Xây dựng chatbot Messenger cập nhật thời khóa biểu cho sinh viên (Phần 1) - Phân tích thiết kế hệ thống
Bài đăng này đã không được cập nhật trong 4 năm
1. Tổng quan

-
Giới thiệu
Tìm hiểu về Rasa, về chatbot, NLP, ... cũng một thời gian rồi, mình nghĩ nên có một project gì đó để tự tổng hợp lại kiến thức của bản thân, cũng như để kiểm tra xem bản thân đã thực sự áp dụng được chatbot vào các vấn đề cần thiết ==> Mình có loạt bài viết này để chia sẻ lại quá trình bản thân tự lên ý tưởng, phân tích thiết kế và xây dựng chatbot hoàn chỉnh từ A-Z. Hi vọng có thể giúp thêm cho các bạn mới làm quen như mình.
Quá trình xây dựng một chatbot hoàn chỉnh:
- Thu thập dữ liệu (Đương nhiên rồi)
- Thiết kế hệ thống, phân tích luồng xử lí (các chức năng của bot, các case có thể xảy ra, ...)
- Lựa chọn nền tảng chat (messenger, zalo, discord, ...)
- Xây dựng chatbot
- Deploy server
Hãy tìm hiểu kĩ hơn về các bước này qua quá trình xây dựng chatbot của mình nào
-
Mục tiêu
Như tiêu đề bài viết thì các bạn có thể thấy rồi, mục tiêu của chúng ta sẽ là xây dựng chatbot giúp cập nhật thời khóa biểu cho sinh viên.
Lí do mình chọn chatbot về vấn đề này thì khá đơn giản thôi: Sau khoảng thời gian nghỉ Tết dài thế kỉ do sự xuất hiện của COVID19, học sinh, sinh viên đã bắt đầu quay trở lại với trường học và bị hành sấp mặt với bài tập về nhà, với deadline dí bù lại cho khoảng thời gian "sống chậm ". Mặc dù không đến nỗi sinh viên không nhớ nổi đường đến trường do nghỉ quá lâu, nhưng việc sinh viên không nhớ nổi thông tin lịch học, phòng học lại là điều hoàn toàn có thể. Điều đó dẫn đến sự ra đời của Sunny: Chatbot giúp cập nhật thời khóa biểu cho sinh viên (Quả intro này đem quảng cáo ổn phết  )
)
Oke, vậy trước tiên, muốn hỗ trợ thông tin về lịch học thì chúng ta cần biết lịch học của từng sinh viên. Đây là bước 1 trong quá trình xây dựng chatbot mà mình nêu ở trên. Khá may mắn, sau một hồi mày mò khắp các trang thông tin của trường mình thì mình nhận ra rằng mình hoàn toàn có thể lấy được thông tin về lịch học của một sinh viên nếu biết được mã số sinh viên (MSSV) của sinh viên đó bằng cách crawl thông tin của website trường (mình sẽ nói cụ thể hơn trong các phần sau).
