Tìm hiểu về hog(histogram of oriented gradients)
Bài đăng này đã không được cập nhật trong 4 năm
HOG(histogram of oriented gradients) là một feature descriptor được sử dụng trong computer vision và xử lý hình ảnh, dùng để detec một đối tượng. Các khái niệm về HOG được nêu ra từ năm 1986 tuy nhiên cho đến năm 2005 HOG mới được sử dụng rộng rãi sau khi Navneet Dalal và Bill Triggs công bố những bổ sung về HOG. Hog tương tự như các biểu đồ edge orientation, scale-invariant feature transform descriptors(như sift, surf,..), shape contexts nhưnghog được tính toán trên một lưới dày đặc các cell và chuẩn hóa sự tương phản giữa các block để nâng cao độ chính xác. Hog được sử dụng chủ yếu để mô tả hình dạng và sự xuất hiện của một object trong ảnh Bài toán tính toán Hog thường gồm 5 bước:
- Chuẩn hóa hình ảnh trước khi xử lý
- Tính toán gradient theo cả hướng x và y .
- Lấy phiếu bầu cùng trọng số trong các cell
- Chuẩn hóa các block
- Thu thập tất cả các biểu đồ cường độ gradient định hướng để tạo ra feature vector cuối cùng.
1. Chuẩn hóa hình ảnh trước khi xử lý
Bước chuẩn hóa này hoàn toàn không bắt buộc, nhưng trong một số trường hợp, bước này có thể cải thiện hiệu suất của bộ mô tả HOG. Có ba phương pháp chuẩn hóa chính mà chúng ta có thể xem xét:
- Quy định về chuẩn Gamma /power : Trong trường hợp này, ta lấy $ \log(p) $ của mỗi pixel p trong hình ảnh đầu vào.
- Chuẩn hoá gốc-vuông: Ở đây chúng ta lấy $ \sqrt(p) $ của mỗi pixel p trong hình ảnh đầu vào. Theo định nghĩa, sự bình thường của các căn bậc hai nén các cường độ điểm ảnh đầu vào thấp hơn nhiều so với chuẩn bình thường của gamma.
- Variance normalization: Ở đây, chúng ta tính cần giá trị cường độ điểm ảnh trung bình $\mu $ và độ lệch tiêu chuẩn $\sigma $ của hình ảnh đầu vào. Với mỗi điểm ảnh ta trừ đi giá trị trung bình của cường độ điểm ảnh và sau đó được chuẩn hóa bằng cách chia cho độ lệch chuẩn: $ p' = (p - \mu) / \sigma $
2.Tính toán gradient
Để lấy được hình ảnh gradient, chúng ta sẽ sử dụng tích chập(convolution): $ G_{x} = I \star D_{x}$ và $G_{y} = I \star D_{y} $ với I là hình ảnh đầu vào, $ D_{x} $ làà bộ lọc cho chiều x, và $ D_{y} $ là bộ lọc cho chiều y .
Sau khi có các ảnh gradient, chúng ta có thể tính toán cường độ gradient của hình ảnh:
Cuối cùng, định hướng của gradient cho mỗi pixel trong hình ảnh ban đầu được tính bằng cách:
Dự vào $|G|4 Và , chúng ta có thể tính được một biểu đồ cường độ gradient, trong đó cột của histogram dựa trên và trọng số của mỗi cột của biểu đồ được dựa trên .
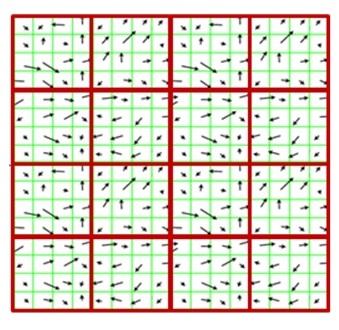
3.Lấy votes trong mỗi cell
Bây giờ chúng ta cần chia hình ảnh của chúng ta thành các cell và block
Một cell là một vùng hình chữ nhật được xác định bởi số điểm ảnh thuộc mỗi cell. Ví dụ: nếu ta có một hình ảnh 128 x 128 với pixel_per_cell = 4 x 4 thì sẽ có 32 x 32 = 1024 cell, pixel_per_cell = 32 x 32, sẽ có 4 x 4 = 16 cell.
