() for word in brown.words(categories=genre))
>>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> print(cfd.tabulate(conditions=genres, samples=modals))
# Kết quả
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
Ở đây, tôi có sử dụng một hàm là ConditionalFreqDist, chúng ta sẽ tìm hiểu nó sau, tạm thời ta sử dụng nó để biết được việc sử dụng các Model verb trong từng loại văn bản như thế nào.
Reuters Corpus
Corpus nay chứa hơn 10 ngàn tin tức và 1.3 triệu từ. Nó được chưa thành 90 chủ đề và được chưa làm 2 tập là "training" và "test". Lý do chia như vậy là để phục vụ cho việc sử dụng Học Máy - tương lai tối sẽ viết về vấn đề này sau. Các tài liệu sẽ được đánh dấu dạng "training/1234" hay "test/1234".
>>> from nltk.corpus import reuters
>>> reuters.fileids()
Ta cũng có thể xem các chuyên mục mà Reutuers cung cấp
>>> reuters.categories()
Tuy nhiên khi xem chuyên mục của 1 tài liệu, ví dụ
>>> reuters.categories('training/9865')
['barley', 'corn', 'grain', 'wheat']
Ta thấy 1 tài liệu có thể thuộc nhiều chuyên mục khác nhau. Và cũng tương tự như các Corpus khác, ta có thể truy cập và xử lý các từ và câu.
Annotated Text Corpus
Các Corpus được đánh dấu, NLTK cung cấp rất nhiều các Corpus đã được đánh dấu thể hiện như POP Tags, name entities, syntactic structures... Nếu bạn đã có kiến thức cơ bản về NLP rồi thì có thể truy cập luôn vào những tài nguyên này. Thông tin thêm được lưu tại http://www.nltk.org/data
3. Cấu trúc của một Corpus.
Dưới đây là một số dạng của Corpus và tương ứng với Corpus trong NLTK
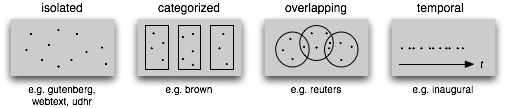 Một số hàm được sử dụng để làm việc với các Corpus của NLTK
Một số hàm được sử dụng để làm việc với các Corpus của NLTK

Bài tập: Hãy sử dụng PlaintextCorpusReader của NLTK để đưa một văn bản của bạn thành Corpus.
Ở phần sau, chúng ta sẽ đi vào xử lý các Corpus này với một số phương pháp thường xử dụng.
DEHA AI Lab - Công ty cổ phần DEHA Việt Nam.
All rights reserved