Tiếp theo, chúng ta lên ý tưởng về các chức năng cho chatbot. Chào hỏi cơ bản - tất nhiên rồi, bên cạnh đó sẽ là một vài chức năng khen chê, chat for fun, ... và 2 chức năng quan trọng nhất : Đưa ra thông tin về lịch học trong một thời gian bất kì nếu sinh viên hỏi về lịch học, và đưa ra thông tin chi tiết về môn học nếu sinh viên hỏi về học phần (Tạm đơn giản vậy rồi chúng ta sẽ mở rộng sau)
Nền tảng chat chúng ta sẽ chọn ở đây là Facebook Messenger, lí do thì chắc các bạn cũng biết rồi, nguồn tiếp cận sinh viên tốt nhất
Các vấn đề còn lại liên quan đến code xây dựng chatbot thì mình sẽ sử dụng Rasa và deploy thì chúng ta sẽ tiến hành deploy lên Heroku nếu các bạn cần một server free để conbot của mình hoạt động 24/24
2. Web Crawler
-
Khảo sát
Trước tiên, hãy làm một vài khảo sát trên các website của trường mà ở đó mình có thể tìm thấy thời khóa biểu :
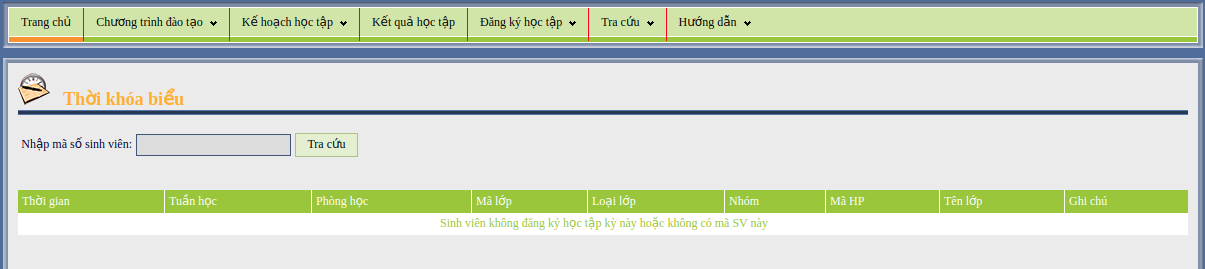
Khá nhiều trang thông tin, nhưng chỉ có một vài trang thông tin có thời khóa biểu, đặc biệt ở đây, một trang thông tin chính của trường cho phép sinh viên xem thời khóa biểu mà không cần đăng nhập hệ thống. Greate! xem thử chúng ta có thể lấy dữ liệu về thời khóa biểu được không nào ... (F12 thôi)
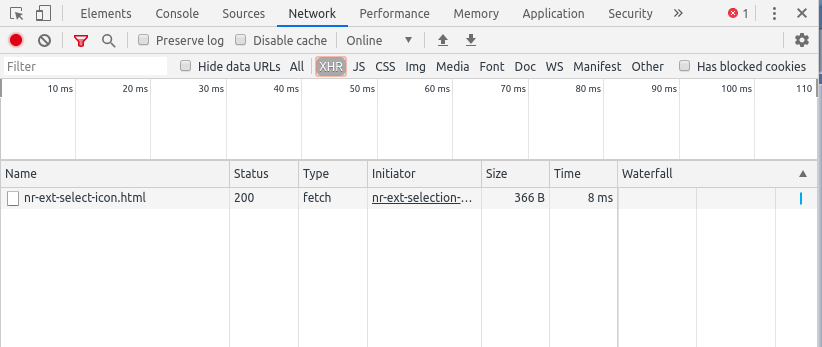
Tuy nhiên, khá đen là ở đây không có bất kì thông tin về API nào được sử dụng. Vậy là sau khi gửi request đến server thì server đã trực tiếp render ra một trang html. Vậy nên chúng ta sẽ thực hiện cách trâu bò nhất : CÀO html
Trước khi bắt đầu tiến hành crawl, việc chúng ta cần check thông tin cần thiết của request (về header, formdata, ...)
 Ở đây, chúng ta sẽ sử dụng Charles để tiến hành theo dõi network_traffic khi truy nhập vào web trên. (Các bạn có thể đọc thêm thông tin về cách cài đặt và sử dụng Charles tại đây).
Ở đây, chúng ta sẽ sử dụng Charles để tiến hành theo dõi network_traffic khi truy nhập vào web trên. (Các bạn có thể đọc thêm thông tin về cách cài đặt và sử dụng Charles tại đây).