Với mỗi cell trong bức ảnh, ta cần xây dựng 1 biểu đồ cường độ gradient. Mỗi pixcel sẽ được vote vào vào biểu đồ, trọng số của mỗi vote chính là cường độ gradient tại pixel đó
Cuối cùng, mỗi pixel đóng góp một phiếu bầu có trọng số vào biểu đồ - trọng lượng của phiếu chỉ đơn giản là cường độ gradient |G| tại pixel đó.Lúc này, chúng ta có thể thu thập và ghép các biểu đồ này để tạo ra feature vector cuối cùng. Tuy nhiên, ta sẽ chuẩn hóa các block để có được kết quả tốt hơn
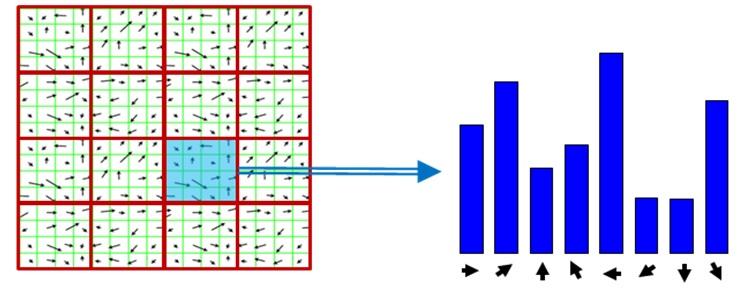
4.Chuẩn hóa các block
Một lần nữa, ta cần chia các block giống như chia cell ở phía trên. Đơn vị của ta không còn là các điểm ảnh nữa mà là các cell. Người ta thường sử dụng hoặc 2 x 2 hoặc 3 x 3 cell_per_block có được độ chính xác hợp lý trong hầu hết các trường hợp.Các block này sẽ chồng lên nhau. Ví du: ta có 3x3 cells và cell_per_block= 2x2 thì ta sẽ có 4 block. Tiếp đến, ta sẽ tiến hành thu thập và ghép các histogram của cell trong block.
5. Sử dụng trong bài toán object recognition
HOG được implement trong opencv và scikit-image. Tuy nhiên, việc sử dụng HOG trong scikit-image linh hoạt hơn rất nhiều trong opencv Bài toán mình đặt ra là, trong một bức ảnh có nhiều chữ số có kích thước khác nhau, làm thế nào để xác định được các chữ số đó Đầu tiền, mình sử dụng opencv2 để load ảnh, resize và chuyển ảnh sang màu graysacle
image = cv2.imread(image_path)
image_gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(image_gray,127,255,0)
Sau đó lấy ra các hình chữ nhật viền xung quanh các ký tự
kernel = np.ones((5,5),np.uint8)
thresh = cv2.erode(thresh,kernel,iterations = 1)
thresh = cv2.dilate(thresh,kernel,iterations = 1)
thresh = cv2.erode(thresh,kernel,iterations = 1)
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_CCOMP,cv2.CHAIN_APPROX_SIMPLE)
digit_rects = [cv2.boundingRect(ctr) for ctr in contours]
rects_final = digit_rects[:]
for r in digit_rects:
x,y,w,h = r
if w < 15 and h < 15: #too small, remove it
rects_final.remove(r)
for r1 in digit_rects:
for r2 in digit_rects:
if (r1[1] != 1 and r1[1] != 1) and (r2[1] != 1 and r2[1] != 1): #if the rectangle is not the page-bounding rectangle,
if contains(r1,r2) and (r2 in rects_final):
rects_final.remove(r2)
Ta sẽ tìm hog feature trên mỗi mảng điểm ảnh của lý tự được lấy ra
hog_featuresData = []
for img in pixel_array:
fd = hog(img, orientations=9, pixels_per_cell=(10,10),cells_per_block=(1,1), visualise=False)
hog_featuresData.append(fd)
hog_features = np.array(hog_featuresData, 'float64')
return np.float32(hog_features)
Cuối cùng ta xây dựng một model KNN
class KNN_MODEL():
def __init__(self, k = 3):
self.k = k
self.model = cv2.KNearest()
def train(self, samples, responses):
self.model = cv2.KNearest()
self.model.train(samples, responses)
def predict(self, samples):
retval, results, neigh_resp, dists = self.model.find_nearest(samples, self.k)
return results.ravel()
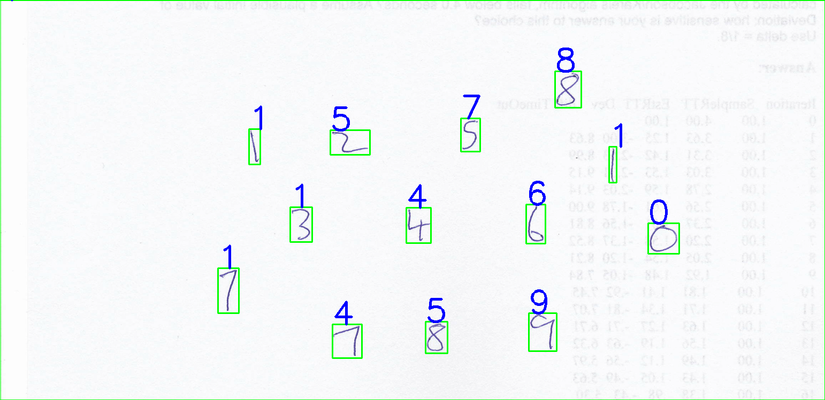
Sử dụng hog feature này làm đầu vào cho model KNN đã được tranning, mình thu được kết quả như sau:
All rights reserved