Gửi request đến server cùng với thông tin về MSSV, sau đó, check thông tin trong phần formdata
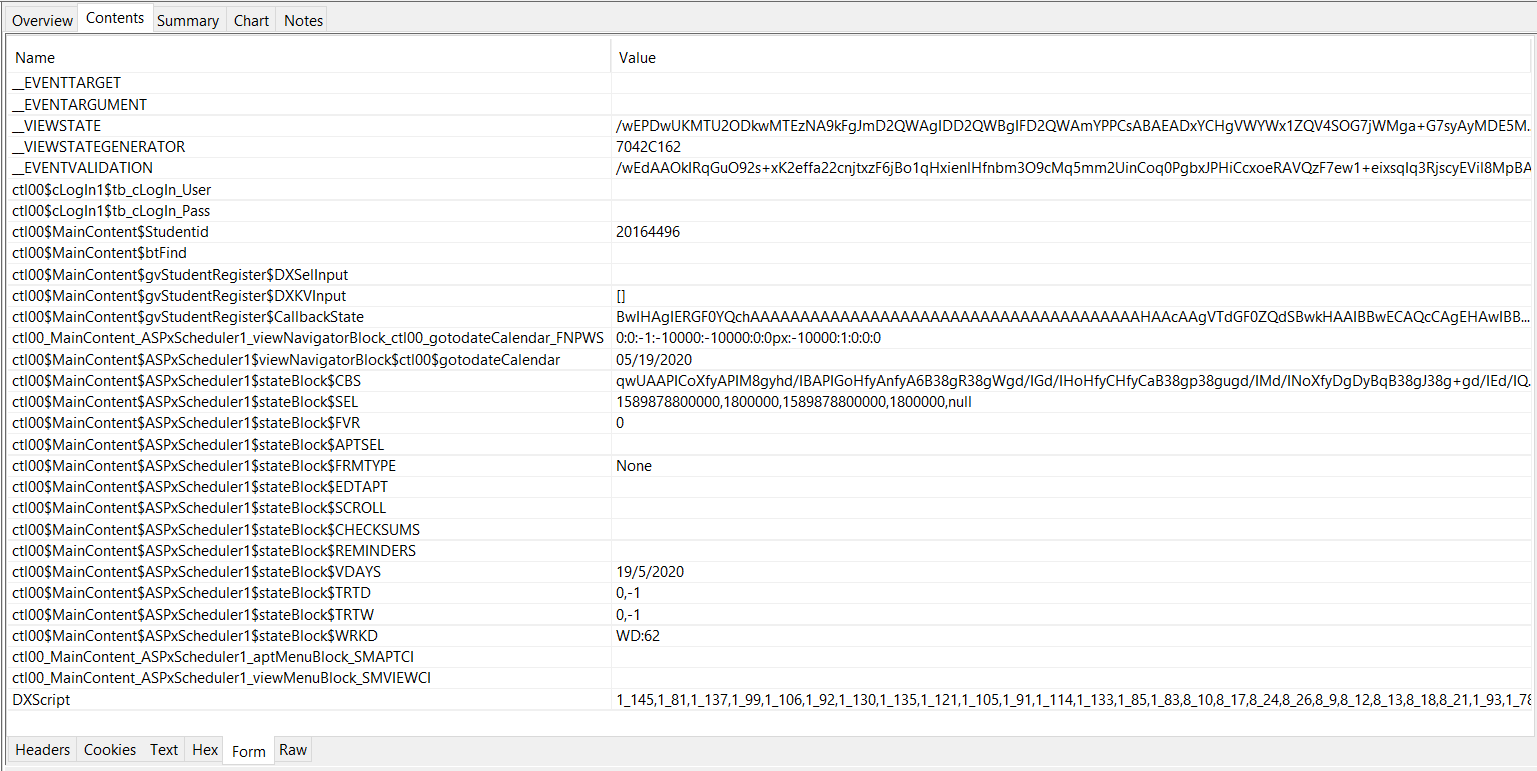
Phía trên là các thông tin mà formdata lưu trữ để gửi đến server, lấy thông tin về lịch học. Về mặt lí thuyết, nếu các bạn không biết các trường thông tin nào là thực sự cần thiết, trường thông tin nào là có thể bỏ đi, thì các bạn sẽ cần tạo 1 request với header và formdata dài ngoằng như này để chắc chắn là request thành công. Tuy nhiên, Charles khá hay với chức năng Compose khi cho phép chúng ta thử thay thế các trường thông tin này và sau khi check, chúng ta chỉ cần một form data với 3 trường thông tin chính :
'__EVENTTARGET': ,
'ctl00$MainContent$Studentid': MSSV,
'ctl00$MainContent$btFind':
Code để gửi request nào :
class ScheduleCrawler():
def __init__(self, student_code):
self.student_code = student_code
self.url = "http://sis.hust.edu.vn/ModulePlans/Timetables.aspx"
self.form = {
'__EVENTTARGET':'',
'ctl00$MainContent$Studentid': '{}'.format(self.student_code),
'ctl00$MainContent$btFind':''
}
Và chúng ta sẽ nhận được respone là file html dài ngoằng, công việc kế tiếp là "cào" file html này để trích xuất thông tin
-
Các công cụ hỗ trợ web scraping
Hiện nay, với python, chúng ta có vô vàn thư viện hỗ trợ tác vụ "Cào" html, có thể kể đến một số thư viện như sau:
1. lxml
 Lxml là một thư viện giúp parse html và trả về dữ liệu có tốc độ nhanh nhất do sử dụng tính chất search theo cây (Element tree). Do đó, nó đặc biệt tỏ ra mạnh mẽ đối với các file lớn và có cấu trúc.
Lxml là một thư viện giúp parse html và trả về dữ liệu có tốc độ nhanh nhất do sử dụng tính chất search theo cây (Element tree). Do đó, nó đặc biệt tỏ ra mạnh mẽ đối với các file lớn và có cấu trúc.
-
Ưu điểm :
- Nhanh
- Đơn giản
- Sử dụng Element tree
-
Nhược điểm :
- Do sử dụng search theo tree, nên đối với các file html viết không theo cấu trúc, lxml tỏ ra hơi bất lực
- Docs của lxml cũng khá là khó đọc
2. Beautiful Soup
 Mặc dù lxml là thư viện nhanh nhất, tuy nhiên Beautiful Soup mới là thư viện được ưa chuộng và sử dụng rộng rãi nhất (Có thể các bạn cũng nghe về Beautiful Soup khá nhiều rồi )
Mặc dù lxml là thư viện nhanh nhất, tuy nhiên Beautiful Soup mới là thư viện được ưa chuộng và sử dụng rộng rãi nhất (Có thể các bạn cũng nghe về Beautiful Soup khá nhiều rồi )
- Ưu điểm :
- Code ngắn, (chắc các bạn cũng đọc nhiều bài title kiểu như : Crawl web đơn giản với 5 dòng code hoặc đại loại vậy)
- Đơn giản, cực kì dễ tìm hiểu với người mới bắt đầu
- Docs dễ hiểu, dễ đọc
- Tự động encode lại đầu ra (Do nhiều file html đã bị mã hóa, việc tự động encode lại Beautiful là cực kì tiện lợi)
- Kết hợp được với cả lxml
- Xử lí được với cả các file html có cấu trúc tệ
- Nhược điểm :
- Chậm (chậm hơn lxml
 )
)
- Chậm (chậm hơn lxml
3. More ...
Ngoài ra còn một số thư viện khác được sinh ra với mục đích chính còn phức tạp và chuyên sâu hơn công việc "Cào" web, có thể kể đến như Scrapy, Selenium. Các bạn có thể đọc thêm về thông tin tổng quát về Web scraping với python tại đây
-
Scrap website lấy dữ liệu với lxml
Vì Beautiful Soup khá dễ học và đã có rất nhiều bài viết về cả lí thuyết lẫn ví dụ với thư viện này rồi, nên trong bài viết này, mình sẽ sử dụng lxml, coi như một ví dụ cho việc sử dụng lxml giúp các bạn dễ hiểu hơn. Đọc thử file html xem table chứa thông tin lịch học nằm ở thẻ nào trong file. Chúng ta có thể thấy :
<table id="MainContent_gvStudentRegister_DXMainTable" class="dxgvTable_SisTheme" cellspacing="0" cellpadding="0" onclick="aspxGVTableClick('MainContent_gvStudentRegister', event);" style="width:100%;border-collapse:collapse;empty-cells:show;">
 Ok, bắt đầu nào :
Ok, bắt đầu nào :
def get_schedule(self):
page = requests.post(self.url, data = self.form)
if page.status_code == 200:
try:
doc = lh.fromstring(page.text)
table_elements = doc.xpath('//table[@id="MainContent_gvStudentRegister_DXMainTable"]')[0]
td_elements = table_elements.xpath('.//tr[@class="dxgvDataRow_SisTheme"]')
Phần tử doc = lh.lh.fromstring(page.text) là một object được khởi tạo với loại dữ liệu là html. Đặc biệt object này có một method "xpath" là công cụ chính giúp chúng ta xác định vị trí của từng thẻ html
Tiến hành sử dụng xpath nào >
- Thẻ là thẻ table
- id là MainContent_gvStudentRegister_DXMainTable
- class là dxgvTable_SisTheme Chúng ta sẽ lấy ra phần tử table này
table_elements = doc.xpath('//table[@id="MainContent_gvStudentRegister_DXMainTable"]')[0]
Tiếp đến. trong phần tử table, ta sẽ lấy ra list các thẻ chứa thông tin về lịch học
td_elements = table_elements.xpath('.//tr[@class="dxgvDataRow_SisTheme"]')
Chú ý : "//" là quét toàn bộ file html , còn ".//" là quét trong phần tử cha.
Sau đó là lọc thông tin text trong từng thẻ bằng text_content()
for tr in td_elements:
if tr[0].text_content().strip():
day_of_week = tr[0].text_content().split(',')[0].strip()
date_time = tr[0].text_content().split(',')[1].strip()
else:
day_of_week = ""
date_time = ""
weeks = tr[1].text_content().strip()
classroom = tr[2].text_content().strip()
class_code = tr[3].text_content().strip()
class_type = tr[4].text_content().strip()
group = tr[5].text_content().strip()
subject_code = tr[6].text_content().strip()
subject_name = tr[7].text_content().strip()
note = tr[8].text_content().strip()
Save lại vào một dictionary:
subject = {
'day_of_week': int(day_of_week.split(' ')[1].strip()) if day_of_week else "",
'date_time': {
'start_time' : date_time.split('-')[0].strip() if date_time else "",
'end_time' : date_time.split('-')[1].strip() if date_time else ""
},
'week': self.get_list_week(weeks=weeks),
'subject_code': subject_code,
'class_code': class_code,
'class_type': class_type,
'classroom': classroom
}
subject_schedule[subject_name] = subject
all_weeks += subject["week"]
schedule = {
'subject_schedule' : subject_schedule,
'week_now' : week_now,
'start_week' : min(all_weeks),
'end_week' : max(all_weeks)
}
Xem thử kết quả nào :
 Oke, vậy là chúng ta đã có data cho chatbot, đến phần xây dựng hệ thống nào !!!!!
Oke, vậy là chúng ta đã có data cho chatbot, đến phần xây dựng hệ thống nào !!!!!
3. Phân tích thiết kế hệ thống
Bất kì một hệ thống nào (kể cả chatbot). để việc tiến hành xây dựng có thể triển khai một cách trơn tru nhất và đảm bảo mọi thứ theo đúng spec và tiến độ định ra, chúng ta cần xây dựng các biểu đồ phân cấp để mô tả rõ luồng xử lí dữ liệu. Về lí thuyết phần phân tích thiết kế hệ thống này, mình sẽ không chia sẻ thêm nhiều, vì nó là một phần cơ bản trong học phần cơ sở dữ liệu rồi. Vậy nên, chúng ta sẽ quan sát các biểu đồ dưới đây để hiểu rõ hơn về những công đoạn cần thực hiện tiếp theo
-
Biểu đồ phân cấp chức năng
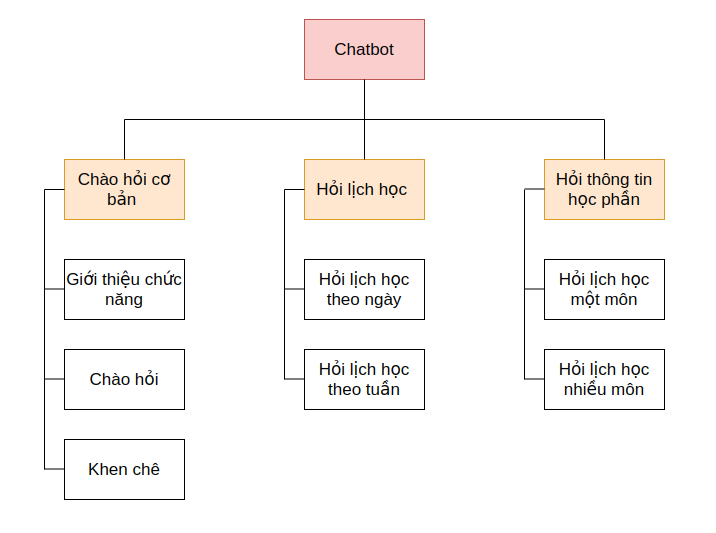
-
Biểu đồ luồng dữ liệu
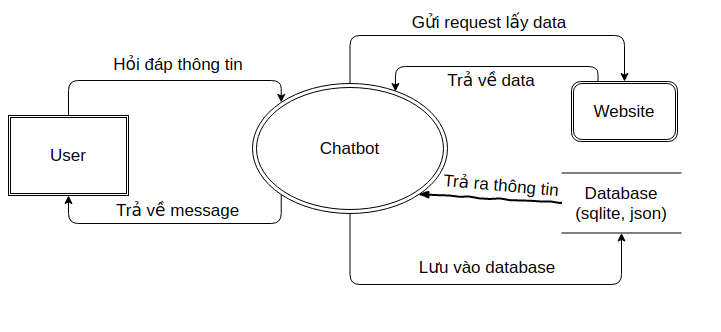
-
Thiết kế cơ sở dữ liệu
Về cơ sở dữ liệu, vì dữ liệu chủ yếu là craw từ trang web, thế nên database chúng ta thiết kế sẽ chỉ dùng để lưu một thông tin duy nhất : Mã số sinh viên của từng user (lí do thì chắc các bạn cũng biết rồi, không có sinh viên nào muốn cứ mỗi lần hỏi gì lại báo lại mã số sinh viên của mình cả, thế nên chúng ta cần lưu lại cho những lần hỏi sau)
 Một database nữa là cho thông tin về thời khóa biểu , chúng ta cần đảm bảo một số vấn đề sau:
Một database nữa là cho thông tin về thời khóa biểu , chúng ta cần đảm bảo một số vấn đề sau:
- Cần lưu lại thời khóa biểu vì không thể cứ mỗi lần có sinh viên hỏi, chúng ta lại gửi request lấy data
- Lưu lại nhưng chỉ lưu lại tạm thời, vì thời khóa biểu là thay đổi chứ không cố định
Các bạn có thể thử nghĩ xem chúng ta nên xử lí như nào ổn thoả nhất (và comment dưới bài viết này )
4. Tạm kết
Bài cũng khá dài rồi nên mình sẽ tạm kết ở đây.
Hi vọng bài viết này đã giúp các bạn hình dung được quá trình để bắt đầu xây dựng một chatbot hoàn chỉnh, một chút kiến thức về thu thập dữ liệu và thiết kế hệ thống. Mình sẽ hoàn thành sớm các phần tiếp theo nhanh nhất có thể, hi vọng các bạn sẽ đồng hành cùng mình
See ya 
Phần tiếp theo: Xây dựng chatbot Messenger cập nhật thời khóa biểu cho sinh viên (Phần 2) - Chatbot đơn giản và kết nối messenger
All rights reserved
